Введение 8
Целевая аудитория 10
Глава 1. Основные понятия 15
Что такое алгоритмы? 15
Анализ скорости выполнения алгоритмов 16
Пространство — время 17
Оценка с точностью до порядка 17
Поиск сложных частей алгоритма 19
Сложность рекурсивных алгоритмов 20
Многократная рекурсия 21
Косвенная рекурсия 22
Требования рекурсивных алгоритмов к объему памяти 22
Наихудший и усредненный случай 23
Часто встречающиеся функции оценки порядка сложности 24
Логарифмы 25
Реальные условия — насколько быстро? 25
Обращение к файлу подкачки 26
Псевдоуказатели, ссылки на объекты и коллекции 27
Резюме 29
Глава 2. Списки 30
Знакомство со списками 31
Простые списки 31
Коллекции 32
Список переменного размера 33
Класс SimpleList 36
Неупорядоченные списки 37
Связные списки 41
Добавление элементов к связному списку 43
Удаление элементов из связного списка 44
Уничтожение связного списка 44
Сигнальные метки 45
Инкапсуляция связных списков 46
Доступ к ячейкам 47
Разновидности связных списков 49
Циклические связные списки 49
Проблема циклических ссылок 50
Двусвязные списки 50
Потоки 53
Другие связные структуры 56
Псевдоуказатели 56
Резюме 59
Глава 3. Стеки и очереди 60
Стеки 60
Множественные стеки 62
Очереди 63
Циклические очереди 65
Очереди на основе связных списков 69
Применение коллекций в качестве очередей 70
Приоритетные очереди 70
Многопоточные очереди 72
Резюме 74
Глава 4. Массивы 75
Треугольные массивы 75
Диагональные элементы 77
Нерегулярные массивы 78
Прямая звезда 78
Нерегулярные связные списки 79
Разреженные массивы 80
Индексирование массива 82
Очень разреженные массивы 85
Резюме 86
Глава 5. Рекурсия 86
Что такое рекурсия? 87
Рекурсивное вычисление факториалов 88
Анализ времени выполнения программы 89
Рекурсивное вычисление наибольшего общего делителя 90
Анализ времени выполнения программы 91
Рекурсивное вычисление чисел Фибоначчи 92
Анализ времени выполнения программы 93
Рекурсивное построение кривых Гильберта 94
Анализ времени выполнения программы 96
Рекурсивное построение кривых Серпинского 98
Анализ времени выполнения программы 100
Опасности рекурсии 101
Бесконечная рекурсия 101
Потери памяти 102
Необоснованное применение рекурсии 103
Когда нужно использовать рекурсию 104
Хвостовая рекурсия 105
Нерекурсивное вычисление чисел Фибоначчи 107
Устранение рекурсии в общем случае 110
Нерекурсивное построение кривых Гильберта 114
Нерекурсивное построение кривых Серпинского 117
Резюме 121
Глава 6. Деревья 121
Определения 122
Представления деревьев 123
Полные узлы 123
Списки потомков 124
Представление нумерацией связей 126
Полные деревья 129
Обход дерева 130
Упорядоченные деревья 135
Добавление элементов 135
Удаление элементов 136
Обход упорядоченных деревьев 139
Деревья со ссылками 141
Работа с деревьями со ссылками 144
Квадродеревья 145
Изменение MAX_PER_NODE 151
Использование псевдоуказателей в квадродеревьях 151
Восьмеричные деревья 152
Резюме 152
Глава 7. Сбалансированные деревья 153
Сбалансированность дерева 153
АВЛ-деревья 154
Удаление узла из АВЛ-дерева 161
Б-деревья 166
Производительность Б-деревьев 167
Вставка элементов в Б-дерево 167
Удаление элементов из Б-дерева 168
Разновидности Б-деревьев 169
Улучшение производительности Б-деревьев 171
Балансировка для устранения разбиения блоков 171
Вопросы, связанные с обращением к диску 173
База данных на основе Б+дерева 176
Резюме 179
Глава 8. Деревья решений 179
Поиск в деревьях игры 180
Минимаксный поиск 181
Улучшение поиска в дереве игры 185
Поиск в других деревьях решений 187
Метод ветвей и границ 187
Эвристики 191
Другие сложные задачи 207
Задача о выполнимости 207
Задача о разбиении 208
Задача поиска Гамильтонова пути 209
Задача коммивояжера 210
Задача о пожарных депо 211
Краткая характеристика сложных задач 212
Резюме 212
Глава 9. Сортировка 213
Общие соображения 213
Таблицы указателей 213
Объединение и сжатие ключей 215
Примеры программ 217
Сортировка выбором 219
Рандомизация 220
Сортировка вставкой 221
Вставка в связных списках 222
Пузырьковая сортировка 224
Быстрая сортировка 227
Сортировка слиянием 232
Пирамидальная сортировка 234
Пирамиды 235
Приоритетные очереди 237
Алгоритм пирамидальной сортировки 240
Сортировка подсчетом 241
Блочная сортировка 242
Блочная сортировка с применением связного списка 243
Блочная сортировка на основе массива 245
Резюме 248
Глава 10. Поиск 248
Примеры программ 249
Поиск методом полного перебора 249
Поиск в упорядоченных списках 250
Поиск в связных списках 251
Двоичный поиск 253
Интерполяционный поиск 255
Строковые данные 259
Следящий поиск 260
Интерполяционный следящий поиск 261
Резюме 262
Глава 11. Хеширование 263
Связывание 265
Преимущества и недостатки связывания 266
Блоки 268
Хранение хеш-таблиц на диске 270
Связывание блоков 274
Удаление элементов 275
Преимущества и недостатки применения блоков 277
Открытая адресация 277
Линейная проверка 278
Квадратичная проверка 284
Псевдослучайная проверка 286
Удаление элементов 289
Резюме 291
Глава 12. Сетевые алгоритмы 292
Определения 292
Представления сети 293
Оперирование узлами и связями 295
Обходы сети 296
Наименьшие остовные деревья 298
Кратчайший маршрут 302
Установка меток 304
Коррекция меток 308
Другие задачи поиска кратчайшего маршрута 311
Применения метода поиска кратчайшего маршрута 316
Максимальный поток 319
Приложения максимального потока 325
Резюме 327
Глава 13. Объектно-ориентированные методы 327
Преимущества ООП 328
Инкапсуляция 328
Полиморфизм 330
Наследование и повторное использование 333
Парадигмы ООП 335
Управляющие объекты 335
Контролирующий объект 336
Итератор 337
Дружественный класс 338
Интерфейс 340
Фасад 340
Порождающий объект 340
Единственный объект 341
Преобразование в последовательную форму 341
Парадигма Модель/Вид/Контроллер. 344
Резюме 346
Требования к аппаратному обеспечению 346
Выполнение программ примеров 346
programmer@newmail.ru
Далее следует «текст», который любой уважающий себя программист должен прочесть хотя бы один раз. (Это наше субъективное мнение)
Введение
Программирование под Windows всегда было нелегкой задачей. Интерфейс
прикладного программирования (Application Programming Interface) Windows
предоставляет в распоряжение программиста набор мощных, но не всегда
безопасных инструментов для разработки приложений. Можно сравнить его с
бульдозером, при помощи которого удается добиться поразительных
результатов, но без соответствующих навыков и осторожности, скорее всего,
дело закончится только разрушениями и убытками.
Эта картина изменилась с появлением Visual Basic. Используя визуальный
интерфейс, Visual Basic позволяет быстро и легко разрабатывать законченные
приложения. При помощи Visual Basic можно разрабатывать и тестировать
сложные приложения без прямого использования функций API. Избавляя
программиста от проблем с API, Visual Basic позволяет сконцентрироваться на
деталях приложения.
Хотя Visual Basic и облегчает разработку пользовательского интерфейса,
задача написания кода для реакции на входные воздействия, обработки их, и
представления результатов ложится на плечи программиста. Здесь начинается
применение алгоритмов.
Алгоритмы представляют собой формальные инструкции для выполнения сложных
задач на компьютере. Например, алгоритм сортировки может определять, как
найти конкретную запись в базе из 10 миллионов записей. В зависимости от
класса используемых алгоритмов искомые данные могут быть найдены за
секунды, часы или вообще не найдены.
В этом материале обсуждаются алгоритмы на Visual Basic и содержится большое
число мощных алгоритмов, полностью написанных на этом языке. В ней также
анализируются методы обращения со структурами данных, такими, как списки,
стеки, очереди и деревья, и алгоритмы для выполнения типичных задач, таких
как сортировка, поиск и хэширование.
Для того чтобы успешно применять эти алгоритмы, недостаточно их просто
скопировать в свою программу. Необходимо кроме этого понимать, как
различные алгоритмы ведут себя в разных ситуациях, что в конечном итоге и
будет определять выбор наиболее подходящего алгоритма.
В этом материале поведение алгоритмов в типичном и наихудшем случаях
описано доступным языком. Это позволит понять, чего вы вправе ожидать от
того или иного алгоритма и распознать, в каких условиях встречается
наихудший случай, и в соответствии с этим переписать или поменять алгоритм.
Даже самый лучший алгоритм не поможет в решении задачи, если применять его
неправильно.
=============xi
Все алгоритмы также представлены в виде исходных текстов на Visual Basic,
которые вы можете использовать в своих программах без каких-либо изменений.
Они демонстрируют использование алгоритмов в программах, а также важные
характерные особенности работы самих алгоритмов.
Что дают вам эти знания
После ознакомления с данным материалом и примерами вы получите:
1. Понятие об алгоритмах. После прочтения данного материала и выполнения примеров программ, вы сможете применять сложные алгоритмы в своих проектах на Visual Basic и критически оценивать другие алгоритмы, написанные вами или кем-либо еще.
2. Большую подборку исходных текстов, которые вы сможете легко добавить к вашим программам. Используя код, содержащийся в примерах, вы сможете легко добавлять мощные алгоритмы к вашим приложениям.
3. Готовые примеры программ дадут вам возможность протестировать алгоритмы.
Вы можете использовать эти примеры и модифицировать их для углубленного изучения алгоритмов и понимания их работы, или использовать их как основу для разработки собственных приложений.
Целевая аудитория
В этом материале обсуждаются углубленные вопросы программирования на Visual
Basic. Они не предназначена для обучения программированию на этом языке.
Если вы хорошо разбираетесь в основах программирования на Visual Basic, вы
сможете сконцентрировать внимание на алгоритмах вместо того, чтобы
застревать на деталях языка.
В этом материале изложены важные концепции программирования, которые могут
быть с успехом применены для решения новых задач. Приведенные алгоритмы
используют мощные программные методы, такие как рекурсия, разбиение на
части, динамическое распределение памяти и сетевые структуры данных,
которые вы можете применять для решения своих конкретных задач.
Даже если вы еще не овладели в полной мере программированием на Visual
Basic, вы сможете скомпилировать примеры программ и сравнить
производительность различных алгоритмов. Более того, вы сможете выбрать
удовлетворяющие вашим требованиям алгоритмы и добавить их к вашим проектам
на Visual Basic.
Совместимость с разными версиями Visual Basic
Выбор наилучшего алгоритма определяется не особенностями версии языка
программирования, а фундаментальными принципами программирования.
=================xii
Некоторые новые понятия, такие как ссылки на объекты, классы и коллекции,
которые были впервые введены в 4-й версии Visual Basic, облегчают
понимание, разработку и отладку некоторых алгоритмов. Классы могут
заключать некоторые алгоритмы в хорошо продуманных модулях, которые легко
вставить в программу. Хотя для того, чтобы применять эти алгоритмы,
необязательно разбираться в новых понятиях языка, эти новые возможности
предоставляют слишком большие преимущества, чтобы ими можно было
пренебречь.
Поэтому примеры алгоритмов в этом материале написаны для использования в 4-
й и 5-й версиях Visual. Если вы откроете их в 5-й версии Visual Basic,
среда разработки предложит вам сохранить их в формате 5-й версии, но
никаких изменений в код вносить не придется. Все алгоритмы были
протестированы в обеих версиях.
Эти программы демонстрируют использование алгоритмов без применения
объектно-ориентированного подхода. Ссылки и коллекции облегчают
программирование, но их применение может приводить к некоторому замедлению
работы программ по сравнению со старыми версиями.
Тем не менее, игнорирование классов, объектов и коллекций привело бы к
упущению многих действительно мощных свойств. Их использование позволяет
достичь нового уровня модульности, разработки и повторного использования
кода. Их, безусловно, необходимо иметь в виду, по крайней мере, на
начальных этапах разработки. В дальнейшем, если возникнут проблемы с
производительностью, вы сможете модифицировать код, используя более быстрые
низкоуровневые методы.
Языки программирования зачастую развиваются в сторону усложнения, но редко
в противоположном направлении. Замечательным примером этого является
наличие оператора goto в языке C. Это неудобный оператор, потенциальный
источник ошибок, который почти не используется большинством программистов
на C, но он по-прежнему остается в синтаксисе языка с 1970 года. Он даже
был включен в C++ и позднее в Java, хотя создание нового языка было хорошим
предлогом избавиться от него.
Так и новые версии Visual Basic будут продолжать вводить новые свойства в
язык, но маловероятно, что из них будут исключены строительные блоки,
использованные при применении алгоритмов, описанных в данном материале.
Независимо от того, что будет добавлено в 6-й, 7-й или 8-й версии Visual
Basic, классы, массивы и определяемые пользователем типы данных останутся в
языке. Большая часть, а может и все алгоритмы из приведенных ниже, будут
выполняться без изменений в течение еще многих лет.
Обзор глав
В 1 главе рассматриваются понятия, которые вы должны понимать до того, как
приступить к анализу сложных алгоритмов. В ней изложены методы, которые
потребуются для теоретического анализа вычислительной сложности алгоритмов.
Некоторые алгоритмы с высокой теоретической производительностью на практике
дают не очень хорошие результаты, поэтому в этой главе также затрагиваются
практические соображения, например обращение к файлу подкачки и
сравнивается использование коллекций и массивов.
Во 2 главе показано, как образуются различные виды списков с использованием
массивов, объектов, и псевдоуказателей. Эти структуры данных можно с
успехом применять во многих программах, и они используются в следующих
главах
В 3 главе описаны два особых типа списков: стеки и очереди. Эти структуры
данных используются во многих алгоритмах, включая некоторые алгоритмы,
описанные в последующих главах. В конце главы приведена модель очереди на
регистрацию в аэропорту.
В 5 главе обсуждается мощный инструмент — рекурсия. Рекурсия может быть
также запутанной и приводить к проблемам. В 5 главе объясняется, в каких
случаях следует применять рекурсию и показывает, как можно от нее
избавиться, если это необходимо.
В 6 главе используются многие из ранее описанных приемов, такие как
рекурсия и связные списки, для изучения более сложной темы — деревьев. Эта
глава также охватывает различные представления деревьев, такие как деревья
с полными узлами (fat node) и представление в виде нумерацией связей
(forward star). В ней также описаны некоторые важные алгоритмы работы с
деревьями, таки как обход вершин дерева.
В 7 главе затронута более сложная тема. Сбалансированные деревья обладают
особыми свойствами, которые позволяют им оставаться уравновешенными и
эффективными. Алгоритмы сбалансированных деревьев удивительно просто
описываются, но их достаточно трудно реализовать программно. В этой главе
используется одна из наиболее мощных структур подобного типа — Б+дерево
(B+Tree) для создания сложной базы данных.
В 8 главе обсуждаются задачи, которые можно описать как поиск ответов в
дереве решений. Даже для небольших задач, эти деревья могут быть
гигантскими, поэтому необходимо осуществлять поиск в них максимально
эффективно. В этой главе сравниваются некоторые различные методы, которые
позволяют выполнить такой поиск.
Глава 9 посвящена, пожалуй, наиболее изучаемой области теории
алгоритмов — сортировке. Алгоритмы сортировки интересны по нескольким
причинам. Во-первых, сортировка — часто встречающаяся задача. Во-вторых,
различные алгоритмы сортировок обладают своими сильными и слабыми
сторонами, поэтому не существует одного алгоритма, который показывал бы
наилучшие результаты в любых ситуациях. И, наконец, алгоритмы сортировки
демонстрируют широкий спектр важных алгоритмических методов, таких как
рекурсия, пирамиды, а также использование генератора случайных чисел для
уменьшения вероятности выпадения наихудшего случая.
В главе 10 рассматривается близкая к сортировке тема. После выполнения
сортировки списка, программе может понадобиться найти элементы в нем. В
этой главе сравнивается несколько наиболее эффективных методов поиска
элементов в сортированных списках.
=========xiv
В главе 11 обсуждаются методы сохранения и поиска элементов, работающие
даже быстрее, чем это возможно при использовании деревьев, сортировки или
поиска. В этой главе также описаны некоторые методы хэширования, включая
использование блоков и связных списков, и несколько вариантов открытой
адресации.
В главе 12 описана другая категория алгоритмов — сетевые алгоритмы.
Некоторые из этих алгоритмов, такие как вычисление кратчайшего пути,
непосредственно применимы к физическим сетям. Эти алгоритмы также могут
косвенно применяться для решения других задач, которые на первый взгляд не
кажутся связанными с сетями. Например, алгоритмы поиска кратчайшего
расстояния могут разбивать сеть на районы или определять критичные задачи в
расписании проекта.
В главе 13 объясняются методы, применение которых стало возможным благодаря
введению классов в 4-й версии Visual Basic. Эти методы используют объектно-
ориентированный подход для реализации нетипичного для традиционных
алгоритмов поведения.
===================xv
Аппаратные требования
Для работы с примерами вам потребуется компьютер, конфигурация которого
удовлетворяет требованиям для работы программной среды Visual Basic. Эти
требования выполняются почти для всех компьютеров, на которых может
работать операционная система Windows.
На компьютерах разной конфигурации алгоритмы выполняются с различной
скоростью. Компьютер с процессором Pentium Pro с тактовой частотой 2000 МГц
и 64 Мбайт оперативной памяти будет работать намного быстрее, чем машина с
386 процессором и всего 4 Мбайт памяти. Вы быстро узнаете, на что способно
ваше аппаратное обеспечение.
Изменения во втором издании
Самое большое изменение в новой версии Visual Basic — это появление
классов. Классы позволяют рассмотреть некоторые задачи с другой стороны,
позволяя использовать более простой и естественный подход к пониманию и
применению многих алгоритмов. Изменения в коде программ в этом изложении
используют преимущества, предоставляемые классами. Их можно разбить на три
категории:
1. Замена псевдоуказателей классами. Хотя все алгоритмы, которые были написаны для старых версий VB, все еще работают, многие из тех, что были написаны с применением псевдоуказателей (описанных во 2 главе), гораздо проще понять, используя классы.
2. Инкапсуляция. Классы позволяют заключить алгоритм в компактный модуль, который легко использовать в программе. Например, при помощи классов можно создать несколько связных списков и не писать при этом дополнительный код для управления каждым списком по отдельности.
3. Объектно-ориентированные технологии. Использование классов также позволяет легче понять некоторые объектно-ориентированные алгоритмы. В главе 13 описываются методы, которые сложно реализовать без использования классов.
Как пользоваться этим материалом
В главе 1 даются общие понятия, которые используются на протяжении всего
изложения, поэтому вам следует начать чтение с этой главы. Вам стоит
ознакомиться с этой тематикой, даже если вы не хотите сразу же достичь
глубокого понимания алгоритмов.
В 6 главе обсуждаются понятия, которые используются в 7, 8 и 12 главах,
поэтому вам следует прочитать 6 главу до того, как браться за них.
Остальные главы можно читать в любом порядке.
=============xvi
В табл. 1 показаны три возможных учебных плана, которыми вы можете руководствоваться при изучении материала в зависимости от того, насколько широко вы хотите ознакомиться с алгоритмами. Первый план включает в себя освоение основных методов и структур данных, которые могут быть полезны при разработке вами собственных программ. Второй кроме этого описывает также основные алгоритмы, такие как алгоритмы сортировки и поиска, которые могут понадобиться при написании более сложных программ.
Последний план дает порядок для изучения всего материала целиком. Хотя 7 и 8 главы логически вытекают из 6 главы, они сложнее для изучения, чем следующие главы, поэтому они изучаются несколько позже.
Почему именно Visual Basic?
Наиболее часто встречаются жалобы на медленное выполнение программ,
написанных на Visual Basic. Многие другие компиляторы, такие как Delphi,
Visual C++ дают более быстрый и гибкий код, и предоставляют программисту
более мощные средства, чем Visual Basic. Поэтому логично задать вопрос —
«Почему я должен использовать именно Visual Basic для написания сложных
алгоритмов? Не лучше было бы использовать Delphi или C++ или, по крайней
мере, написать алгоритмы на одном из этих языков и подключать их к
программам на Visual Basic при помощи библиотек?» Написание алгоритмов на
Visual Basic имеет смысл по нескольким причинам.
Во-первых, разработка приложения на Visual C++ гораздо сложнее и
проблематичнее, чем на Visual Basic. Некорректная реализация в программе
всех деталей программирования под Windows может привести к сбоям в вашем
приложении, среде разработки, или в самой операционной системе Windows.
Во-вторых, разработка библиотеки на языке C++ для использования в
программах на Visual Basic включает в себя много потенциальных опасностей,
характерных и для приложений Windows, написанных на C++. Если библиотека
будет неправильно взаимодействовать с программой на Visual Basic, она также
приведет к сбоям в программе, а возможно и в среде разработки и системе.
В-третьих, многие алгоритмы достаточно эффективны и показывают неплохую
производительность даже при применении не очень быстрых компиляторов,
таких, как Visual Basic. Например, алгоритм сортировки подсчетом,
@Таблица 1. Планы занятий
===============xvii
описываемый в 9 главе, сортирует миллион целых чисел менее чем за 2 секунды
на компьютере с процессором Pentium с тактовой частотой 233 МГц. Используя
библиотеку C++, можно было бы сделать алгоритм немного быстрее, но скорости
версии на Visual Basic и так хватает для большинства приложений.
Скомпилированные при помощи 5-й версией Visual Basic исполняемые файлы
сводят отставание по скорости к минимуму.
В конечном счете, разработка алгоритмов на любом языке программирования
позволяет больше узнать об алгоритмах вообще. По мере изучения алгоритмов,
вы освоите методы, которые сможете применять в других частях своих
программ. После того, как вы овладеете в совершенстве алгоритмами на Visual
Basic, вам будет гораздо легче реализовать их на Delphi или C++, если это
будет необходимо.
=============xviii
Глава 1. Основные понятия
В этой главе содержатся общие понятия, которые нужно усвоить перед началом
серьезного изучения алгоритмов. Начинается она с вопроса «Что такое
алгоритмы?». Прежде чем углубиться в детали программирования алгоритмов,
стоит потратить немного времени, чтобы разобраться в том, что это такое.
Затем в этой главе дается введение в формальную теорию сложности алгоритмов
(complexity theory). При помощи этой теории можно оценить теоретическую
вычислительную сложность алгоритмов. Этот подход позволяет сравнивать
различные алгоритмы и предсказывать их производительность в разных
условиях. В главе приводится несколько примеров применения теории сложности
к небольшим задачам.
Некоторые алгоритмы с высокой теоретической производительностью не слишком
хорошо работают на практике, поэтому в данной главе также обсуждаются
некоторые реальные предпосылки для создания программ. Слишком частое
обращение к файлу подкачки или плохое использование ссылок на объекты и
коллекции может значительно снизить производительность прекрасного в
остальных отношениях приложения.
После знакомства с основными понятиями, вы сможете применять их к
алгоритмам, изложенным в последующих главах, а также для анализа
собственных программ для оценки их производительности и сможете
предугадывать возможные проблемы до того, как они обернутся катастрофой.
Что такое алгоритмы?
Алгоритм – это последовательность инструкций для выполнения какого-либо
задания. Когда вы даете кому-то инструкции о том, как отремонтировать
газонокосилку, испечь торт, вы тем самым задаете алгоритм действий.
Конечно, подобные бытовые алгоритмы описываются неформально, например, так:
Проверьте, находится ли машина на стоянке.
Убедитесь, что машина поставлена на ручной тормоз.
Поверните ключ.
И т.д.
==========1
При этом по умолчанию предполагается, что человек, который будет
следовать этим инструкциям, сможет самостоятельно выполнить множество
мелких операций, например, отпереть и открыть дверь, сесть за руль,
пристегнуть ремень, найти ручной тормоз и так далее.
Если же составляется алгоритм для исполнения компьютером, вы не можете
полагаться на то, что компьютер поймет что-либо, если это не описано
заранее. Словарь компьютера (язык программирования) очень ограничен и все
инструкции для компьютера должны быть сформулированы на этом языке. Поэтому
для написания компьютерных алгоритмов используется формализованный стиль.
Интересно попробовать написать формализованный алгоритм для обычных
ежедневных задач. Например, алгоритм вождения машины мог бы выглядеть
примерно так:
Если дверь закрыта:
Вставить ключ в замок
Повернуть ключ
Если дверь остается закрытой, то:
Повернуть ключ в другую сторону
Повернуть ручку двери
И т.д.
Этот фрагмент «кода» отвечает только за открывание двери; при этом даже не
проверяется, какая дверь открывается. Если дверь заело или в машине
установлена противоугонная система, то алгоритм открывания двери может быть
достаточно сложным.
Формализацией алгоритмов занимаются уже тысячи лет. За 300 лет до н.э.
Евклид написал алгоритмы деления углов пополам, проверки равенства
треугольников и решения других геометрических задач. Он начал с небольшого
словаря аксиом, таких как «параллельные линии не пересекаются» и построил
на их основе алгоритмы для решения сложных задач.
Формализованные алгоритмы такого типа хорошо подходят для задач математики,
где должна быть доказана истинность какого-либо положения или возможность
выполнения каких-то действий, скорость же исполнения алгоритма не важна.
Для выполнения реальных задач, связанных с выполнением инструкций, например
задачи сортировки на компьютере записей о миллионе покупателей,
эффективность выполнения становится важной частью постановки задачи.
Анализ скорости выполнения алгоритмов
Есть несколько способов оценки сложности алгоритмов. Программисты обычно сосредотачивают внимание на скорости алгоритма, но важны и другие требования, например, к размеру памяти, свободному месту на диске или другим ресурсам. От быстрого алгоритма может быть мало толку, если под него требуется больше памяти, чем установлено на компьютере.
Пространство — время
Многие алгоритмы предоставляют выбор между скоростью выполнения и используемыми программой ресурсами. Задача может выполняться быстрее, используя больше памяти, или наоборот, медленнее, заняв меньший объем памяти.
===========2
Хорошим примером в данном случае может служить алгоритм нахождения
кратчайшего пути. Задав карту улиц города в виде сети, можно написать
алгоритм, вычисляющий кратчайшее расстояние между любыми двумя точками в
этой сети. Вместо того чтобы каждый раз заново пересчитывать кратчайшее
расстояние между двумя заданными точками, можно заранее просчитать его для
всех пар точек и сохранить результаты в таблице. Тогда, чтобы найти
кратчайшее расстояние для двух заданных точек, достаточно будет просто
взять готовое значение из таблицы.
При этом мы получим результат практически мгновенно, но это потребует
большого объема памяти. Карта улиц для большого города, такого как Бостон
или Денвер, может содержать сотни тысяч точек. Для такой сети таблица
кратчайших расстояний содержала бы более 10 миллиардов записей. В этом
случае выбор между временем исполнения и объемом требуемой памяти очевиден:
поставив дополнительные 10 гигабайт оперативной памяти, можно заставить
программу выполняться гораздо быстрее.
Из этой связи вытекает идея пространственно-временной сложности алгоритмов.
При этом подходе сложность алгоритма оценивается в терминах времени и
пространства, и находится компромисс между ними.
В этом материале основное внимание уделяется временной сложности, но мы
также постарались обратить внимание и на особые требования к объему памяти
для некоторых алгоритмов. Например, сортировка слиянием (mergesort),
обсуждаемая в 9 главе, требует больше временной памяти. Другие алгоритмы,
например пирамидальная сортировка (heapsort), которая также обсуждается в 9
главе, требует обычного объема памяти.
Оценка с точностью до порядка
При сравнении различных алгоритмов важно понимать, как сложность алгоритма
соотносится со сложностью решаемой задачи. При расчетах по одному алгоритму
сортировка тысячи чисел может занять 1 секунду, а сортировка миллиона — 10
секунд, в то время как расчеты по другому алгоритму могут потребовать 2 и 5
секунд соответственно. В этом случае нельзя однозначно сказать, какая из
двух программ лучше — это будет зависеть от исходных данных.
Различие производительности алгоритмов на задачах разной вычислительной
сложности часто более важно, чем просто скорость алгоритма. В
вышеприведенном случае, первый алгоритм быстрее сортирует короткие списки,
а второй — длинные.
Производительность алгоритма можно оценить по порядку величины. Алгоритм
имеет сложность порядка O(f(N)) (произносится «О большое от F от N»), если
время выполнения алгоритма растет пропорционально функции f(N) с
увеличением размерности исходных данных N. Например, рассмотрим фрагмент
кода, сортирующий положительные числа:
For I = 1 To N
"Поиск наибольшего элемента в списке.
MaxValue = 0
For J = 1 to N
If Value(J) > MaxValue Then
MaxValue = Value(J)
MaxJ = J
End If
Next J
"Вывод наибольшего элемента на печать.
Print Format$(MaxJ) & ":" & Str$(MaxValue)
"Обнуление элемента для исключения его из дальнейшего поиска.
Value(MaxJ) = 0
Next I
===============3
В этом алгоритме переменная цикла I последовательно принимает значения от 1
до N. Для каждого приращения I переменная J в свою очередь также принимает
значения от 1 до N. Таким образом, в каждом внешнем цикле выполняется еще N
внутренних циклов. В итоге внутренний цикл выполняется N*N или N2 раз и,
следовательно, сложность алгоритма порядка O(N2).
При оценке порядка сложности алгоритмов используется только наиболее быстро
растущая часть уравнения алгоритма. Допустим, время выполнения алгоритма
пропорционально N3+N. Тогда сложность алгоритма будет равна O(N3).
Отбрасывание медленно растущих частей уравнения позволяет оценить поведение
алгоритма при увеличении размерности данных задачи N.
При больших N вклад второй части в уравнение N3+N становится все менее
заметным. При N=100, разность N3+N=1.000.100 и N3 равна всего 100, или
менее чем 0,01 процента. Но это верно только для больших N. При N=2,
разность между N3+N =10 и N3=8 равна 2, а это уже 20 процентов.
Постоянные множители в соотношении также игнорируются. Это позволяет легко
оценить изменения в вычислительной сложности задачи. Алгоритм, время
выполнения которого пропорционально 3*N2, будет иметь порядок O(N2). Если
увеличить N в 2 раза, то время выполнения задачи возрастет примерно в 22,
то есть в 4 раза.
Игнорирование постоянных множителей позволяет также упростить подсчет числа
шагов алгоритма. В предыдущем примере внутренний цикл выполняется N2 раз,
при этом внутри цикла выполняется несколько инструкций. Можно просто
подсчитать число инструкций If, можно подсчитать также инструкции,
выполняемые внутри цикла или, кроме того, еще и инструкции во внешнем
цикле, например операторы Print.
Вычислительная сложность алгоритма при этом будет пропорциональна N2, 3*N2
или 3*N2+N. Оценка сложности алгоритма по порядку величины даст одно и то
же значение O(N3) и отпадет необходимость в точном подсчете количества
операторов.
Поиск сложных частей алгоритма
Обычно наиболее сложным является выполнение циклов и вызовов процедур. В предыдущем примере, весь алгоритм заключен в двух циклах.
============4
Если процедура вызывает другую процедуру, необходимо учитывать сложность
вызываемой процедуры. Если в ней выполняется фиксированное число
инструкций, например, осуществляется вывод на печать, то при оценке порядка
сложности ее можно не учитывать. С другой стороны, если в вызываемой
процедуре выполняется O(N) шагов, она может вносить значительный вклад в
сложность алгоритма. Если вызов процедуры осуществляется внутри цикла, этот
вклад может быть еще больше.
Приведем в качестве примера программу, содержащую медленную процедуру Slow
со сложностью порядка O(N3) и быструю процедуру Fast со сложностью порядка
O(N2). Сложность всей программы будет зависеть от соотношения между этими
двумя процедурами.
Если процедура Slow вызывается в каждом цикле процедуры Fast, порядки
сложности процедур перемножаются. В этом случае сложность алгоритма равна
произведению O(N2) и O(N3) или O(N3*N2)=O(N5). Приведем иллюстрирующий этот
случай фрагмент кода:
Sub Slow()
Dim I As Integer
Dim J As Integer
Dim K As Integer
For I = 1 To N
For J = 1 To N
For K = 1 To N
" Выполнить какие-либо действия.
Next K
Next J
Next I
End Sub
Sub Fast()
Dim I As Integer
Dim J As Integer
Dim K As Integer
For I = 1 To N
For J = 1 To N
Slow " Вызов процедуры Slow.
Next J
Next I
End Sub
Sub MainProgram()
Fast
End Sub
С другой стороны, если процедуры независимо вызываются из основной программы, их вычислительная сложность суммируется. В этом случае полная сложность будет равна O(N3)+O(N2)=O(N3). Такую сложность, например, будет иметь следующий фрагмент кода:
Sub Slow()
Dim I As Integer
Dim J As Integer
Dim K As Integer
For I = 1 To N
For J = 1 To N
For K = 1 To N
" Выполнить какие-либо действия.
Next K
Next J
Next I
End Sub
Sub Fast()
Dim I As Integer
Dim J As Integer
For I = 1 To N
For J = 1 To N
" Выполнить какие-либо действия.
Next J
Next I
End Sub
Sub MainProgram()
Slow
Fast
End Sub
==============5
Сложность рекурсивных алгоритмов
Рекурсивными процедурами (recursive procedure) называются процедуры,
вызывающие сами себя. Во многих рекурсивных алгоритмах именно степень
вложенности рекурсии определяет сложность алгоритма, при этом не всегда
легко оценить порядок сложности. Рекурсивная процедура может выглядеть
простой, но при этом вносить большой вклад в сложность программы,
многократно вызывая саму себя.
Следующий фрагмент кода содержит подпрограмму всего из двух операторов. Тем
не менее, для заданного N подпрограмма выполняется N раз, таким образом,
вычислительная сложность фрагмента порядка O(N).
Sub CountDown(N As Integer)
If N 20 Then
ArraySize = ArraySize –10
ReDim Preserve List(1 To ArraySize)
End If
End Sub
=============20
Для очень больших массивов это решение может также оказаться не самым
лучшим. Если вам нужен список, содержащий 1000 элементов, к которому обычно
добавляется по 100 элементов, то все еще слишком много времени будет
тратиться на изменение размера массива. Очевидной стратегией в этом случае
было бы увеличение приращения размера массива с 10 до 100 или более ячеек.
Тогда можно было бы добавлять по 100 элементов одновременно без частого
изменения размера списка.
Более гибким решением будет изменение приращения в зависимости от размера
массива. Для небольших списков это приращение было бы также небольшим. Хотя
изменения размера массива происходили бы чаще, они потребовали бы
относительно немного времени для небольших массивов. Для больших списков,
приращение размера будет больше, поэтому их размер будет изменяться реже.
Следующая программа пытается поддерживать примерно 10 процентов списка
свободным. Когда массив заполняется, его размер увеличивается на 10
процентов. Если свободное пространство составляет более 20 процентов от
размера массива, программа уменьшает его.
При увеличении размера массива, добавляется не меньше 10 элементов, даже
если 10 процентов от размера массива составляют меньшую величину. Это
уменьшает число необходимых изменений размера массива, если список очень
мал.
Const WANT_FREE_PERCENT = .1 ‘ 10% свободного места.
Const MIN_FREE = 10 ‘ Минимальное число пустых ячеек.
Global List() As String ‘ Массив элементов списка.
Global ArraySize As Integer ‘ Размер массива.
Global NumItems As Integer ‘ Число элементов в списке.
Global ShrinkWhen As Integer ‘ Уменьшить размер, если NumItems <
ShrinkWhen.
‘ Если массив заполнен, увеличить его размер.
‘ Затем добавить новый элемент в конец списка.
Sub Add(value As String)
NumItems = NumItems + 1
If NumItems > ArraySize Then ResizeList
List(NumItems) = value
End Sub
‘ Удалить последний элемент из списка.
‘ Если в массиве много пустых ячеек, уменьшить его размер.
Sub RemoveLast()
NumItems = NumItems – 1
If NumItems < ShrinkWhen Then ResizeList
End Sub
‘ Увеличить размер массива, чтобы 10% ячеек были свободны.
Sub ResizeList()
Dim want_free As Integer want_free = WANT_FREE_PERCENT * NumItems
If want_free < MIN_FREE Then want_free = MIN_FREE
ArraySize = NumItems + want_free
ReDim Preserve List(1 To ArraySize)
‘ Уменьшить размер массива, если NumItems < ShrinkWhen.
ShrinkWhen = NumItems – want_free
End Sub
===============21
Класс SimpleList
Чтобы использовать этот простой подход, программе необходимо знать все
параметры списка, при этом нужно следить за размером массива, числом
используемых элементов, и т.д. Если необходимо создать больше одного
списка, потребуется множество копий переменных и код, управляющий разными
списками, будет дублироваться.
Классы Visual Basic могут сильно облегчить выполнение этой задачи. Класс
SimpleList инкапсулирует эту структуру списка, упрощая управление списками.
В этом классе присутствуют методы Add и Remove для использования в основной
программе. В нем также есть процедуры извлечения свойств NumItems и
ArraySize, с помощью которых программа может определить число элементов в
списке и объем занимаемой им памяти.
Процедура ResizeList объявлена как частная внутри класса SimpleList. Это
скрывает изменение размера списка от основной программы, поскольку этот код
должен использоваться только внутри класса.
Используя класс SimpleList, легко создать в приложении несколько списков.
Для того чтобы создать новый объект для каждого списка, просто используется
оператор New. Каждый из объектов имеет свои переменные, поэтому каждый из
них может управлять отдельным списком:
Dim List1 As New SimpleList
Dim List2 As New SimpleList
Когда объект SimpleList увеличивает массив, он выводит окно сообщения, показывающее размер массива, количество неиспользуемых элементов в нем, и значение переменной ShrinkWhen. Когда число использованных ячеек в массиве становится меньше, чем значение ShrinkWhen, программа уменьшает размер массива. Заметим, что когда массив практически пуст, переменная ShrinkWhen иногда становится равной нулю или отрицательной. В этом случае размер массива не будет уменьшаться, даже если вы удалите все элементы из списка.
=============22
Программа SimList добавляет к массиву еще 50 процентов пустых ячеек, если необходимо увеличить его размер, и всегда оставляет при этом не менее 1 пустой ячейки. Эти значения был выбраны для удобства работы с программой. В реальном приложении, процент свободной памяти должен быть меньше, а число свободных ячеек больше. Более разумным в таком случае было бы выбрать значения порядка 10 процентов от текущего размера списка и минимум 10 свободных ячеек.
Неупорядоченные списки
В некоторых приложениях может понадобиться удалять элементы из середины списка, добавляя при этом элементы в конец списка. В этом случае порядок расположения элементов может быть не важен, но при этом может быть необходимо удалять определенные элементы из списка. Списки такого типа называются неупорядоченными списками (unordered lists). Они также иногда называются «множеством элементов».
Неупорядоченный список должен поддерживать следующие операции:
1. добавление элемента к списку;
2. удаление элемента из списка;
3. определение наличия элемента в списке;
4. выполнение каких-либо операций (например, вывода на дисплей или принтер) для всех элементов списка.
Простую структуру, представленную в предыдущем параграфе, можно легко
изменить для того, чтобы обрабатывать такие списки. Когда удаляется элемент
из середины списка, остальные элементы сдвигаются на одну позицию, заполняя
образовавшийся промежуток. Это показано на рис. 2.1, на котором второй
элемент удаляется из списка, и третий, четвертый, и пятый элементы
сдвигаются влево, заполняя свободный участок.
Удаление из массива элемента при таком подходе может занять достаточно
много времени, особенно если удаляется элемент в начале списка. Чтобы
удалить первый элемент из массива с 1000 элементов, потребуется сдвинуть
влево на одну позицию 999 элементов. Гораздо быстрее удалять элементы можно
при помощи простой схемы чистки памяти (garbage collection).
Вместо удаления элементов из списка, пометьте их как неиспользуемые. Если
элементы списка — данные простых типов, например целые, можно помечать
элементы, используя определенное, так называемое «мусорное» значение
(garbage value).
@Рисунок 2.1 Удаление элемента из середины массива
===========23
Для целых чисел можно использовать для этого значение -32.767. Для переменной типа Variant можно использовать значение NULL. Это значение присваивается каждому неиспользуемому элементу. Следующий фрагмент кода демонстрирует удаление элемента из подобного целочисленного списка:
Const GARBAGE_VALUE = -32767
‘ Пометить элемент как неиспользуемый.
Sub RemoveFromList(position As Long)
List(position) = GARBAGE_VALUE
End Sub
Если элементы списка — это структуры, определенные оператором Type, вы можете добавить к такой структуре новое поле IsGarbage. Когда элемент удаляется из списка, значение поля IsGarbage устанавливается в True.
Type MyData
Name As Sring ‘ Данные.
IsGarbage As Integer ‘ Этот элемент не используется?
End Type
‘ Пометить элемент, как не использующийся.
Sub RemoveFromList (position As Long)
List(position).IsGarbage = True
End Sub
Для простоты далее в этом разделе предполагается, что элементы данных
являются данными универсального типа и их можно помечать значением NULL.
Теперь можно изменить другие процедуры, которые используют список, чтобы
они пропускали помеченные элементы. Например, так можно модифицировать
процедуру, которая печатает список:
‘ Печать элементов списка.
Sub PrintItems()
Dim I As Long
For I = 1 To ArraySize
If Not IsNull(List(I)) Then ‘ Если элемент не помечен
Print Str$(List(I)) ‘ напечатать его.
End If
Next I
End Sub
После использования в течение некоторого времени схемы пометки «мусора», список может оказаться полностью им заполнен. В конце концов, подпрограммы вроде этой процедуры больше времени будут тратить на пропуск ненужных элементов, чем на обработку настоящих данных.
=============24
Для того, чтобы избежать этого, можно периодически запускать процедуру
очистки памяти (garbage collection routine). Эта процедура перемещает все
непомеченные записи в начало массива. После этого можно добавить их к
свободным элементам в конце массива. Когда потребуется добавить к массиву
дополнительные элементы, их также можно будет использовать без изменения
размера массива.
После добавления помеченных элементов к другим свободным ячейкам массива,
полный объем свободного пространства может стать достаточно большим, и в
этом случае можно уменьшить размер массива, освобождая память:
Private Sub CollectGarbage()
Dim i As Long
Dim good As Long
good = 1 ‘ Первый используемый элемент.
For i = 1 To m_NumItems
‘ Если он не помечен, переместить его на новое место.
If Not IsNull(m_List(i)) Then m_List(good) = m_list(i) good = good + 1
End If
Next i
‘ Последний используемый элемент. m_NumItems(good) = good - 1
‘ Необходимо ли уменьшать размер списка?
If m_NumItems < m_ShrinkWhen Then ResizeList
End Sub
При выполнении чистки памяти, используемые элементы перемещаются ближе к
началу списка, заполняя пространство, которое занимали помеченные элементы.
Значит, положение элементов в списке может измениться во время этой
операции. Если другие часть программы обращаются к элементам списка по их
положению в нем, необходимо модифицировать процедуру чистки памяти, с тем,
чтобы она также обновляла ссылки на положение элементов в списке. В общем
случае это может оказаться достаточно сложным, приводя к проблемам при
сопровождении программ.
Можно выбирать разные моменты для запуска процедуры чистки памяти. Один из
них — когда массив достигает определенного размера, например, когда список
содержит 30000 элементов.
Этому методу присущи определенные недостатки. Во-первых, он использует
большой объем памяти. Если вы часто добавляете или удаляете элементы,
«мусор» будет занимать довольно большую часть массива. При таком
неэкономном расходовании памяти, программа может тратить время на свопинг,
хотя список мог бы целиком помещаться в памяти при более частом
переупорядочивании.
===========25
Во-вторых, если список начинает заполняться ненужными данными, процедуры,
которые его используют, могут стать чрезвычайно неэффективными. Если в
массиве из 30.000 элементов 25.000 не используются, подпрограмма типа
описанной выше PrintItems, может выполняться ужасно медленно.
И, наконец, чистка памяти для очень большого массива может потребовать
значительного времени, в особенности, если при обходе элементов массива
программе приходится обращаться к страницам, выгруженным на диск. Это может
приводить к «подвисанию» вашей программы на несколько секунд во время
чистки памяти.
Чтобы решить эту проблему, можно создать новую переменную GarbageCount, в
которой будет находиться число ненужных элементов в списке. Когда
значительная часть памяти, занимаемой списком, содержит ненужные элементы,
вы может начать процедуру «сборки мусора».
Dim GarbageCount As Long ‘ Число ненужных элементов.
Dim MaxGarbage As Long ‘ Это значение определяется в ResizeList.
‘ Пометить элемент как ненужный.
‘ Если «мусора» слишком много, начать чистку памяти.
Public Sub Remove(position As Long) m_List(position) = Null m_GarbageCount = m_GarbageCount + 1
‘ Если «мусора» слишком много, начать чистку памяти.
If m_GarbageCount > m_MaxGarbage Then CollectGarbage
End Sub
Программа Garbage демонстрирует этот метод чистки памяти. Она пишет рядом с
неиспользуемыми элементами списка слово «unused», а рядом с помеченными как
ненужные — слово «garbage». Программа использует класс GarbageList примерно
так же, как программа SimList использовала класс SimpleList, но при этом
она еще осуществляет «сборку мусора».
Чтобы добавить элемент к списку, введите его значение и нажмите на кнопку
Add (Добавить). Для удаления элемента выделите его, а затем нажмите на
кнопку Remove (Удалить). Если список содержит слишком много «мусора»,
программа начнет выполнять чистку памяти.
При каждом изменении размера списка объекта GarbageList, программа выводит
окно сообщения, в котором приводится число используемых и свободных
элементов в списке, а также значения переменных MaxGarbage и ShrinkWhen.
Если удалить достаточное количество элементов, так что больше, чем
MaxGarbage элементов будут помечены как ненужные, программа начнет
выполнять чистку памяти. После ее окончания, программа уменьшает размер
массива, если он содержит меньше, чем ShrinkWhen занятых элементов.
Если размер массива должен быть увеличен, программа Garbage добавляет к
массиву еще 50 процентов пустых ячеек, и всегда оставляет хотя бы одну
пустую ячейку при любом изменении размера массива. Эти значения были
выбраны для упрощения работы пользователя со списком. В реальной программе
процент свободной памяти должен быть меньше, а число свободных ячеек —
больше. Оптимальными выглядят значения порядка 10 процентов и 10 свободных
ячеек.
==========26
Связные списки
Другая стратегия используется при управлении связанными списками. Связанный
список хранит элементы в структурах данных или объектах, которые называются
ячейками (cells). Каждая ячейка содержит указатель на следующую ячейку в
списке. Так как единственный тип указателей, которые поддерживает Visual
Basic — это ссылки на объекты, то ячейки в связном списке должны быть
объектами.
В классе, задающем ячейку, должна быть определена переменная NextCell,
которая указывает на следующую ячейку в списке. В нем также должны быть
определены переменные, содержащие данные, с которыми будет работать
программа. Эти переменные могут быть объявлены как открытые (public) внутри
класса, или класс может содержать процедуры для чтения и записи значений
этих переменных. Например, в связном списке с записями о сотрудниках, в
этих полях могут находиться имя сотрудника, номер социального страхования,
название должности, и т.д. Определения для класса EmpCell могут выглядеть
примерно так:
Public EmpName As String
Public SSN As String
Public JobTitle As String
Public NextCell As EmpCell
Программа создает новые ячейки при помощи оператора New, задает их значения
и соединяет их, используя переменную NextCell.
Программа всегда должна сохранять ссылку на вершину списка. Для того, чтобы
определить, где заканчивается список, программа должна установить значение
NextCell для последнего элемента списка равным Nothing (ничего). Например,
следующий фрагмент кода создает список, представляющий трех сотрудников:
Dim top_cell As EmpCell
Dim cell1 As EmpCell
Dim cell2 As EmpCell
Dim cell3 As EmpCell
‘ Создание ячеек.
Set cell1 = New EmpCell cell1.EmpName = "Стивенс” cell1.SSN = "123-45-6789" cell1.JobTitle = "Автор"
Set cell2 = New EmpCell cell2.EmpName = "Кэтс” cell2.SSN = "123-45-6789" cell2.JobTitle = "Юрист"
Set cell3 = New EmpCell cell3.EmpName = "Туле” cell3.SSN = "123-45-6789" cell3.JobTitle = "Менеджер"
‘ Соединить ячейки, образуя связный список.
Set cell1.NextCell = cell2
Set cell2.NextCell = cell3
Set cell3.NextCell = Nothing
‘ Сохранить ссылку на вершину списка.
Set top_cell = cell1
===============27
На рис. 2.2 показано схематическое представление этого связного списка.
Прямоугольники представляют ячейки, а стрелки — ссылки на объекты.
Маленький перечеркнутый прямоугольник представляет значение Nothing,
которое обозначает конец списка. Имейте в виду, что top_cell, cell1 и
cell2 – это не настоящие объекты, а только ссылки, которые указывают на
них.
Следующий код использует связный список, построенный при помощи предыдущего
примера для печати имен сотрудников из списка. Переменная ptr используется
в качестве указателя на элементы списка. Она первоначально указывает на
вершину списка. В коде используется цикл Do для перемещения ptr по списку
до тех пор, пока указатель не дойдет до конца списка. Во время каждого
цикла, процедура печатает поле EmpName ячейки, на которую указывает ptr.
Затем она увеличивает ptr, указывая на следующую ячейку в списке. В конце
концов, ptr достигает конца списка и получает значение Nothing, и цикл Do
останавливается.
Dim ptr As EmpCell
Set ptr = top_cell ‘ Начать с вершины списка.
Do While Not (ptr Is Nothing)
‘ Вывести поле EmpName этой ячейки.
Debug.Print ptr.Empname
‘ Перейти к следующей ячейке в списке.
Set ptr = ptr.NextCell
Loop
После выполнения кода вы получите следующий результат:
Стивенс
Кэтс
Туле
@Рис. 2.2. Связный список
=======28
Использование указателя на другой объект называется косвенной адресацией
(indirection), поскольку вы используете указатель для косвенного
манипулирования данными. Косвенная адресация может быть очень запутанной.
Даже для простого расположения элементов, такого, как связный список,
иногда трудно запомнить, на какой объект указывает каждая ссылка. В более
сложных структурах данных, указатель может ссылаться на объект, содержащий
другой указатель. Если есть несколько указателей и несколько уровней
косвенной адресации, вы легко можете запутаться в них
Для того, чтобы облегчить понимание, в изложении используются иллюстрации,
такие как рис. 2.2,(для сетевой версии исключены, т.к. они многократно
увеличивают размер загружаемого файла) чтобы помочь вам наглядно
представить ситуацию там, где это возможно. Многие из алгоритмов, которые
используют указатели, можно легко проиллюстрировать подобными рисунками.
Добавление элементов к связному списку
Простой связный список, показанный на рис. 2.2, обладает несколькими важными свойствами. Во-первых, можно очень легко добавить новую ячейку в начало списка. Установим указатель новой ячейки NextCell на текущую вершину списка. Затем установим указатель top_cell на новую ячейку. Рис. 2.3 соответствует этой операции. Код на языке Visual Basic для этой операции очень прост:
Set new_cell.NextCell = top_cell
Set top_cell = new_cell
@Рис. 2.3. Добавление элемента в начало связного списка
Сравните размер этого кода и кода, который пришлось бы написать для добавления нового элемента в начало списка, основанного на массиве, в котором потребовалось бы переместить все элементы массива на одну позицию, чтобы освободить место для нового элемента. Эта операция со сложностью порядка O(N) может потребовать много времени, если список достаточно длинный. Используя связный список, моно добавить новый элемент в начало списка всего за пару шагов.
======29
Так же легко добавить новый элемент и в середину связного списка.
Предположим, вы хотите вставить новый элемент после ячейки, на которую
указывает переменная after_me. Установим значение NextCell новой ячейки
равным after_me.NextCell. Теперь установим указатель after_me.NextCell на
новую ячейку. Эта операция показана на рис. 2.4. Код на Visual Basic снова
очень прост:
Set new_cell.NextCell = after_me.NextCell
Set after_me.NextCell = new_cell
Удаление элементов из связного списка
Удалить элемент из вершины связного списка так же просто, как и добавить
его. Просто установите указатель top_cell на следующую ячейку в списке.
Рис. 2.5 соответствует этой операции. Исходный код для этой операции еще
проще, чем код для добавления элемента.
Set top_cell = top_cell.NextCell
Когда указатель top_cell перемещается на второй элемент в списке, в
программе больше не останется переменных, указывающих на первый объект. В
этом случае, счетчик ссылок на этот объект станет равен нулю, и система
автоматически уничтожит его.
Так же просто удалить элемент из середины списка. Предположим, вы хотите
удалить элемент, стоящий после ячейки after_me. Просто установите указатель
NextCell этой ячейки на следующую ячейку. Эта операция показана на рис.
2.6. Код на Visual Basic прост и понятен:
after_me.NextCell = after_me.NextCell.NextCell
@Рис. 2.4. Добавление элемента в середину связного списка
=======30
@Рис. 2.5. Удаление элемента из начала связного списка
Снова сравним этот код с кодом, который понадобился бы для выполнения той
же операции, при использовании списка на основе массива. Можно быстро
пометить удаленный элемент как неиспользуемый, но это оставляет в списке
ненужные значения. Процедуры, обрабатывающие список, должны это учитывать,
и соответственно быть более сложными. Присутствие чрезмерного количества
«мусора» также замедляет работу процедуры, и, в конце концов, придется
проводить чистку памяти.
При удалении элемента из связного списка, в нем не остается пустых
промежутков. Процедуры, которые обрабатывают список, все так же обходят
список с начала до конца, и не нуждаются в модификации.
Уничтожение связного списка
Можно предположить, что для уничтожения связного списка необходимо обойти
весь список, устанавливая значение NextCell для всех ячеек равным Nothing.
На самом деле процесс гораздо проще: только top_cell принимает значение
Nothing.
Когда программа устанавливает значение top_cell равным Nothing, счетчик
ссылок для первой ячейки становится равным нулю, и Visual Basic уничтожает
эту ячейку.
Во время уничтожения ячейки, система определяет, что в поле NextCell этой
ячейки содержится ссылка на другую ячейку. Поскольку первый объект
уничтожается, то число ссылок на второй объект уменьшается. При этом
счетчик ссылок на второй объект списка становится равным нулю, поэтому
система уничтожает и его.
Во время уничтожения второго объекта, система уменьшает число ссылок на
третий объект, и так далее до тех пор, пока все объекты в списке не будут
уничтожены. Когда в программе уже не будет ссылок на объекты списка, можно
уничтожить и весь список при помощи единственного оператора Set
top_cell = Nothing.
@Рис. 2.6. Удаление элемента из середины связного списка
========31
Сигнальные метки
Для добавления или удаления элементов из начала или середины списка
используются различные процедуры. Можно свести оба этих случая к одному и
избавиться от избыточного кода, если ввести специальную сигнальную метку
(sentinel) в самом начале списка. Сигнальную метку нельзя удалить. Она не
содержит данных и используется только для обозначения начала списка.
Теперь вместо того, чтобы обрабатывать особый случай добавления элемента в
начало списка, можно помещать элемент после метки. Таким же образом, вместо
особого случая удаления первого элемента из списка, просто удаляется
элемент, следующий за меткой.
Использование сигнальных меток пока не вносит особых различий. Сигнальные
метки играют важную роль в гораздо более сложных алгоритмах. Они позволяют
обрабатывать особые случаи, такие как начало списка, как обычные. При этом
требуется написать и отладить меньше кода, и алгоритмы становятся более
согласованными и более простыми для понимания.
В табл. 2.1 сравнивается сложность выполнения некоторых типичных операций с
использованием списков на основе массивов со «сборкой мусора» или связных
списков.
Списки на основе массивов имеют одно преимущество: они используют меньше
памяти. Для связных списков необходимо добавить поле NextCell к каждому
элементу данных. Каждая ссылка на объект занимает четыре дополнительных
байта памяти. Для очень больших массивов это может потребовать больших
затрат памяти.
Программа LnkList1 демонстрирует простой связный список с сигнальной
меткой. Введите значение в текстовое поле ввода, и нажмите на элемент в
списке или на метку. Затем нажмите на кнопку Add After (Добавить после), и
программа добавит новый элемент после указанного. Для удаления элемента из
списка, нажмите на элемент и затем на кнопку Remove After (Удалить после).
@Таблица 2.1. Сравнение списков на основе массивов и связных списков
=========32
Инкапсуляция связных списков
Программа LnkList1 управляет списком явно. Например, следующий код показывает, как программа удаляет элемент из списка. Когда подпрограмма начинает работу, глобальная переменная SelectedIndex дает положение элемента, предшествующего удаляемому элементу в списке. Переменная Sentinel содержит ссылку на сигнальную метку списка.
Private Sub CmdRemoveAfter_Click()
Dim ptr As ListCell
Dim position As Integer
If SelectedIndex < 0 Then Exit Sub
‘ Найти элемент.
Set ptr = Sentinel position = SelectedIndex
Do While position > 0 position = position - 1
Set ptr = ptr.nextCell
Loop
‘ Удалить следуюший элемент.
Set ptr.NextCell = ptr.NextCell.NextCell
NumItems = NumItems - 1
SelectItem SelectedIndex ‘ Снова выбрать элемент.
DisplayList
NewItem.SetFocus
End Sub
Чтобы упростить использование связного списка, можно инкапсулировать его
функции в классе. Это реализовано в программе LnkList2 . Она аналогична
программе LnkList1, но использует для управления списком класс LinkedList.
Класс LinekedList управляет внутренней организацией связного списка. В нем
находятся процедуры для добавления и удаления элементов, возвращения
значения элемента по его индексу, числа элементов в списке, и очистки
списка. Этот класс позволяет обращаться со связным списком почти как с
массивом.
Это намного упрощает основную программу. Например, следующий код
показывает, как программа LnkList2 удаляет элемент из списка. Только одна
строка в программе в действительности отвечает за удаление элемента.
Остальные отображают новый список. Сравните этот код с предыдущей
процедурой:
Private sub CmdRemoveAfter_Click()
Llist.RemoveAfter SelectedIndex
SelectedItem SelectedList ‘ Снова выбрать элемент.
DisplayList
NewItem.SetFocus
CmdClearList.Enabled
End Sub
=====33
Доступ к ячейкам
Класс LinkedList, используемый программой LnkLst2, позволяет основной
программе использовать список почти как массив. Например, подпрограмма
Item, приведенная в следующем коде, возвращает значение элемента по его
положению:
Function Item(ByVal position As Long) As Variant
Dim ptr As ListCell
If position < 1 Or position > m_NumItems Then
‘ Выход за границы. Вернуть NULL.
Item = Null
Exit Function
End If
‘ Найти элемент.
Set ptr = m_Sentinel
Do While position > 0 position = position - 1
Set ptr = ptr.NextCell
Loop
Item = ptr.Value
End Function
Эта процедура достаточно проста, но она не использует преимущества связной структуры списка. Например, предположим, что программе требуется последовательно перебрать все объекты в списке. Она могла бы использовать подпрограмму Item для поочередного доступа к ним, как показано в следующем коде:
Dim i As Integer
For i = 1 To LList.NumItems
‘ Выполнить какие-либо действия с LList.Item(i).
:
Next i
При каждом вызове процедуры Item, она просматривает список в поиске
следующего элемента. Чтобы найти элемент I, программа должна пропустить I-1
элементов. Чтобы проверить все элементы в списке из N элементов, процедура
пропустит 0+1+2+3+…+N-1 =N*(N-1)/2 элемента. При больших N программа
потеряет много времени на пропуск элементов.
Класс LinkedList может ускорить эту операцию, используя другой метод
доступа. Можно использовать частную переменную m_CurrentCell для
отслеживания текущей позиции в списке. Для возвращения значения текущего
положения используется подпрограмма CurrentItem. Процедуры MoveFirst,
MoveNext и EndOfList позволяют основной программе управлять текущей
позицией в списке.
=======34
Например, следующий код содержит подпрограмму MoveNext:
Public Sub MoveNext()
‘ Если текущая ячейка не выбрана, ничего не делать.
If Not (m_CurrentCell Is Nothing) Then _
Set m_CurrentCell = m_CurrentCell.NextCell
End Sub
При помощи этих процедур, основная программа может обратиться ко всем
элементам списка, используя следующий код. Эта версия несколько сложнее,
чем предыдущая, но она намного эффективнее. Вместо того чтобы пропускать
N*(N-1)/2 элементов и опрашивать по очереди все N элементов списка, она не
пропускает ни одного. Если список состоит из 1000 элементов, это экономит
почти полмиллиона шагов.
LList.MoveFirst
Do While Not LList.EndOfList
‘ Выполнить какие-либо действия над элементом LList.Item(i).
:
LList.MoveNext
Loop
Программа LnkList3 использует эти новые методы для управления связным списком. Она аналогична программе LnkList2, но более эффективно обращается к элементам. Для небольших списков, используемых в программе, эта разница незаметна. Для программы, которая обращается ко всем элементам большого списка, эта версия класса LinkedList более эффективна.
Разновидности связных списков
Связные списки играют важную роль во многих алгоритмах, и вы будете встречаться с ними на протяжении всего материала. В следующих разделах обсуждаются несколько специальных разновидностей связных списков.
Циклические связные списки
Вместо того, чтобы устанавливать указатель NextCell равным Nothing, можно
установить его на первый элемент списка, образуя циклический список
(circular list), как показано на рис. 2.7.
Циклические списки полезны, если нужно обходить ряд элементов в бесконечном
цикле. При каждом шаге цикла, программа просто перемещает указатель на
следующую ячейку в списке. Допустим, имеется циклический список элементов,
содержащий названия дней недели. Тогда программа могла бы перечислять дни
месяца, используя следующий код:
===========35
@Рис. 2.7. Циклический связный список
‘ Здесь находится код для создания и настройки списка и т.д.
:
‘ Напечатать календарь на месяц.
‘
‘ first_day — это индекс структуры, содержащей день недели для
‘ первого дня месяца. Например, месяц может начинаться
‘ в понедельник.
‘
‘ num_days — число дней в месяце.
Private Sub ListMonth(first_day As Integer, num_days As Integer)
Dim ptr As ListCell
Dim i As Integer
Set ptr = top_cell
For i = 1 to num_days
Print Format$(i) & ": " & ptr.Value
Set ptr = ptr.NextCell
Next I
End Sub
Циклические списки также позволяют достичь любой точки в списке, начав с
любого положения в нем. Это вносит в список привлекательную симметрию.
Программа может обращаться со всеми элементами списка почти одинаковым
образом:
Private Sub PrintList(start_cell As Integer)
Dim ptr As Integer
Set ptr = start_cell
Do
Print ptr.Value
Set ptr = ptr.NextCell
Loop While Not (ptr Is start_cell)
End Sub
========36
Проблема циклических ссылок
Уничтожение циклического списка требует немного больше внимания, чем
удаление обычного списка. Если вы просто установите значение переменной
top_cell равным Nothing, то программа не сможет больше обратиться к списку.
Тем не менее, поскольку счетчик ссылок первой ячейки не равен нулю, она не
будет уничтожена. На каждый элемент списка указывает какой-либо другой
элемент, поэтому ни один из них не будет уничтожен.
Это проблема циклических ссылок (circular referencing problem). Так как
ячейки указывают на другие ячейки, ни одна из них не будет уничтожена.
Программа не может получить доступ ни к одной из них, поэтому занимаемая
ими память будет расходоваться напрасно до завершения работы программы.
Проблема циклических ссылок может встретиться не только в этом случае.
Многие сети содержат циклические ссылки — даже одиночная ячейка, поле
NextCell которой указывает на саму эту ячейку, может вызвать эту проблему.
Решение ее состоит в том, чтобы разбить цепь ссылок. Например, вы можете
использовать в своей программе следующий код для уничтожения циклического
связного списка:
Set top_cell.NextCell = Nothing
Set top_cell = Nothing
Первая строка разбивает цикл ссылок. В этот момент на вторую ячейку списка не указывает ни одна переменная, поэтому система уменьшает счетчик ссылок ячейки до нуля и уничтожает ее. Это уменьшает счетчик ссылок на третий элемент до нуля, и соответственно, он также уничтожается. Этот процесс продолжается до тех пор, пока не будут уничтожены все элементы списка, кроме первого. Установка значения top_cell элемента в Nothing уменьшает его счетчик ссылок до нуля, и последняя ячейка также уничтожается.
Двусвязные списки
Во время обсуждения связных списков вы могли заметить, что большинство
операций определялось в терминах выполнения чего-либо после определенной
ячейки в списке. Если задана определенная ячейка, легко добавить или
удалить ячейку после нее или перечислить идущие за ней ячейки. Удалить саму
ячейку, вставить новую ячейку перед ней или перечислить идущие перед ней
ячейки уже не так легко. Тем не менее, небольшое изменение позволит
облегчить и эти операции.
Добавим новое поле указателя к каждой ячейке, которое указывает на
предыдущую ячейку в списке. Используя это новое поле, можно легко создать
двусвязный список (doubly linked list), который позволяет перемещаться
вперед и назад по списку. Теперь можно легко удалить ячейку, вставить ее
перед другой ячейкой и перечислить ячейки в любом направлении.
@Рис. 2.8. Двусвязный список
============37
Класс DoubleListCell, который используется для таких типов списков, может объявлять переменные так:
Public Value As Variant
Public NextCell As DoubleListCell
Public PrevCell As DoubleListCell
Часто бывает полезно сохранять указатели и на начало, и на конец
двусвязного списка. Тогда вы сможете легко добавлять элементы к любому из
концов списка. Иногда также бывает полезно размещать сигнальные метки и в
начале, и в конце списка. Тогда по мере работы со списком вам не нужно
будет заботиться о том, работаете ли вы с началом, с серединой или с концом
списка.
На рис. 2.9 показан двусвязный список с сигнальными метками. На этом
рисунке неиспользуемые указатели меток NextCell и PrevCell установлены в
Nothing. Поскольку программа опознает концы списка, сравнивая значения
указателей ячеек с сигнальными метками, и не проверяет, равны ли значения
Nothing, установка этих значений равными Nothing не является абсолютно
необходимой. Тем не менее, это признак хорошего стиля.
Код для вставки и удаления элементов из двусвязного списка подобен
приведенному ранее коду для односвязного списка. Процедуры нуждаются лишь в
незначительных изменениях для работы с указателями PrevCell.
@Рис. 2.9. Двусвязный список с сигнальными метками
Теперь вы можете написать новые процедуры для вставки нового элемента до
или после данного элемента, и процедуру удаления заданного элемента.
Например, следующие подпрограммы добавляют и удаляют ячейки из двусвязного
списка. Заметьте, что эти процедуры не нуждаются в доступе ни к одной из
сигнальных меток списка. Им нужны только указатели на узел, который должен
быть удален или добавлен и узел, соседний с точкой вставки.
Public Sub RemoveItem(ByVal target As DoubleListCell)
Dim after_target As DoubleListCell
Dim before_target As DoubleListCell
Set after_target = target.NextCell
Set before_target = target.PrevCell
Set after_target.NextCell = after_target
Set after_target.PrevCell = before_target
End Sub
Sub AddAfter (new_Cell As DoubleListCell, after_me As DoubleListCell)
Dim before_me As DoubleListCell
Set before_me = after_me.NextCell
Set after_me.NextCell = new_cell
Set new_cell.NextCell = before_me
Set before_me.PrevCell = new_cell
Set new_cell.PrevCell = after_me
End Sub
Sub AddBefore(new_cell As DoubleListCell, before_me As DoubleListCell)
Dim after_me As DoubleListCell
Set after_me = before_me.PrevCell
Set after_me.NextCell = new_cell
Set new_cell.NextCell = before_me
Set before_me.PrevCell = new_cell
Set new_cell.PrevCell = after_me
End Sub
===========39
Если снова взглянуть на рис. 2.9, вы увидите, что каждая пара соседних ячеек образует циклическую ссылку. Это делает уничтожение двусвязного списка немного более сложной задачей, чем уничтожение односвязных или циклических списков. Следующий код приводит один из способов очистки двусвязного списка. Вначале указатели PrevCell всех ячеек устанавливаются равными Nothing, чтобы разорвать циклические ссылки. Это, по существу, превращает список в односвязный. Когда ссылки сигнальных меток устанавливаются в Nothing, все элементы освобождаются автоматически, так же как и в односвязном списке.
Dim ptr As DoubleListCell
" Очистить указатели PrevCell, чтобы разорвать циклические ссылки.
Set ptr = TopSentinel.NextCell
Do While Not (ptr Is BottomSentinel)
Set ptr.PrevCell = Nothing
Set ptr = ptr.NextCell
Loop
Set TopSentinel.NextCell = Nothing
Set BottomSentinel.PrevCell = Nothing
Если создать класс, инкапсулирующий двусвязный список, то его обработчик
события Terminate сможет уничтожать список. Когда основная программа
установит значение ссылки на список равным Nothing, список автоматически
освободит занимаемую память.
Программа DblLink работает с двусвязным списком. Она позволяет добавлять
элементы до или после выбранного элемента, а также удалять выбранный
элемент.
=============39
Потоки
В некоторых приложениях бывает удобно обходить связный список не только в
одном порядке. В разных частях приложения вам может потребоваться выводить
список сотрудников по их фамилиям, заработной плате, идентификационному
номеру системы социального страхования, или специальности.
Обычный связный список позволяет просматривать элементы только в одном
порядке. Используя указатель PrevCell, можно создать двусвязный список,
который позволит перемещаться по списку вперед и назад. Этот подход можно
развить и дальше, добавив больше указателей на структуру данных, позволяя
выводить список в другом порядке.
Набор ссылок, который задает какой-либо порядок просмотра, называется
потоком (thread), а сам полученный список — многопоточным списком (threaded
list). Не путайте эти потоки с потоками, которые предоставляет система
Windows NT.
Список может содержать любое количество потоков, хотя, начиная с какого-то
момента, игра не стоит свеч. Применение потока, упорядочивающего список
сотрудников по фамилии, будет обосновано, если ваше приложение часто
использует этот порядок, в отличие от расположения по отчеству, которое
вряд ли когда будет использоваться.
Некоторые расположения не стоит организовывать в виде потоков. Например,
поток, упорядочивающий сотрудников по полу, вряд ли целесообразен потому,
что такое упорядочение легко получить и без него. Для того, чтобы составить
список сотрудников по полу, достаточно просто обойти список по любому
другому потоку, печатая фамилии женщин, а затем повторить обход еще раз,
печатая фамилии мужчин. Для получения такого расположения достаточно всего
двух проходов списка.
Сравните этот случай с тем, когда вы хотите упорядочить список сотрудников
по фамилии. Если список не включает поток фамилий, вам придется найти
фамилию, которая будет первой в списке, затем следующую и т.д. Это процесс
со сложностью порядка O(N2), который намного менее эффективен, чем
сортировка по полу со сложностью порядка O(N).
В общем случае, задание потока может быть целесообразно, если его
необходимо часто использовать, и если при необходимости получить тот же
порядок достаточно сложно. Поток не нужен, если его всегда легко создать
заново.
Программа Treads демонстрирует простой многопоточный список сотрудников.
Заполните поля фамилии, специальности, пола и номера социального
страхования для нового сотрудника. Затем нажмите на кнопку Add (Добавить),
чтобы добавить сотрудника к списку.
Программа содержит потоки, которые упорядочивают список по фамилии по
алфавиту и в обратном порядке, по номеру социального страхования и
специальности в прямом и обратном порядке. Вы можете использовать
дополнительные кнопки для выбора потока, в порядке которого программа
выводит список. На рис. 2.10 показано окно программы Threads со списком
сотрудников, упорядоченным по фамилии.
Класс ThreadedCell, используемый программой Threads, определяет следующие
переменные:
Public LastName As String
Public FirstName As String
Public SSN As String
Public Sex As String
Public JobClass As Integer
Public NextName As TreadedCell ‘ По фамилии в прямом порядке.
Public PrevName As TreadedCell ‘ По фамилии в обратном порядке.
Public NextSSN As TreadedCell ‘ По номеру в прямом порядке.
Public NextJobClass As TreadedCell ‘ По специальности в прямом
порядке.
Public PrevJobClass As TreadedCell ‘ По специальности в обратном
порядке.
Класс ThreadedList инкапсулирует многопоточный список. Когда программа
вызывает метод AddItem, список обновляет свои потоки. Для каждого потока
программа должна вставить элемент в правильном порядке. Например, для того,
чтобы вставить запись с фамилией «Смит», программа обходит список,
используя поток NextName, до тех пор, пока не найдет элемент с фамилией,
которая должна следовать за «Смит». Затем она вставляет в поток NextName
новую запись перед этим элементом.
При определении местоположения новых записей в потоке важную роль играют
сигнальные метки. Обработчик событий Class_Initialize класса ThreadedList
создает сигнальные метки на вершине и в конце списка и инициализирует их
указатели так, чтобы они указывали друг на друга. Затем значение метки в
начале списка устанавливается таким образом, чтобы оно всегда находилось до
любого значения реальных данных для всех потоков.
Например, переменная LastName может содержать строковые значения. Пустая
строка "" идет по алфавиту перед любыми действительными значениями строк,
поэтому программа устанавливает значение сигнальной метки LastName в начале
списка равным пустой строке.
Таким же образом Class_Initialize устанавливает значение данных для метки в
конце списка, превосходящее любые реальные значения во всех потоках.
Поскольку "~" идет по алфавиту после всех видимых символов ASCII, программа
устанавливает значение поля LastName для метки в конце списка равным "~".
Присваивая полю LastName сигнальных меток значения "" и "~", программа
избавляется от необходимости проверять особые случаи, когда нужно вставить
новый элемент в начало или конец списка. Любые новые действительные
значения будут находиться между значениями LastValue сигнальных меток,
поэтому программа всегда сможет определить правильное положение для нового
элемента, не заботясь о том, чтобы не зайти за концевую метку и не выйти за
границы списка.
@Рис. 2.10. Программа Threads
=====41
Следующий код показывает, как класс ThreadedList вставляет новый элемент в потоки NextName и PrevName. Так как эти потоки используют один и тот же ключ — фамилии, программа может обновлять их одновременно.
Dim ptr As ThreadedCell
Dim nxt As ThreadedCell
Dim new_cell As New ThreadedCell
Dim new_name As String
Dim next_name As String
" Записать значения новой ячейки.
With new_cell
.LastName = LastName
.FirstName = FirstName
.SSN = SSN
•Sex = Sex
.JobClass = JobClass
End With
" Определить место новой ячейки в потоке NextThread. new_name = LastName & ", " & FirstName
Set ptr = m_TopSentinel
Do
Set nxt = ptr.NextName next_name = nxt.LastName & ", " & nxt.FirstName
If next_name >= new_name Then Exit Do
Set ptr = nxt
Loop
" Вставить новую ячейку в потоки NextName и prevName.
Set new_cell.NextName = nxt
Set new_cell.PrevName = ptr
Set ptr.NextName = new_cell
Set nxt.PrevName = new_cell
Чтобы такой подход работал, программа должна гарантировать, что значения
новой ячейки лежат между значениями меток. Например, если пользователь
введет в качестве фамилии "~~", цикл выйдет за метку конца списка, т.к.
"~~" идет после "~". Затем программа аварийно завершит работу при попытке
доступа к значению nxt.LastName, если nxt было установлено равным Nothing.
========42
Другие связные структуры
Используя указатели, можно построить множество других полезных разновидностей связных структур, таких как деревья, нерегулярные массивы, разреженные массивы, графы и сети. Ячейка может содержать любое число указателей на другие ячейки. Например, для создания двоичного дерева можно использовать ячейку, содержащую два указателя, один на левого потомка, и второй – на правого. Класс BinaryCell может состоять из следующих определений:
Public LeftChild As BinaryCell
Public RightChild As BinaryCell
На рис. 2.11 показано дерево, построенное из ячеек такого типа. В 6 главе
деревья обсуждаются более подробно.
Ячейка может даже содержать коллекцию или связный список с указателями на
другие ячейки. Это позволяет программе связать ячейку с любым числом других
объектов. На рис. 2.12 приведены примеры других связных структур данных. Вы
также встретите похожие структуры далее, в особенности в 12 главе.
Псевдоуказатели
При помощи ссылок в Visual Basic можно легко создавать связные структуры,
такие как списки, деревья и сети, но ссылки требуют дополнительных
ресурсов. Счетчики ссылок и проблемы с распределением памяти замедляют
работу структур данных, построенных с использованием ссылок.
Другой стратегией, которая часто обеспечивает лучшую производительность,
является применение псевдоуказателей (fake pointers). При этом программа
создает массив структур данных. Вместо использования ссылок для связывания
структур, программа использует индексы массива. Нахождение элемента в
массиве осуществляется в Visual Basic быстрее, чем выборка его по ссылке на
объект. Это дает лучшую производительность при применении псевдоуказателей
по сравнению с соответствующими методами ссылок на объекты.
С другой стороны, применение псевдоуказателей не столь интуитивно, как
применение ссылок. Это может усложнить разработку и отладку сложных
алгоритмов, таких как алгоритмы сетей или сбалансированных деревьев.
@Рис. 2.11. Двоичное дерево
========43
@Рис. 2.12. Связные структуры
Программа FakeList управляет связным списком, используя псевдоуказатели.
Она создает массив простых структур данных для хранения ячеек списка.
Программа аналогична программе LnkList1, но использует псевдоуказатели.
Следующий код демонстрирует, как программа FakeList создает массив
клеточных структур:
" Структура данных ячейки.
Type FakeCell
Value As String
NextCell As Integer
End Type
" Массив ячеек связного списка.
Global Cells(0 To 100) As FakeCell
" Сигнальная метка списка.
Global Sentinel As Integer
Поскольку псевдоуказатели — это не ссылки, а просто целые числа, программа
не может использовать значение Nothing для маркировки конца списка.
Программа FakeList использует постоянную END_OF_LIST, значение которой
равно -32.767 для обозначения пустого указателя.
Для облегчения обнаружения неиспользуемых ячеек, программа FakeList также
использует специальный «мусорный» список, содержащий неиспользуемые ячейки.
Следующий код демонстрирует инициализацию пустого связного списка. В нем
сигнальная метка NextCell принимает значение END_OF_LIST. Затем она
помещает неиспользуемые ячейки в «мусорный» список.
========44
" Связный список неиспользуемых ячеек.
Global TopGarbage As Integer
Public Sub InitializeList()
Dim i As Integer
Sentinel = 0
Cells(Sentinel).NextCell = END_OF_LIST
" Поместить все остальные ячейки в «мусорный» список.
For i = 1 To UBound (Cells) - 1
Cells(i).NextCell = i + 1
Next i
Cells(UBound(Cells)).NextCell = END_OF_LIST
TopGarbage = 1
End Sub
При добавлении элемента к связному списку, программа использует первую доступную ячейку из «мусорного» списка, инициализирует поле ячейки Value и вставляет ячейку в список. Следующий код показывает, как программа добавляет элемент после выбранного:
Private Sub CmdAddAfter_Click()
Dim ptr As Integer
Dim position As Integer
Dim new_cell As Integer
" Найти место вставки. ptr = Sentinel position = Selectedlndex
Do While position > 0 position = position - 1 ptr = Cells(ptr).NextCell
Loop
" Выбрать новую ячейку из «мусорного» списка. new_cell = TopGarbage
TopGarbage = Cells(TopGarbage).NextCell
" Вставить элемент.
Cells (new_cell).Value = NewItem.Text
Cells(new_cell).NextCell = Cells(ptr).NextCell
Cells(ptr).NextCell = new_cell
NumItems = NumItems + 1
DisplayList
SelectItem SelectedIndex + 1 " Выбрать новый элемент.
NewItem.Text = ""
NewItem.SetFocus
CmdClearList.Enabled = True
End Sub
После удаления ячейки из списка, программа FakeList помещает удаленную ячейку в «мусорный» список, чтобы ее затем можно было легко использовать:
Private Sub CmdRemoveAfter_Click()
Dim ptr As Integer
Dim target As Integer
Dim position As Integer
If SelectedIndex < 0 Then Exit Sub
" Найти элемент. ptr = Sentinel position = SelectedIndex
Do While position > 0 position = position - 1 ptr = Cells(ptr).NextCell
Loop
" Пропустить следующий элемент. target = Cells(ptr).NextCell
Cells(ptr).NextCell = Cells(target).NextCell
NumItems = NumItems - 1
" Добавить удаленную ячейку в «мусорный» список.
Cells(target).NextCell = TopGarbage
TopGarbage = target
SelectItem Selectedlndex " Снова выбрать элемент.
DisplayList
CmdClearList.Enabled = NumItems > 0
NewItem.SetFocus
End Sub
Применение псевдоуказателей обычно обеспечивает лучшую производительность, но является более сложным. Поэтому имеет смысл сначала создать приложение, используя ссылки на объекты. Затем, если вы обнаружите, что программа значительную часть времени тратит на манипулирование ссылками, вы можете, если необходимо, преобразовать ее с использованием псевдоуказателей.
=======45-46
Резюме
Используя ссылки на объекты, вы можете создавать гибкие структуры данных,
такие как связные списки, циклические связные списки и двусвязные списки.
Эти списки позволяют легко добавлять и удалять элементы из любого места
списка.
Добавляя дополнительные ссылки к классу ячеек, можно превратить двусвязный
список в многопоточный. Развивая и дальше эти идеи, можно создавать
экзотические структуры данных, включая разреженные массивы, деревья, хэш-
таблицы и сети. Они подробно описываются в следующих главах.
========47
Глава 3. Стеки и очереди
В этой главе продолжается обсуждение списков, начатое во 2 главе, и описываются две особых разновидности списков: стеки и очереди. Стек — это список, в котором добавление и удаление элементов осуществляется с одного и того же конца списка. Очередь — это список, в котором элементы добавляются в один конец списка, а удаляются с противоположного конца. Многие алгоритмы, включая некоторые из представленных в следующих главах, используют стеки и очереди.
Стеки
Стек (stack) — это упорядоченный список, в котором добавление и удаление
элементов всегда происходит на одном конце списка. Можно представить стек
как стопку предметов на полу. Вы можете добавлять элементы на вершину и
удалять их оттуда, но не можете добавлять или удалять элементы из середины
стопки.
Стеки часто называют списками типа первый вошел — последний вышел (Last-In-
First-Out list). По историческим причинам, добавление элемента в стек
называется проталкиванием (pushing) элемента в стек, а удаление элемента из
стека — выталкиванием (popping) элемента из стека.
Первая реализация простого списка на основе массива, описанная в начале 2
главы, является стеком. Для отслеживания вершины списка используется
счетчик. Затем этот счетчик используется для вставки или удаления элемента
из вершины списка. Небольшое изменение — это новая процедура Pop, которая
удаляет элемент из списка, одновременно возвращая его значение. При этом
другие процедуры могут извлекать элемент и удалять его из списка за один
шаг. Кроме этого изменения, следующий код совпадает с кодом, приведенным во
2 главе.
Dim Stack() As Variant
Dim StackSize As Variant
Sub Push(value As Variant)
StackSize = StackSize + 1
ReDim Preserve Stack(1 To StackSize)
Stack(StackSize) = value
End Sub
Sub Pop(value As Variant) value = Stack(StackSize)
StackSize = StackSize - 1
ReDim Preserve Stack(1 To StackSize)
End Sub
=====49
Все предыдущие рассуждения о списках также относятся к этому виду
реализации стеков. В частности, можно сэкономить время, если не изменять
размер при каждом добавлении или выталкивании элемента. Программа SimList
на описанная во 2 главе, демонстрирует этот вид простой реализации списков.
Программы часто используют стеки для хранения последовательности элементов,
с которыми программа будет работать до тех пор, пока стек не опустеет.
Действия с одним из элементов может приводить к тому, что другие будут
проталкиваться в стек, но, в конце концов, они все будут удалены из стека.
В качестве простого примера можно привести алгоритм обращения порядка
элементов массива. При этом все элементы последовательно проталкиваются в
стек. Затем все элементы выталкиваются из стека в обратном порядке и
записываются обратно в массив.
Dim List() As Variant
Dim NumItems As Integer
" Инициализация массива.
:
" Протолкнуть элементы в стек.
For I = 1 To NumItems
Push List(I)
Next I
" Вытолкнуть элементы из стека обратно в массив.
For I = 1 To NumItems
Pop List(I)
Next I
В этом примере, длина стека может многократно изменяться до того, как, в
конце концов, он опустеет. Если известно заранее, насколько большим должен
быть массив, можно сразу создать достаточно большой стек. Вместо изменения
размера стека по мере того, как он растет и уменьшается, можно отвести под
него память в начале работы и уничтожить его после ее завершения.
Следующий код позволяет создать стек, если заранее известен его
максимальный размер. Процедура Pop не изменяет размер массива. Когда
программа заканчивает работу со стеком, она должна вызвать процедуру
EmptyStack для освобождения занятой под стек памяти.
======50
Const WANT_FREE_PERCENT = .1 " 10% свободного пространства.
Const MIN_FREE = 10 " Минимальный размер.
Global Stack() As Integer " Стековый массив.
Global StackSize As Integer " Размер стекового массива.
Global Lastltem As Integer " Индекс последнего элемента.
Sub PreallocateStack(entries As Integer)
StackSize = entries
ReDim Stack(1 To StackSize)
End Sub
Sub EmptyStack()
StackSize = 0
LastItem = 0
Erase Stack " Освободить память, занятую массивом.
End Sub
Sub Push(value As Integer)
LastItem = LastItem + 1
If LastItem > StackSize Then ResizeStack
Stack(LastItem) = value
End Sub
Sub Pop(value As Integer) value = Stack(LastItem)
LastItem = LastItem - 1
End Sub
Sub ResizeStack()
Dim want_free As Integer
want_free = WANT_FREE_PERCENT * LastItem
If want_free < MIN_FREE Then want_free = MIN_FREE
StackSize = LastItem + want_free
ReDim Preserve Stack(1 To StackSize)
End Sub
Этот вид реализации стеков достаточно эффективен в Visual Basic. Стек не расходует понапрасну память, и не слишком часто изменяет свой размер, особенно если сразу известно, насколько большим он должен быть.
=======51
Множественные стеки
В одном массиве можно создать два стека, поместив один в начале массива, а
другой — в конце. Для двух стеков используются отдельные счетчики длины
стека Top, и стеки растут навстречу друг другу, как показано на рис. 3.1.
Этот метод позволяет двум стекам расти, занимая одну и ту же область
памяти, до тех пор, пока они не столкнутся, когда массив заполнится.
К сожалению, менять размер этих стеков непросто. При увеличении массива
необходимо сдвигать все элементы в верхнем стеке, чтобы выделять память под
новые элементы в середине. При уменьшении массива, необходимо вначале
сдвинуть элементы верхнего стека, перед тем, как менять размер массива.
Этот метод также сложно масштабировать для оперирования более чем двумя
стеками.
Связные списки предоставляют более гибкий метод построения множественных
стеков. Для проталкивания элемента в стек, он помещается в начало связного
списка. Для выталкивания элемента из стека, удаляется первый элемент из
связного списка. Так как элементы добавляются и удаляются только в начале
списка, для реализации стеков такого типа не требуется применение
сигнальных меток или двусвязных списков.
Основной недостаток применения стеков на основе связных списков состоит в
том, что они требуют дополнительной памяти для хранения указателей
NextCell. Для стека на основе массива, содержащего N элементов, требуется
всего 2*N байт памяти (по 2 байта на целое число). Тот же стек,
реализованный на основе связного списка, потребует дополнительно 4*N байт
памяти для указателей NextCell, увеличивая размер необходимой памяти втрое.
Программа Stack использует несколько стеков, реализованных в виде связных
списков. Используя программу, можно вставлять и выталкивать элементы из
каждого из этих списков. Программа Stack2 аналогична этой программе, но она
использует класс LinkedListStack для работы со стеками.
Очереди
Упорядоченный список, в котором элементы добавляются к одному концу списка, а удаляются с другой стороны, называется очередью (queue). Группа людей, ожидающих обслуживания в магазине, образует очередь. Вновь прибывшие подходят сзади. Когда покупатель доходит до начала очереди, кассир его обслуживает. Из-за их природы, очереди иногда называют списками типа первый вошел — первый вышел (First-In-First-Out list).
@Рис. 3.1. Два стека в одном массиве
=======52
Можно реализовать очереди в Visual Basic, используя методы типа
использованных для организации простых стеков. Создадим массив, и при
помощи счетчиков будем определять положение начала и конца очереди.
Значение переменной QueueFront дает индекс элемента в начале очереди.
Переменная QueueBack определяет, куда должен быть добавлен очередной
элемент очереди. По мере того как новые элементы добавляются в очередь и
покидают ее, размер массива, содержащего очередь, изменяется так, что он
растет на одном конце и уменьшается на другом.
Global Queue() As String " Массив очереди.
Global QueuePront As Integer " Начало очереди.
Global QueueBack As Integer " Конец очереди.
Sub EnterQueue(value As String)
ReDim Preserve Queue(QueueFront To QueueBack)
Queue(QueueBack) = value
QueueBack = QueueBack + 1
End Sub
Sub LeaveQueue(value As String) value = Queue(QueueFront)
QueueFront = QueueFront + 1
ReDim Preserve Queue (QueueFront To QueueBack - 1)
End Sub
К сожалению, Visual Basic не позволяет использовать ключевое слово Preserve
в операторе ReDim, если изменяется нижняя граница массива. Даже если бы
Visual Basic позволял выполнение такой операции, очередь при этом
«двигалась» бы по памяти. При каждом добавлении или удалении элемента из
очереди, границы массива увеличивались бы. После пропускания достаточно
большого количества элементов через очередь, ее границы могли бы в конечном
итоге стать слишком велики.
Поэтому, когда требуется увеличить размер массива, вначале необходимо
переместить данные в начало массива. При этом может образоваться
достаточное количество свободных ячеек в конце массива, так что увеличение
размера массива может уже не понадобиться. В противном случае, можно
воспользоваться оператором ReDim для увеличения или уменьшения размера
массива.
Как и в случае со списками, можно повысить производительность, добавляя
сразу несколько элементов при увеличении размера массива. Также можно
сэкономить время, уменьшая размер массива, только когда он содержит слишком
много неиспользуемых ячеек.
В случае простого списка или стека, элементы добавляются и удаляются на
одном его конце. Если размер списка остается почти постоянным, его не
придется изменять слишком часто. С другой стороны, так как элементы
добавляются на одном конце очереди, а удаляются с другого конца, может
потребоваться время от времени переупорядочивать очередь, даже если ее
размер остается неизменным.
=====53
Const WANT_FREE_PERCENT = .1 " 10% свободного пространства.
Const MIN_FREE = 10 " Минимум свободных ячеек.
Global Queue() As String " Массив очереди.
Global QueueMax As Integer " Наибольший индекс массива.
Global QueueFront As Integer " Начало очереди.
Global QueueBack As Integer " Конец очереди.
Global ResizeWhen As Integer " Когда увеличить размер массива.
" При инициализации программа должна установить QueueMax = -1
" показывая, что под массив еще не выделена память.
Sub EnterQueue(value As String)
If QueueBack > QueueMax Then ResizeQueue
Queue(QueueBack) = value
QueueBack = QueueBack + 1
End Sub
Sub LeaveQueue(value As String) value = Queue(QueueFront)
QueueFront = QueueFront + 1
If QueueFront > ResizeWhen Then ResizeOueue
End Sub
Sub ResizeQueue()
Dim want_free As Integer
Dim i As Integer
" Переместить записи в начало массива.
For i = QueueFront To QueueBack - 1
Queue(i - QueueFront) = Queue(i)
Next i
QueueBack = QueueBack - QueuePront
QueueFront = 0
" Изменить размер массива. want_free = WANT_FREE_PERCENT * (QueueBack - QueueFront)
If want_free < MIN_FREE Then want_free = MIN_FREE
Max = QueueBack + want_free - 1
ReDim Preserve Queue(0 To Max)
" Если QueueFront > ResizeWhen, изменить размер массива.
ResizeWhen = want_free
End Sub
При работе с программой, заметьте, что когда вы добавляете и удаляете
элементы, требуется изменение размера очереди, даже если размер очереди
почти не меняется. Фактически, даже при неоднократном добавлении и удалении
одного элемента размер очереди будет изменяться.
Имейте в виду, что при каждом изменении размера очереди, вначале все
используемые элементы перемещаются в начало массива. При этом на изменение
размера очередей на основе массива уходит больше времени, чем на изменение
размера описанных выше связных списков и стеков.
=======54
Программа ArrayQ2 аналогична программе ArrayQ, но она использует для управления очередью класс ArrayQueue.
Циклические очереди
Очереди, описанные в предыдущем разделе, требуется переупорядочивать время
от времени, даже если размер очереди почти не меняется. Даже при
неоднократном добавлении и удалении одного элемента будет необходимо
переупорядочивать очередь.
Если заранее известно, насколько большой может быть очередь, этого можно
избежать, создав циклическую очередь (circular queue). Идея заключается в
том, чтобы рассматривать массив очереди как будто он заворачивается,
образуя круг. При этом последний элемент массива как бы идет перед первым.
На рис. 3.2 изображена циклическая очередь.
Программа может хранить в переменной QueueFront индекс элемента, который
дольше всего находится в очереди. Переменная QueueBack может содержать
конец очереди, в который добавляется новый элемент.
В отличие от предыдущей реализации, при обновлении значений переменных
QueueFront и QueueBack, необходимо использовать оператор Mod для того,
чтобы индексы оставались в границах массива. Например, следующий код
добавляет элемент к очереди:
Queue(QueueBack) = value
QueueBack = (QueueBack + 1) Mod QueueSize
На рис. 3.3 показан процесс добавления нового элемента к циклической
очереди, которая может содержать четыре записи. Элемент C добавляется в
конец очереди. Затем конец очереди сдвигается, указывая на следующую запись
в массиве.
Таким же образом, когда программа удаляет элемент из очереди, необходимо
обновлять указатель на начало очереди при помощи следующего кода:
value = Queue(QueueFront)
QueueFront = (QueueFront + 1) Mod QueueSize
@Рис. 3.2. Циклическая очередь
=======55
@Рис. 3.3. Добавление элемента к циклической очереди
На рис. 3.4 показан процесс удаления элемента из циклической очереди.
Первый элемент, в данном случае элемент A, удаляется из начала очереди, и
указатель на начало очереди обновляется, указывая на следующий элемент
массива.
Для циклических очередей иногда бывает сложно отличить пустую очередь от
полной. В обоих случаях значения переменных QueueBottom и QueueTop будут
равны. На рис. 3.5 показаны две циклические очереди, пустая и полная.
Простой вариант решения этой проблемы — сохранять число элементов в очереди
в отдельной переменной NumInQueue. При помощи этого счетчика можно узнать,
остались ли в очереди еще элементы, и осталось ли в очереди место для новых
элементов.
@Рис. 3.4. Удаление элемента из циклической очереди
@Рис. 3.5 Полная и пустая циклическая очереди
=========56
Следующий код использует все эти методы для управления циклической очередью:
Queue() As String " Массив очереди.
QueueSize As Integer " Наибольший индекс в очереди.
QueueFront As Integer " Начало очереди.
QueueBack As Integer " Конец очереди.
NumInQueue As Integer " Число элементов в очереди.
Sub NewCircularQueue(num_items As Integer)
QueueSize = num_items
ReDim Queue(0 To QueueSize - 1)
End Sub
Sub EnterQueue(value As String)
" Если очередь заполнена, выйти из процедуры.
" В настоящем приложении потребуется более сложный код.
If NumInQueue >= QueueSize Then Exit Sub
Queue(QueueBack) = value
QueueBack = (QueueBack + 1) Mod QueueSize
NumInQueue = NumInQueue + 1
End Sub
Sub LeaveQueue (value As String)
" Если очередь пуста, выйти из процедуры.
" В настоящем приложении потребуется более сложный код.
If NumInQueue = QueueSize Then ResizeQueue
Queue(QueueBack) = value
QueueBack = (QueueBack + 1) Mod QueueSize
NumInQueue = NumInQueue + 1
End Sub
Private Sub LeaveQueue(value As String)
If NumInQueue new_priority cell = nxt nxt = cell.NextCell
Loop
" Вставить элемент после ячейки в списке.
:
Для удаления из списка элемента с наивысшим приоритетом, просто удаляется
элемент после сигнальной метки начала. Так как список отсортирован в
порядке приоритетов, первый элемент всегда имеет наивысший приоритет.
Добавление нового элемента в эту очередь занимает в среднем N/2 шагов.
Иногда новый элемент будет оказываться в начале списка, иногда ближе к
концу, но в среднем он будет оказываться где-то в середине. Простая очередь
на основе списка требовала O(1) шагов для добавления нового элемента и O(N)
шагов для удаления элементов с наивысшим приоритетом из очереди. Версия на
основе упорядоченного связного списка требует O(N) шагов для добавления
элемента и O(1) шагов для удаления верхнего элемента. Обеим версиям требует
O(N) шагов для одной из этих операций, но в случае упорядоченного связного
списка в среднем требуется только (N/2) шагов.
Программа PriList использует упорядоченный связный список для работы с
приоритетной очередью. Вы можете задать приоритет и значение элемента
данных и нажать кнопку Enter для добавления его в приоритетную очередь.
Нажмите на кнопку Leave для удаления из очереди элемента с наивысшим
приоритетом.
Программа PriList2 аналогична программе PriList, но она использует для
управления очередью класс LinkedPriorityQueue.
========63
Затратив еще немного усилий, можно построить приоритетную очередь, в
которой добавление и удаление элемента потребуют порядка O(log(N)) шагов.
Для очень больших очередей, ускорение работы может стоить этих усилий. Этот
тип приоритетных очередей использует структуры данных в виде пирамиды,
которые также применяются в алгоритме пирамидальной сортировки. Пирамиды и
приоритетные очереди на их основе обсуждаются более подробно в 9 главе.
Многопоточные очереди
Интересной разновидностью очередей являются многопоточные очереди (multi-
headed queues). Элементы, как обычно, добавляются в конец очереди, но
очередь имеет несколько потоков (front end) или голов (heads). Программа
может удалять элементы из любого потока.
Примером многопоточной очереди в обычной жизни является очередь клиентов в
банке. Все клиенты находятся в одной очереди, но их обслуживает несколько
служащих. Освободившийся банковский работник обслуживает клиента, который
находится в очереди первым. Такой порядок обслуживания кажется
справедливым, поскольку клиенты обслуживаются в порядке прибытия. Он также
эффективен, так как все служащие остаются занятыми до тех пор, пока клиенты
ждут в очереди.
Сравните этот тип очереди с несколькими однопоточными очередями в
супермаркете, в которых покупатели не обязательно обслуживаются в порядке
прибытия. Покупатель в медленно движущейся очереди, может прождать дольше,
чем тот, который подошел позже, но оказался в очереди, которая продвигается
быстрее. Кассиры также могут быть не всегда заняты, так как какая-либо
очередь может оказаться пустой, тогда как в других еще будут находиться
покупатели.
В общем случае, многопоточные очереди более эффективны, чем несколько
однопоточных очередей. Последний вариант используется в супермаркетах
потому, что тележки для покупок занимают много места. При использовании
многопоточной очереди всем покупателям пришлось бы построиться в одну
очередь. Когда кассир освободится, покупателю пришлось бы переместиться с
громоздкой тележкой к кассиру. С другой стороны, в банке посетителям не
нужно двигать большие тележки для покупок, поэтому они легко могут
уместиться в одной очереди.
Очереди на регистрацию в аэропорту иногда представляют собой комбинацию
этих двух ситуаций. Хотя пассажиры имеют с собой большое количество багажа,
в аэропорту все-таки используются многопоточные очереди, при этом
приходится отводить дополнительное место, чтобы пассажиры могли выстроиться
в порядке очереди.
Многопоточную очередь просто построить, используя обычную однопоточную
очередь. Элементы, представляющие клиентов, хранятся в обычной однопоточной
очереди. Когда агент (кассир, банковский служащий и т.д.) освобождается,
первый элемент в начале очереди удаляется и передается этому агенту.
Модель очереди
Предположим, что вы отвечаете за разработку счетчика регистрации для нового терминала в аэропорту и хотите сравнить возможности одной многопоточной очереди или нескольких однопоточных. Вам потребуется какая-то модель поведения пассажиров. Для этого примера можно сделать следующие предположения:
=====63
1. регистрация каждого пассажира занимает от двух до пяти минут;
2. при использовании нескольких однопоточных очередей, прибывающие пассажиры встают в самую короткую очередь;
3. скорость поступления пассажиров примерно неизменна.
Программа HeadedQ моделирует эту ситуацию. Вы можете менять некоторые
параметры модели, включая следующие:
4. число прибывающих в течение часа пассажиров;
5. минимальное и максимальное затрачиваемое время;
6. число свободных служащих;
7. паузу между шагами программы в миллисекундах.
При выполнении программы, модель показывает прошедшее время, среднее и
максимальное время ожидания пассажирами обслуживания, и процент времени, в
течение которого служащие заняты.
При экспериментировании с различными значениями параметров, вы заметите
несколько любопытных моментов. Во-первых, для многопоточной очереди среднее
и максимальное время ожидания будет меньше. При этом, служащие также
оказываются немного более загружены, чем в случае однопоточной очереди.
Для обоих типов очереди есть порог, при котором время ожидания пассажиров
значительно возрастает. Предположим, что на обслуживание одного пассажира
требуется от 2 до 10 минут, или в среднем 6 минут. Если поток пассажиров
составляет 60 человек в час, тогда персонал потратит около 6*60=360 минут в
час на обслуживание всех пассажиров. Разделив это значение на 60 минут в
часе, получим, что для обслуживания клиентов в этом случае потребуется 6
клерков.
Если запустить программу HeadedQ с этими параметрами, вы увидите, что
очереди движутся достаточно быстро. Для многопоточной очереди время
ожидания составит всего несколько минут. Если добавить еще одного
служащего, чтобы всего было 7 служащих, среднее и максимальное время
ожидания значительно уменьшатся. Среднее время ожидания упадет примерно до
одной десятой минуты.
С другой стороны, если уменьшить число служащих до 5, это приведет к
большому увеличению среднего и максимального времени ожидания. Эти
показатели также будут расти со временем. Чем дольше будет работать
программа, тем дольше будут задержки.
@Таблица 3.1. Время ожидания в минутах для одно- и многопоточных очередей
======64
@Рис. 3.9. Программа HeadedQ
В табл. 3.1 приведены среднее и максимальное время ожидания для 2 разных
типов очередей. Программа моделирует работу в течение 3 часов и
предполагает, что прибывает 60 пассажиров в час и на обслуживание каждого
из них уходит от 2 до 10 минут.
Многопоточная очередь также кажется более справедливой, так как пассажиры
обслуживаются в порядке прибытия. На рис. 3.9 показана программа HeadedQ
после моделирования чуть более, чем двух часов работы терминала. В
многопоточной очереди первым стоит пассажир с номером 104. Все пассажиры,
прибывшие до него, уже обслужены или обслуживаются в настоящий момент. В
однопоточной очереди, обслуживается пассажир с номером 106. Пассажиры с
номерами 100, 102, 103 и 105 все еще ждут своей очереди, хотя они и прибыли
раньше, чем пассажир с номером 106.
Резюме
Разные реализации стеков и очередей обладают различными свойствами. Стеки и
циклические очереди на основе массивов просты и эффективны, в особенности,
если заранее известно насколько большим может быть их размер. Связные
списки обеспечивают большую гибкость, если размер списка часто изменяется.
Стеки и очереди на основе коллекций Visual Basic не так эффективны, как
реализации на основе массивов, но они очень просты. Коллекции могут подойти
для небольших структур данных, если производительность не критична. После
тестирования приложения, можно переписать код для стека или очереди, если
коллекции окажутся слишком медленными.
Глава 4. Массивы
В этой главе описаны структуры данных в виде массивов. С помощью Visual
Basic вы можете легко создавать массивы данных стандартных или определенных
пользователем типов. Если определить массив без границ, затем можно
изменять его размер при помощи оператора ReDim. Эти свойства делают
применение массивов в Visual Basic очень полезным.
Некоторые программы используют особые типы массивов, которые не
поддерживаются Visual Basic непосредственно. К этим типа относятся
треугольные массивы, нерегулярные массивы и разреженные массивы. В этой
главе объясняется, как можно использовать гибкие структуры массивов,
которые могут значительно снизить объем занимаемой памяти.
Треугольные массивы
Некоторым программам требуется только половина элементов в двумерном
массиве. Предположим, что мы располагаем картой, на которой 10 городов
обозначены цифрами от 0 до 9. Можно использовать массив для создания
матрицы смежности (adjacency matrix), показывающей наличие автострады между
парами городов. Элемент A(I,J) равен True, если между городами I и J есть
автострада.
В этом случае, значения в половине матрицы будут дублировать значения в
другой ее половине, так как A(I, J)=A(J, I). Также элемент A(I, I) не имеет
смысла, так как бессмысленно строить автостраду из города I в тот же самый
город. В действительности потребуются только элементы A(I,J) из верхнего
левого угла, для которых I > J. Вместо этого можно также использовать
элементы из верхнего правого угла. Поскольку эти элементы образуют
треугольник, этот тип массивов называется треугольным массивом (triangular
array).
На рис. 4.1 показан треугольный массив. Элементы со значащими данными
обозначены буквой X, ячейки, соответствующие дублирующимся элементам,
оставлены пустыми. Незначащие элементы A(I,I) обозначены тире.
Для небольших массивов потери памяти при использовании обычных двумерных
массивов для хранения таких данных не слишком существенны. Если же на карте
много городов, потери памяти могут быть велики. Для N городов эти потери
составят N*(N-1)/2 дублирующихся элементов и N незначащих диагональных
элементов A(I,I). Если карта содержит 1000 городов, в массиве будет более
полумиллиона ненужных элементов.
====67
@Рис. 4.1. Треугольный массив
Избежать потерь памяти можно, создав одномерный массив B и упаковав в него
значащие элементы из массива A. Разместим элементы в массиве B по строкам,
как показано на рис. 4.2. Заметьте, что индексы массивов начинаются с нуля.
Это упрощает последующие уравнения.
Для того, чтобы упростить использование этого представления треугольного
массива, можно написать функции для преобразования индексов массивов A и B.
Уравнение для преобразования индекса A(I,J) в B(X) выглядит так:
X = I * (I - 1) / 2 + J " Для I > J.
Например, для I=2 и J=1 получим X = 2 * (2 - 1) / 2 + 1 = 2. Это значит,
что A(2,1) отображается на 2 позицию в массиве B, как показано на рис. 4.2.
Помните, что массивы нумеруются с нуля.
Уравнение остается справедливым только для I > J. Значения других элементов
массива A не сохраняются в массиве B, потому что они являются избыточными
или незначащими. Если вам нужно получить значение A(I,J) при I < J, вместо
этого следует вычислять значение A(J,I).
Уравнения для обратного преобразования B(X) в A(I,J) выглядит так:
I = Int((1 + Sqr(1 + 8 * X)) / 2)
J = X - I * (I - 1) / 2
@Рис. 4.2. Упаковка треугольного массива в одномерном массиве
=====68
Подстановка в эти уравнения X=4 дает I = Int((1 + Sqr(1 + 8 * 4)) / 2) = 3
и J = 4 – 3 * (3 - 1) / 2 = 1. Это означает, что элемент B(4) отображается
на позицию A(3,1). Это также соответствует рис. 4.2.
Эти вычисления не слишком просты. Они требуют нескольких умножений и
делений, и даже вычисления квадратного корня. Если программе придется
выполнять эти функции очень часто, это внесет определенную задержку
скорости выполнения. Это пример компромисса между пространством и временем.
Упаковка треугольного массива в одномерный массив экономит память, хранение
данных в двумерном массиве требует больше памяти, но экономит время.
Используя эти уравнения, можно написать процедуры Visual Basic для
преобразования координат между двумя массивами:
Private Sub AtoB(ByVal I As Integer, ByVal J As Integer, X As Integer)
Dim tmp As Integer
If I = J Then " Незначащий элемент.
X = -1
Exit Sub
ElseIf I < J Then " Поменять местами I и J. tmp = I
I = J
J = tmp
End If
X = I * (I - 1) / 2 + J
End Sub
Private Sub BtoA(ByVal X As Integer, I As Integer, J As Integer)
I = Int((1 + Sqr(1 + 8 * X)) / 2)
J = X - I * (I - 1) /2
End Sub
Программа Triang использует эти подпрограммы для работы с треугольными
массивами. Если вы нажмете на кнопку A to B (Из A в B), программа пометит
элементы в массиве A и скопирует эти метки в соответствующие элементы
массива B. Если вы нажмете на кнопку B to A (Из B в A), программа пометит
элементы в массиве B, и затем скопирует метки в массив A.
Программа Triangc использует класс TriangularArray для работы с треугольным
массивом. При старте программы, она записывает в объект TriangularArray
строки, представляющие собой элементы массива. Затем она извлекает и
выводит на экран элементы массива.
Диагональные элементы
Некоторые программы используют треугольные массивы, которые включают
диагональные элементы A(I, I). В этом случае необходимо внести только три
изменения в процедуры преобразования индексов. Процедура преобразования
AtoB не должна пропускать случаи с I=J, и должна добавлять к I единицу при
подсчете индекса массива B.
=====69
Private Sub AtoB(ByVal I As Integer, ByVal J As Integer, X As Integer)
Dim tmp As Integer
If I < J Then " Поменять местами I и J. tmp = I
I = J
J = tmp
End If
I = I + 1
X = I * (I - 1) / 2 + J
End Sub
Процедура преобразования BtoA должна вычитать из I единицу перед возвратом значения.
Private Sub BtoA(ByVal X As Integer, I As Integer, J As Integer)
I = Int((1 + Sqr(1 + 8 * X)) / 2)
J = X - I * (I - 1) / 2
I = J - 1
End Sub
Программа Triang2 аналогична программе Triang, но она использует для работы
с диагональными элементами в массиве A эти новые функции. Программа
TriangC2 аналогична программе TriangC, но использует класс TriangularArray,
который включает диагональные элементы.
Нерегулярные массивы
В некоторых программах нужны массивы нестандартного размера и формы.
Двумерный массив может содержать шесть элементов в первом ряду, три — во
втором, четыре — в третьем, и т.д. Это может понадобиться, например, для
сохранения ряда многоугольников, каждый из которых состоит из разного числа
точек. Массив будет при этом выглядеть, как на рис. 4.3.
Массивы в Visual Basic не могут иметь такие неровные края. Можно было бы
использовать массив, достаточно большой для того, чтобы в нем могли
поместиться все строки, но при этом в таком массиве было бы множество
неиспользуемых ячеек. Например, массив на рис. 4.3 мог бы быть объявлен при
помощи оператора Dim Polygons(1 To 3, 1 To 6), и при этом четыре ячейки
останутся неиспользованными.
Существует несколько способов представления нерегулярных массивов.
@Рис. 4.3. Нерегулярный массив
=====70
Прямая звезда
Один из способов избежать потерь памяти заключается в том, чтобы упаковать
данные в одномерном массиве B. В отличие от треугольных массивов, для
нерегулярных массивов нельзя записать формулы для определения соответствия
элементов в разных массивах. Чтобы справиться с этой задачей, можно создать
еще один массив A со смещениями для каждой строки в одномерном массиве B.
Для упрощения определения в массиве B положения точек, соответствующих
каждой строке, в конец массива A можно добавить сигнальную метку, которая
указывает на точку сразу за последним элементом в массиве B. Тогда точки,
образующие многоугольник I, занимают в массиве B позиции с A(I) до A(I+1)-
1. Например, программа может перечислить элементы, образующие строку I,
используя следующий код:
For J = A(I) To A(I + 1) - 1
‘ Внести в список элемент I.
:
Next J
Этот метод называется прямой звездой (forward star). На рис. 4.4 показано
представление нерегулярного массива с рис. 4.3 в виде прямой звезды.
Сигнальная метка закрашена серым цветом.
Этот метод можно легко обобщить для создания многомерных нерегулярных
массивов. Для хранения набора рисунков, каждый из которых состоит из
разного числа многоугольников, можно использовать трехмерную прямую звезду.
На рис. 4.5 схематически представлена трехмерная структура данных в виде
прямой звезды. Две сигнальных метки закрашены серым цветом. Они указывают
на одну позицию позади значащих данных в массиве.
Такое представление в виде прямой звезды требует очень небольших затрат
памяти. Только память, занимаемая сигнальными метками, расходуется
«впустую».
При использовании структуры данных прямой звезды легко и быстро можно
перечислить точки, образующие многоугольник. Так же просто сохранять такие
данные на диске и загружать их обратно в память. С другой стороны,
обновлять массивы, записанные в формате прямой звезды, очень сложно.
Предположим, вы хотите добавить новую точку к первому многоугольнику на
рис. 4.4. Для этого понадобится сдвинуть все элементы справа от новой точки
на одну позицию, чтобы освободить место для нового элемента. Затем нужно
добавить по единице ко всем элементам массива A, которые идут после
первого, чтобы учесть сдвиг, вызванный добавлением точки. И, наконец, надо
вставить новый элемент. Сходные проблемы возникают при удалении точки из
первого многоугольника.
@Рис. 4.4. Представления нерегулярного массива в виде прямой звезды
=====71
@Рис. 4.5. Трехмерная прямая звезда
На рис. 4.6 показано представление в виде прямой звезды с рис. 4.4 после добавления одной точки к первому многоугольнику. Элементы, которые были изменены, закрашены серым цветом. Как видно из рисунка, почти все элементы в обоих массивах были изменены.
Нерегулярные связные списки
Другим методом создания нерегулярных массивов является использование
связных списков. Каждая ячейка содержит указатель на следующую ячейку на
том же уровне иерархии, и указатель на список ячеек на более низком уровне
иерархии. Например, ячейка многоугольника может содержать указатель на
следующий многоугольник и указатель на ячейку, содержащую координаты первой
точки.
Следующий код приводит определения переменных для классов, которые можно
использовать для создания связного списка рисунков. Каждый из рисунков
содержит связный список многоугольников, каждый из которых содержит связный
список точек.
В классе PictureCell:
Dim NextPicture As PictureCell " Следующий рисунок.
Dim FirstPolygon As PolyfonCell " Первый многоугольник на этом рисунке.
В классе PolygonCell:
Dim NextPolygon As PolygonCell " Следующий многоугольник.
Dim FirstPoint As PointCell " Первая точка в этом многоугольнике.
В классе PointCell:
@Рис. 4.6. Добавление точки к прямой звезде
======72
Dim NextPoint As PointCell " Следующая точка в этом многоугольнике.
Dim X As Single " Координаты точки.
Dim Y As Single
Используя эти методы, можно легко добавлять и удалять рисунки,
многоугольники или точки в любом месте структуры данных.
Программа Poly на диске содержит связный список многоугольников. Каждый
многоугольник содержит связный список точек. Когда вы закрываете форму,
ссылка на список многоугольников из формы уничтожается. Это уменьшает
счетчик ссылок на верхнюю ячейку многоугольников до нуля. Она уничтожается,
поэтому ее ссылки на следующий многоугольник и его первую точку также
уничтожаются. Счетчики ссылок на эти ячейки также уменьшаются до нуля, и
они тоже уничтожаются. Уничтожение каждой ячейки многоугольника или точки
приводит к уничтожению следующей ячейки. Этот процесс продолжается до тех
пор, пока все многоугольники и точки не будут уничтожены.
Разреженные массивы
Во многих приложениях требуются большие массивы, которые содержат лишь
небольшое число ненулевых элементов. Матрица смежности для авиалиний,
например, может содержать 1 в позиции A(I, J) если есть рейс между городами
I и J. Многие авиалинии обслуживают сотни городов, но число существующих
рейсов намного меньше, чем N2 возможных комбинаций. На рис. 4.8 показана
небольшая карта рейсов авиалинии, на которой изображены только 11
существующих рейсов из 100 возможных пар сочетаний городов.
@Рис. 4.7. Программа Poly
====73
@Рис. 4.8. Карта рейсов авиалинии
Можно построить матрицу смежности для этого примера при помощи массива 10
на 10 элементов, но этот массив будет по большей части пустым. Можно
избежать потерь памяти, используя для создания разреженного массива
указатели. Каждая ячейка содержит указатели на следующий элемент в строке и
столбце массива. Это позволяет программе определить положение любого
элемента в массиве и обходить элементы в строке или столбце. В зависимости
от приложения, может оказаться полезным также добавить обратные указатели.
На рис. 4.9 показана разреженная матрица смежности, соответствующая карте
рейсов с рис. 4.8.
Чтобы построить разреженный массив в Visual Basic, создайте класс для
представления элементов массива. В этом случае, каждая ячейка представляет
наличие рейсов между двумя городами. Для представления связи, класс должен
содержать переменные с индексами городов, которые связаны между собой. Эти
индексы, в сущности, дают номера строк и столбцов ячейки. Каждая ячейка
также должна содержать указатели на следующую ячейку в строке и столбце.
Следующий код показывает объявление переменных в классе ConnectionCell:
Public FromCity As Integer " Строка ячейки.
Public ToCity As Integer " Столбец ячейки.
Public NextInRow As ConnectionCell
Public NextInCol As ConnectionCell
Строки и столбцы в этом массиве по существу представляют собой связные
списки. Как это часто случается со связными списками, с ними проще
работать, если они содержат сигнальные метки. Например, переменная
RowHead(I) должна содержать сигнальную метку для строки I. Для обхода
строки I в массиве можно использовать следующий код:
Private Sub PrintRow(I As Integer)
Dim cell As ConnectionCell
Set Cell = RowHead(I).Next " Первый элемент данных.
Do While Not (cell Is Nothing)
Print Format$(cell.FromCity) & " -> " & Format$(cell.ToCity)
Set cell = cell.NextInRow
Loop
End Sub
====74
@Рис. 4.9. Разреженная матрица смежности
Индексирование массива
Нормальное индексирование массива типа A(I, J) не будет работать с такими
структурами. Можно облегчить индексирование, написав процедуры, которые
извлекают и устанавливают значения элементов массива. Если массив
представляет матрицу, могут также понадобиться процедуры для сложения,
умножения, и других матричных операций.
Специальное значение NoValue представляет пустой элемент массива.
Процедура, которая извлекает элементы массива, должна возвращать значение
NoValue при попытке получить значение элемента, не содержащегося в массиве.
Аналогично, процедура, которая устанавливает значения элементов, должна
удалять ячейку из массива, если ее значение установлено в NoValue.
Значение NoValue должно выбираться в зависимости от природы данных
приложения. Для матрицы смежности авиалинии пустые ячейки могут иметь
значение False. При этом значение A(I, J) может устанавливаться равным
True, если существует рейс между городами I и J.
Класс SparseArray определяет процедуру get для свойства Value для
возвращения значения элемента в массиве. Процедура начинает с первой ячейки
в указанной строке и затем перемещается по связному списку ячеек строки.
Как только найдется ячейка с нужным номером столбца, это и будет искомая
ячейка. Так как ячейки в списке строки расположены по порядку, процедура
может остановиться, если найдется ячейка, номер столбца которой больше
искомого.
=====75
Property Get Value(t As Integer, c As Integer) As Variant
Dim cell As SparseArrayCell
Value = NoValue " Предположим, что мы не найдем элемент.
If r < 1 Or c < 1 Or _ r > NumRows Or c > NumCols _
Then Exit Property
Set cell = RowHead(r).NextInRow " Пропустить метку.
Do
If cell Is Nothing Then Exit Property " Не найден.
If cell.Col > c Then Exit Property " Не найден.
If cell.Col = c Then Exit Do " Найден.
Set cell = cell.NextInRow
Loop
Value = cell. Data
End Property
Процедура let свойства value присваивает ячейке новое значение. Если новое
значение равно NoValue, процедура вызывает для удаления элемента из
массива. В противном случае, она ищет требуемое положение элемента в нужной
строке. Если элемент уже существует, процедура обновляет его значение.
Иначе, она создает новый элемент и добавляет его к списку строки. Затем она
добавляет новый элемент в правильное положение в соответствующем списке
столбцов.
Property Let Value (r As Integer, c As Integer, new_value As Variant)
Dim i As Integer
Dim found_it As Boolean
Dim cell As SparseArrayCell
Dim nxt As SparseArrayCell
Dim new_cell As SparseArrayCell
" Если value = MoValue, удалить элемент из массива.
If new_value = NoValue Then
RemoveEntry r, c
Exit Property
End If
" Если нужно, добавить строки.
If r > NumRows Then
ReDim Preserve RowHead(1 To r)
" Инициализировать метку для каждой новой строки.
For i = NumRows + 1 To r
Set RowHead(i) = New SparseArrayCell
Next i
End If
" Если нужно, добавить столбцы.
If c > NumCols Then
ReDim Preserve ColHead(1 To c)
" Инициализировать метку для каждой новой строки.
For i = NumCols + 1 To c
Set ColHead(i) = New SparseArrayCell
Next i
NumCols = c
End If
" Попытка найти элемент.
Set cell = RowHead(r)
Set nxt = cell.NextInRow
Do
If nxt Is Nothing Then Exit Do
If nxt.Col >= c Then Exit Do
Set cell = nxt
Set nxt = cell.NextInRow
Loop
" Проверка, найден ли элемент.
If nxt Is Nothing Then found_it = False
Else found_it = (nxt.Col = c)
End If
" Если элемент не найден, создать его.
If Not found_it Then
Set new_cell = New SparseArrayCell
" Поместить элемент в список строки.
Set new_cell.NextInRow = nxt
Set cell.NextInRow = new_cell
" Поместить элемент в список столбца.
Set cell = ColHead(c)
Set nxt = cell.NextInCol
Do
If nxt Is Nothing Then Exit Do
If nxt.Col >= c Then Exit Do
Set cell = nxt
Set nxt = cell.NextInRow
Loop
Set new_cell.NextInCol = nxt
Set cell.NextInCol = new_cell new_cell.Row = r new_cell.Col = c
" Поместим значение в элемент nxt.
Set nxt = new_cell
End If
" Установим значение. nxt.Data = new_value
End Property
Программа Sparse, показанная на рис. 4.10, использует классы SparseArray и
SparseArrayCell для работы с разреженным массивом. Используя программу,
можно устанавливать и извлекать элементы массива. В этой программе значение
NoValue равно нулю, поэтому если вы установите значение элемента равным
нулю, программа удалит этот элемент из массива.
Очень разреженные массивы
Некоторые массивы содержат так мало непустых элементов, что многие строки и столбцы полностью пусты. В этом случае, лучше хранить заголовки строк и столбцов в связных списках, а не в массивах. Это позволяет программе полностью пропускать пустые строки и столбцы. Заголовки строки и столбцов указывают на связные списки элементов строк и столбцов. На рис. 4.11 показан массив 100 на 100, который содержит всего 7 непустых элементов.
@Рис. 4.10. Программа Sparse
=====76-78
@Рис. 4.11. Очень разреженный массив
Для работы с массивами этого типа можно довольно просто доработать
предыдущий код. Большая часть кода остается неизменной, и для элементов
массива можно использовать тот же самый класс SparseArray.Тем не менее,
вместо хранения меток строк и столбцов в массивах, они записываются в
связных списках.
Объекты класса HeaderCell представляют связные списки строк и столбцов. В
этом классе определяются переменные, содержащие число строк и столбцов,
которые он представляет, сигнальная метка в начале связного списка
элементов строк или столбцов, и объект HeaderCell, представляющий следующий
заголовок строки или столбца.
Public Number As Integer " Номер строки или столбца.
Public Sentinel As SparseArrayCell " Метка для строки или
" столбца.
Public NextHeader As HeaderCell " Следующая строка или
" столбец.
Например, чтобы обратиться к строке I, нужно вначале просмотреть связный список заголовков HeaderCells строк, пока не найдется заголовок, соответствующий строке I. Затем продолжается работа со строкой I.
Private Sub PrintRow(r As Integer)
Dim row As HeaderCell
Dim cell As SparseArrayCell
" Найти правильный заголовок строки.
Set row = RowHead. NextHeader " Список первой строки.
Do
If row Is Nothing Then Exit Sub " Такой строки нет.
If row.Number > r Then Exit Sub " Такой строки нет.
If row.Number = r Then Exit Do " Строка найдена.
Set row = row.NextHeader
Loop
" Вывести элементы в строке.
Set cell = row.Sentinel. NextInRow " Первый элемент в строке.
Do While Not (cell Is Nothing)
Print Format$(cell.FromCity) & " -> " & Format$(cell.ToCity)
Set cell = cell.NextInRow
Loop
End Sub
Резюме
Некоторые программы используют массивы, содержащие только небольшое число значащих элементов. Использование обычных массивов Visual Basic привело бы к большим потерям памяти. Используя треугольные, нерегулярные, разреженные и очень разреженные массивы, вы можете создавать мощные представления массивов, которые требуют намного меньших объемов памяти.
=========80
Глава 5. Рекурсия
Рекурсия — мощный метод программирования, который позволяет разбить задачу на части все меньшего и меньшего размера до тех пор, пока они не станут настолько малы, что решение этих подзадач сведется к набору простых операций.
После того, как вы приобретете опыт применения рекурсии, вы будете обнаруживать ее повсюду. Многие программисты, недавно овладевшие рекурсией, увлекаются, и начинают применять ее в ситуациях, когда она является ненужной, а иногда и вредной.
В первых разделах этой главы обсуждается вычисление факториалов, чисел
Фибоначчи, и наибольшего общего делителя. Все эти алгоритмы являются
примерами плохого использования рекурсии — нерекурсивные версии этих
алгоритмов намного эффективнее. Эти примеры интересны и наглядны, поэтому
имеет смысл обсудить их.
Затем, в главе рассматривается несколько примеров, в которых применение рекурсии более уместно. Алгоритмы построения кривых Гильберта и Серпинского используют рекурсию правильно и эффективно.
В последних разделах этой главы объясняется, почему реализацию алгоритмов вычисления факториалов, чисел Фибоначчи, и наибольшего общего делителя лучше осуществлять без применения рекурсии. В этих параграфах объясняется также, когда следует избегать рекурсии, и приводятся способы устранения рекурсии, если это необходимо.
Что такое рекурсия?
Рекурсия происходит, если функция или подпрограмма вызывает сама себя.
Прямая рекурсия (direct recursion) выглядит примерно так:
Function Factorial(num As Long) As Long
Factorial = num * Factorial(num - 1)
End Function
В случае косвенной рекурсии (indirect recursion) рекурсивная процедура вызывает другую процедуру, которая, в свою очередь, вызывает первую:
Private Sub Ping(num As Integer)
Pong(num - 1)
End Sub
Private Sub Pong(num As Integer)
Ping(num / 2)
End Sub
===========81
Рекурсия полезна при решении задач, которые естественным образом
разбиваются на несколько подзадач, каждая из которых является более простым
случаем исходной задачи. Можно представить дерево на рис. 5.1 в виде
«ствола», на котором находятся два дерева меньших размеров. Тогда можно
написать рекурсивную процедуру для рисования деревьев:
Private Sub DrawTree()
Нарисовать "ствол"
Нарисовать дерево меньшего размера, повернутое на -45 градусов
Нарисовать дерево меньшего размера, повернутое на 45 градусов
End Sub
Хотя рекурсия и может упростить понимание некоторых проблем, люди обычно
не мыслят рекурсивно. Они обычно стремятся разбить сложные задачи на задачи
меньшего объема, которые могут быть выполнены последовательно одна за
другой до полного завершения. Например, чтобы покрасить изгородь, можно
начать с ее левого края и продолжать двигаться вправо до завершения.
Вероятно, во время выполнения подобной задачи вы не думаете о возможности
рекурсивной окраски — вначале левой половины изгороди, а затем рекурсивно —
правой.
Для того чтобы думать рекурсивно, нужно разбить задачу на подзадачи, которые затем можно разбить на подзадачи меньшего размера. В какой-то момент подзадачи становятся настолько простыми, что могут быть выполнены непосредственно. Когда завершится выполнение подзадач, большие подзадачи, которые из них составлены, также будут выполнены. Исходная задача окажется выполнена, когда будут все выполнены образующие ее подзадачи.
Рекурсивное вычисление факториалов
Факториал числа N записывается как N! (произносится «эн факториал»). По определению, 0! равно 1. Остальные значения определяются формулой:
N! = N * (N - 1) * (N - 2) * ... * 2 * 1
Как уже упоминалось в 1 главе, эта функция чрезвычайно быстро растет с увеличением N. В табл. 5.1 приведены 10 первых значений функции факториала.
Можно также определить функцию факториала рекурсивно:
0! = 1
N! = N * (N - 1)! для N > 0.
@Рис. 5.1. Дерево, составленное из двух деревьев меньшего размера
===========82
@Таблица 5.1. Значения функции факториала
Легко написать на основе этого определения рекурсивную функцию:
Public Function Factorial(num As Integer) As Integer
If num = 2 * Fib(N) - 1
С точностью до порядка это составит O(Fib(N)). Интересно, что эта функция
не только рекурсивная, но она также используется для оценки времени ее
выполнения.
Чтобы помочь вам представить скорость роста функции Фибоначчи, можно
показать, что Fib(M)>(M-2 где ( — константа, примерно равная 1,6. Это
означает, что время выполнения не меньше, чем значение экспоненциальной
функции O((M). Как и другие экспоненциальные функции, эта функция растет
быстрее, чем полиномиальные функции, но медленнее, чем функция факториала.
Поскольку время выполнения растет очень быстро, этот алгоритм довольно
медленно выполняется для больших входных значений. Фактически, настолько
медленно, что на практике почти невозможно вычислить значения функции
Fib(N) для N, которые намного больше 30. В табл. 5.4 показано время
выполнения для этого алгоритма на компьютере с процессором Pentium с
тактовой частотой 90 МГц при разных входных значениях.
Программа Fibo использует этот рекурсивный алгоритм для вычисления чисел
Фибоначчи. Введите целое число и нажмите на кнопку Go для вычисления чисел
Фибоначчи. Начните с небольших чисел, пока не оцените, насколько быстро ваш
компьютер может выполнять эти вычисления.
Рекурсивное построение кривых Гильберта
Кривые Гильберта (Hilbert curves) — это самоподобные (self-similar) кривые, которые обычно определяются при помощи рекурсии. На рис. 5.2. показаны кривые Гильберта с 1, 2 или 3 порядка.
@Таблица 5.4. Время выполнения программы Fibonacci
=====88
@Рис. 5.2. Кривые Гильберта
Кривая Гильберта, как и любая другая самоподобная кривая, создается
разбиением большой кривой на меньшие части. Затем вы можете использовать
эту же кривую, после изменения размера и поворота, для построения этих
частей. Эти части можно разбить на более мелкие части, и так далее, пока
процесс не достигнет нужной глубины рекурсии. Порядок кривой определяется
как максимальная глубина рекурсии, которой достигает процедура.
Процедура Hilbert управляет глубиной рекурсии, используя соответствующий
параметр. При каждом рекурсивном вызове, процедура уменьшает параметр
глубины рекурсии на единицу. Если процедура вызывается с глубиной рекурсии,
равной 1, она рисует простую кривую 1 порядка, показанную на рис. 5.2 слева
и завершает работу. Это условие остановки рекурсии.
Например, кривая Гильберта 2 порядка состоит из четырех кривых Гильберта 1
порядка. Аналогично, кривая Гильберта 3 порядка состоит из четырех кривых 2
порядка, каждая из которых состоит из четырех кривых 1 порядка. На рис. 5.3
показаны кривые Гильберта 2 и 3 порядка. Меньшие кривые, из которых
построены кривые большего размера, выделены полужирными линиями.
Следующий код строит кривую Гильберта 1 порядка:
Line -Step (Length, 0)
Line -Step (0, Length)
Line -Step (-Length, 0)
Предполагается, что рисование начинается с верхнего левого угла области и
что Length — это заданная длина каждого отрезка линий.
Можно набросать черновик метода, рисующего кривые Гильберта более высоких
порядков:
Private Sub Hilbert(Depth As Integer)
If Depth = 1 Then
Нарисовать кривую Гильберта 1 порядка
Else
Нарисовать и соединить 4 кривые порядка (Depth - 1)
End If
End Sub
====89
@Рис. 5.3. Кривые Гильберта, образованные меньшими кривыми
Этот метод требует небольшого усложнения для определения направления
рисования кривых. Это требуется для того, чтобы выбрать тип используемых
кривых Гильберта.
Эту информацию можно передать процедуре при помощи параметров Dx и Dy для
определения направления вывода первой линии в кривой. Для кривой 1 порядка,
процедура рисует первую линию при помощи функции Line-Step(Dx, Dy). Если
кривая имеет более высокий порядок, процедура соединяет первые две
подкривых, используя функцию Line-Step(Dx, Dy). В любом случае, процедура
может использовать параметры Dx и Dy для выбора направления, в котором она
должна рисовать линии, образующие кривую.
Код на языке Visual Basic для рисования кривых Гильберта короткий, но
сложный. Вам может потребоваться несколько раз пройти его в отладчике для
кривых 1 и 2 порядка, чтобы увидеть, как изменяются параметры Dx и Dy, при
построении различных частей кривой.
Private Sub Hilbert(depth As Integer, Dx As Single, Dy As Single)
If depth > 1 Then Hilbert depth - 1, Dy, Dx
HilbertPicture.Line -Step(Dx, Dy)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
HilbertPicture.Line -Step(Dy, Dx)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
HilbertPicture.Line -Step(-Dx, -Dy)
If depth > 1 Then Hilbert depth - 1, -Dy, -Dx
End Sub
Анализ времени выполнения программы
Чтобы проанализировать время выполнения этой процедуры, вы можете определить число вызовов процедуры Hilbert. При каждой рекурсии она вызывает себя четыре раза. Если T(N) — это число вызовов процедуры, когда она вызывается с глубиной рекурсии N, то:
T(1) = 1
T(N) = 1 + 4 * T(N - 1) для N > 1.
Если раскрыть определение T(N), получим:
T(N) = 1 + 4 * T(N - 1)
= 1 + 4 *(1 + 4 * T(N - 2))
= 1 + 4 + 16 * T(N - 2)
= 1 + 4 + 16 * (1 + 4 * T(N - 3))
= 1 + 4 + 16 + 64 * T(N - 3)
= ...
= 40 + 41 + 42 + 43 + ... + 4K * T(N - K)
Раскрыв это уравнение до тех пор, пока не будет выполнено условие остановки рекурсии T(1)=1, получим:
T(N) = 40 + 41 + 42 + 43 + ... + 4N-1
Это уравнение можно упростить, воспользовавшись соотношением:
X0 + X1 + X2 + X3 + ... + XM = (XM+1 - 1) / (X - 1)
После преобразования, уравнение приводится к виду:
T(N) = (4(N-1)+1 - 1) / (4 - 1)
= (4N - 1) / 3
=====90
С точностью до постоянных, эта процедура выполняется за время порядка
O(4N). В табл. 5.5 приведены несколько первых значений функции времени
выполнения. Если вы внимательно посмотрите на эти числа, то увидите, что
они соответствуют рекурсивному определению.
Этот алгоритм является типичным примером рекурсивного алгоритма, который
выполняется за время порядка O(CN), где C — некоторая постоянная. При
каждом вызове подпрограммы Hilbert, она увеличивает размерность задачи в 4
раза. В общем случае, если при каждом выполнении некоторого числа шагов
алгоритма размер задачи увеличивается не менее, чем в C раз, то время
выполнения алгоритма будет порядка O(CN).
Это поведение противоположно поведению алгоритма поиска наибольшего общего
делителя. Процедура GCD уменьшает размерность задачи в 2 раза при каждом
втором своем вызове, и поэтому время ее выполнения порядка O(log(N)).
Процедура построения кривых Гильберта увеличивает размер задачи в 4 раза
при каждом своем вызове, поэтому время ее выполнения порядка O(4N).
Функция (4N-1)/3 — это экспоненциальная функция, которая растет очень
быстро. Фактически, она растет настолько быстро, что вы можете
предположить, что это не слишком эффективный алгоритм. В действительности
работа этого алгоритма занимает много времени, но есть две причины, по
которым это не так уж и плохо.
Во-первых, ни один алгоритм для построения кривых Гильберта не может быть
намного быстрее. Кривые Гильберта содержат множество отрезков линий, и
любой рисующий их алгоритм будет требовать достаточно много времени. При
каждом вызове процедуры Hilbert, она рисует три линии. Пусть L(N) —
суммарное число линий, из которых состоит кривая Гильберта порядка N. Тогда
L(N) = 3 * T(N) = 4N - 1, поэтому L(N) также порядка O(4N). Любой алгоритм,
рисующий кривые Гильберта, должен вывести O(4N) линий, выполнив при этом
O(4N) шагов. Существуют другие алгоритмы построения кривых Гильберта, но
они занимают почти столько же времени, сколько и этот алгоритм.
@Таблица 5.5. Число рекурсивных вызовов подпрограммы Hilbert
=====91
Второй факт, который показывает, что этот алгоритм не так уж плох,
заключается в том, что кривые Гильберта 9 порядка содержат так много линий,
что экран большинства компьютерных мониторов при этом оказывается полностью
закрашенным. Это неудивительно, так как эта кривая содержит 262.143
отрезков линий. Это означает, что вам вероятно никогда не понадобится
выводить на экран кривые Гильберта 9 или более высоких порядков. На каком-
то порядке вы столкнетесь с ограничениями языка Visual Basic и вашего
компьютера, но, скорее всего, вы еще раньше будете ограничены максимальным
разрешением экрана.
Программа Hilbert, показанная на рис. 5.4, использует этот рекурсивный
алгоритм для рисования кривых Гильберта. При выполнении программы не
задавайте слишком большую глубину рекурсии (больше 6) до тех пор, пока вы
не определите, насколько быстро выполняется эта программа на вашем
компьютере.
Рекурсивное построение кривых Серпинского
Как и кривые Гильберта, кривые Серпинского (Sierpinski curves) — это
самоподобные кривые, которые обычно определяются рекурсивно. На рис. 5.5
показаны кривые Серпинского 1, 2 и 3 порядка.
Алгоритм построения кривых Гильберта использует всего одну подпрограмму для
рисования кривых. Кривые Серпинского проще рисовать, используя четыре
отдельных процедуры, которые работают совместно. Эти процедуры называются
SierpA, SierpB, SierpC и SierpD. Это процедуры с косвенной рекурсией —
каждая процедура вызывает другие, которые затем вызывают первоначальную
процедуру. Они рисуют верхнюю, левую, нижнюю и правую части кривой
Серпинского, соответственно.
На рис. 5.6 показано, как эти процедуры работают совместно, образуя кривую
Серпинского 1 порядка. Подкривые изображены стрелками, чтобы показать
направление, в котором они рисуются. Отрезки, соединяющие четыре подкривые,
нарисованы пунктирными линиями.
@Рис. 5.4. Программа Hilbert
=====92
@Рис. 5.5. Кривые Серпинского
Каждая из четырех основных кривых состоит из диагонального отрезка, затем
вертикального или горизонтального отрезка, и еще одного диагонального
отрезка. Если глубина рекурсии больше единицы, каждая из этих кривых
разбивается на меньшие части. Это осуществляется разбиением каждого из двух
диагональных отрезков на две подкривые.
Например, для разбиения кривой типа A, первый диагональный отрезок
разбивается на кривую типа A, за которой следует кривая типа B. Затем
рисуется без изменений горизонтальный отрезок из исходной кривой типа A.
Наконец, второй диагональный отрезок разбивается на кривую типа D, за
которой следует кривая типа A. На рис. 5.7 показано, как кривая типа A
второго порядка образуется из нескольких кривых 1 порядка. Подкривые
изображены жирными линиями.
На рис. 5.8 показано, как полная кривая Серпинского 2 порядка образуется из
4 подкривых 1 порядка. Каждая из подкривых обведена контурной линией.
Можно использовать стрелки ( и ( для обозначения типа линий, соединяющих
подкривые (тонкие линии на рис. 5.8), тогда можно будет изобразить
рекурсивные отношения между четырьмя типами кривых так, как это показано на
рис. 5.9.
@Рис. 5.6. Части кривой Серпинского
=====93
@Рис. 5.7. Разбиение кривой типа A
Все процедуры для построения подкривых Серпинского очень похожи, поэтому мы
приводим здесь только одну из них. Соотношения на рис. 5.9 показывают,
какие операции нужно выполнить для рисования кривых различных типов.
Соотношения для кривой типа A реализованы в следующем коде. Вы можете
использовать остальные соотношения, чтобы определить, какие изменения нужно
внести в код для рисования кривых других типов.
Private Sub SierpA(Depth As Integer, Dist As Single)
If Depth = 1 Then
Line -Step(-Dist, Dist)
Line -Step(-Dist, 0)
Line -Step(-Dist, -Dist)
Else
SierpA Depth - 1, Dist
Line -Step(-Dist, Dist)
SierpB Depth - 1, Dist
Line -Step(-Dist, 0)
SierpD Depth - 1, Dist
Line -Step(-Dist, -Dist)
SierpA Depth - 1, Dist
End If
End Sub
@Рис. 5.8. Кривые Серпинского, образованные из меньших кривых Серпинского
=====94
@Рис. 5.9. Рекурсивные соотношения между кривыми Серпинского
Кроме процедур, которые рисуют каждую из основных кривых, потребуется еще процедура, которая по очереди вызывает их все для создания законченной кривой Серпинского.
Sub Sierpinski (Depth As Integer, Dist As Single)
SierpB Depth, Dist
Line -Step(Dist, Dist)
SierpC Depth, Dist
Line -Step(Dist, -Dist)
SierpD Depth, Dist
Line -Step(-Dist, -Dist)
SierpA Depth, Dist
Line -Step(-Dist, Dist)
End Sub
Анализ времени выполнения программы
Чтобы проанализировать время выполнения этого алгоритма, необходимо
определить число вызовов для каждой из четырех процедур рисования кривых.
Пусть T(N) — число вызовов любой из четырех основных подпрограмм основной
процедуры Sierpinski при построении кривой порядка N.
Если порядок кривой равен 1, кривая каждого типа рисуется только один раз.
Прибавив сюда основную процедуру, получим T(1) = 5.
При каждом рекурсивном вызове, процедура вызывает саму себя или другие
процедуры четыре раза. Так как эти процедуры практически одинаковые, то
T(N) будет одинаковым, независимо от того, какая процедура вызывается
первой. Это обусловлено тем, что кривые Серпинского симметричны и содержат
одно и то же число кривых разных типов. Рекурсивные уравнения для T(N)
выглядят так:
T(1) = 5
T(N) = 1 + 4 * T(N-1) для N > 1.
Эти уравнения почти совпадают с уравнениями, которые использовались для
оценки времени выполнения алгоритма, рисующего кривые Гильберта.
Единственное отличие состоит в том, что для кривых Гильберта T(1) = 1.
Сравнение значений этих уравнений показывает, что
TSierpinski(N) = THilbert(N+1). В конце предыдущего раздела было показано,
что THilbert(N) = (4N - 1) / 3, поэтому TSierpinski(N) = (4N+1 - 1) / 3,
что также составляет O(4N).
=====95
Так же, как и алгоритм построения кривых Гильберта, этот алгоритм
выполняется за время порядка O(4N), но это не так уж и плохо. Кривая
Серпинского состоит из O(4N) линий, поэтому ни один алгоритм не может
нарисовать кривую Серпинского быстрее, чем за время порядка O(4N).
Кривые Серпинского также полностью заполняют экран большинства компьютеров
при порядке кривой, большем или равном 9. При каком-то порядке, большем 9,
вы столкнетесь с ограничениями языка Visual Basic и возможностей вашего
компьютера, но, скорее всего, вы еще раньше будете ограничены предельным
разрешением экрана.
Программа Sierp, показанная на рис. 5.10, использует этот рекурсивный
алгоритм для рисования кривых Серпинского. При выполнении программы,
задавайте вначале небольшую глубину рекурсии (меньше 6), до тех пор, пока
вы не определите, насколько быстро выполняется эта программа на вашем
компьютере.
Опасности рекурсии
Рекурсия может служить мощным методом разбиения больших задач на части, но она таит в себе несколько опасностей. В этом разделе мы пытаемся охватить некоторые из этих опасностей и объяснить, когда стоит и не стоит использовать рекурсию. В последующих разделах приводятся методы устранения от рекурсии, когда это необходимо.
Бесконечная рекурсия
Наиболее очевидная опасность рекурсии заключается в бесконечной рекурсии.
Если неправильно построить алгоритм, то функция может пропустить условие
остановки рекурсии и выполняться бесконечно. Проще всего совершить эту
ошибку, если просто забыть о проверке условия остановки, как это сделано в
следующей ошибочной версии функции факториала. Поскольку функция не
проверяет, достигнуто ли условие остановки рекурсии, она будет бесконечно
вызывать сама себя.
@Рис. 5.10 Программа Sierp
=====96
Private Function BadFactorial(num As Integer) As Integer
BadFactorial = num * BadFactorial (num - 1)
End Function
Функция также может вызывать себя бесконечно, если условие остановки не прекращает все возможные пути рекурсии. В следующей ошибочной версии функции факториала, функция будет бесконечно вызывать себя, если входное значение — не целое число, или если оно меньше 0. Эти значения не являются допустимыми входными значениями для функции факториала, поэтому в программе, которая использует эту функцию, может потребоваться проверка входных значений. Тем не менее, будет лучше, если функция выполнит эту проверку сама.
Private Function BadFactorial2(num As Double) As Double
If num = 0 Then
BadFactorial2 = 1
Else
BadFactorial2 = num * BadFactorial2(num-1)
End If
End Function
Следующая версия функции Fibonacci является более сложным примером. В ней
условие остановки рекурсии прекращает выполнение только нескольких путей
рекурсии, и возникают те же проблемы, что и при выполнении функции
BadFactorial2, если входные значения отрицательные или не целые.
Private Function BadFib(num As Double) As Double
If num = 0 Then
BadFib = 0
Else
BadFib = BadPib(num - 1) + BadFib (num - 2)
End If
End Function
И последняя проблема, связанная с бесконечной рекурсией, заключается в том,
что «бесконечная» на самом деле означает «до тех пор, пока не будет
исчерпано стековое пространство». Даже корректно написанные рекурсивные
процедуры будут иногда приводить к переполнению стека и аварийному
завершению работы. Следующая функция, которая вычисляет сумму N + (N - 1) +
… + 2 +1, приводит к исчерпанию стекового пространства при больших
значениях N. Наибольшее возможное значение N, при котором программа еще
будет работать, зависит от конфигурации вашего компьютера.
Private Function BigAdd(N As Double) As Double
If N 1 Then Hilbert depth - 1, Dy, Dx
2 HilbertPicture.Line -Step(Dx, Dy)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
3 HilbertPicture.Line -Step(Dy, Dx)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
4 HilbertPicture.Line -Step(-Dx, -Dy)
If depth > 1 Then Hilbert depth - 1, -Dy, -Dx
End Sub
Каждый раз, когда нерекурсивная процедура начинает «рекурсию», она должна сохранять значения локальных переменных Depth, Dx, и Dy, а также следующее значение переменной pc. После возврата из «рекурсии», она восстанавливает эти значения. Для упрощения работы, можно написать пару вспомогательных процедур для заталкивания и выталкивания этих значений из нескольких стеков.
====109
Const STACK_SIZE =20
Dim DepthStack(0 To STACK_SIZE)
Dim DxStack(0 To STACK_SIZE)
Dim DyStack(0 To STACK_SIZE)
Dim PCStack(0 To STACK_SIZE)
Dim TopOfStack As Integer
Private Sub SaveValues (Depth As Integer, Dx As Single, _
Dy As Single, pc As Integer)
TopOfStack = TopOfStack + 1
DepthStack(TopOfStack) = Depth
DxStack(TopOfStack) = Dx
DyStack(TopOfStack) = Dy
PCStack(TopOfStack) = pc
End Sub
Private Sub RestoreValues (Depth As Integer, Dx As Single, _
Dy As Single, pc As Integer)
Depth = DepthStack(TopOfStack)
Dx = DxStack(TopOfStack)
Dy = DyStack(TopOfStack) pc = PCStack(TopOfStack)
TopOfStack = TopOfStack - 1
End Sub
Следующий код демонстрирует нерекурсивную версию подпрограммы Hilbert.
Private Sub Hilbert(Depth As Integer, Dx As Single, Dy As Single)
Dim pc As Integer
Dim tmp As Single
pc = 1
Do
Select Case pc
Case 1
If Depth > 1 Then " Рекурсия.
" Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 2
" Подготовиться к рекурсии.
Depth = Depth - 1 tmp = Dx
Dx = Dy
Dy = tmp pc = 1 " Перейти в начало рекурсивного вызова.
Else " Условие остановки.
" Достаточно глубокий уровень рекурсии.
" Продолжить со 2 блоком кода. pc = 2
End If
Case 2
HilbertPicture.Line -Step(Dx, Dy)
If Depth > 1 Then " Рекурсия.
" Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 3
" Подготовиться к рекурсии.
Depth = Depth - 1
" Dx и Dy остаются без изменений. pc = 1 Перейти в начало рекурсивного вызова.
Else " Условие остановки.
" Достаточно глубокий уровень рекурсии.
" Продолжить с 3 блоком кода. pc = 3
End If
Case 3
HilbertPicture.Line -Step(Dy, Dx)
If Depth > 1 Then " Рекурсия.
" Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 4
" Подготовиться к рекурсии.
Depth = Depth - 1
" Dx и Dy остаются без изменений. pc = 1 Перейти в начало рекурсивного вызова.
Else " Условие остановки.
" Достаточно глубокий уровень рекурсии.
" Продолжить с 4 блоком кода. pc = 4
End If
Case 4
HilbertPicture.Line -Step(-Dx, -Dy)
If Depth > 1 Then " Рекурсия.
" Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 0
" Подготовиться к рекурсии.
Depth = Depth - 1 tmp = Dx
Dx = -Dy
Dy = -tmp pc = 1 Перейти в начало рекурсивного вызова.
Else " Условие остановки.
" Достаточно глубокий уровень рекурсии.
" Конец этого рекурсивного вызова. pc = 0
End If
Case 0 " Возврат из рекурсии.
If TopOfStack > 0 Then
RestoreValues Depth, Dx, Dy, pc
Else
" Стек пуст. Выход.
Exit Do
End If
End Select
Loop
End Sub
======111
Время выполнения этого алгоритма может быть нелегко оценить
непосредственно. Поскольку методы преобразования рекурсивных процедур в
нерекурсивные не изменяют время выполнения алгоритма, эта процедура так же,
как и предыдущая версия, имеет время выполнения порядка O(N4).
Программа Hilbert2 демонстрирует нерекурсивный алгоритм построения кривых
Гильберта. Задавайте вначале построение несложных кривых (меньше 6
порядка), пока не узнаете, насколько быстро будет выполняться эта программа
на вашем компьютере.
Нерекурсивное построение кривых Серпинского
Приведенный ранее алгоритм построения кривых Серпинского включает в себя
косвенную и множественную рекурсию. Так как алгоритм состоит из четырех
подпрограмм, которые вызывают друг друга, то нельзя просто пронумеровать
важные строки, как это можно было сделать в случае алгоритма построения
кривых Гильберта. С этой проблемой можно справиться, слегка изменив
алгоритм.
Рекурсивная версия этого алгоритма состоит из четырех подпрограмм SierpA,
SierpB, SierpC и SierpD. Подпрограмма SierpA выглядит так:
Private Sub SierpA(Depth As Integer, Dist As Single)
If Depth = 1 Then
Line -Step(-Dist, Dist)
Line -Step(-Dist, 0)
Line -Step(-Dist, -Dist)
Else
SierpA Depth - 1, Dist
Line -Step(-Dist, Dist)
SierpB Depth - 1, Dist
Line -Step(-Dist, 0)
SierpD Depth - 1, Dist
Line -Step(-Dist, -Dist)
SierpA Depth - 1, Dist
End If
End Sub
Три другие процедуры аналогичны. Несложно объединить эти четыре процедуры в одну подпрограмму.
Private Sub SierpAll(Depth As Integer, Dist As Single, Func As Integer)
Select Case Punc
Case 1 " SierpA
Case 2 " SierpB
Case 3 " SierpC
Case 4 " SierpD
End Select
End Sub
======112
Параметр Func сообщает подпрограмме, какой блок кода выполнять. Вызовы
подпрограмм заменяются на вызовы процедуры SierpAll с соответствующим
значением Func. Например, вызов подпрограммы SierpA заменяется на вызов
процедуры SierpAll с параметром Func, равным 1. Таким же образом заменяются
вызовы подпрограмм SierpB, SierpC и SierpD.
Полученная процедура рекурсивно вызывает себя в 16 различных точках. Эта
процедура намного сложнее, чем процедура Hilbert, но в других отношениях
она имеет такую же структуру и поэтому к ней можно применить те же методы
устранения рекурсии.
Можно использовать первую цифру меток pc, для определения номера блока
кода, который должен выполняться. Перенумеруем строки в коде SierpA числами
11, 12, 13 и т.д. Перенумеруем строки в коде SierpB числами 21, 22, 23 и
т.д.
Теперь можно пронумеровать ключевые строки кода внутри каждого из блоков.
Для кода подпрограммы SierpA ключевыми строками будут:
" Код SierpA.
11 If Depth = 1 Then
Line -Step(-Dist, Dist)
Line -Step(-Dist, 0)
Line -Step(-Dist, -Dist)
Else
SierpA Depth - 1, Dist
12 Line -Step(-Dist, Dist)
SierpB Depth - 1, Dist
13 Line -Step(-Dist, 0)
SierpD Depth - 1, Dist
14 Line -Step(-Dist, -Dist)
SierpA Depth - 1, Dist
End If
Типичная «рекурсия» из кода подпрограммы SierpA в код подпрограммы SierpB выглядит так:
SaveValues Depth, 13 " Продолжить с шага 13 после завершения.
Depth = Depth - 1
pc = 21 " Передать управление на начало кода
SierpB.
======113
Метка 0 зарезервирована для обозначения выхода из «рекурсии». Следующий код
демонстрирует нерекурсивную версию процедуры SierpAll. Код для подпрограмм
SierpB, SierpC, и SierpD аналогичен коду для SierpA, поэтому он опущен.
Private Sub SierpAll(Depth As Integer, pc As Integer)
Do
Select Case pc
" **********
" * SierpA *
" **********
Case 11
If Depth 0 Then ReDim Preserve ToNode(0 To NumLinks - 1)
End Sub
Sub RemoveNode(node As Integer)
Dim i As Integer
" Сдвинуть элементы массива FirstLink, чтобы заполнить
" пустую ячейку.
For i = node + 1 To NumNodes
FirstLink(i - 1) = FirstLink(i)
Next i
" Сдвинуть элементы массива NodeCaption.
For i = node + 1 To NumNodes - 1
NodeCaption(i - 1) = NodeCaption(i)
Next i
" Обновить записи массива ToNode.
For i = 0 To NumLinks - 1
If ToNode(i) >= node Then ToNode(i) = ToNode(i) - 1
Next i
" Удалить лишнюю запись массива FirstLink.
NumNodes = NumNodes - 1
ReDim Preserve FirstLink(0 To NumNodes)
ReDim Preserve NodeCaption(0 To NumNodes - 1)
Unload FStarForm.NodeLabel(NumNodes)
End Sub
Это намного сложнее, чем соответствующий код в программе NAry:
Public Function DeleteDescendant(target As NAryNode) As Boolean
Dim i As Integer
Dim child As NAryNode
" Является ли узел дочерним узлом.
For i = 1 To Children.Count
If Children.Item(i) Is target Then
Children.Remove i
DeleteDescendant = True
Exit Function
End If
Next i
" Если это не дочерний узел, рекурсивно
" проверить остальных потомков.
For Each child In Children
If child.DeleteDescendant(target) Then
DeleteDescendant = True
Exit Function
End If
Next child
End Function
=======125-126
Полные деревья
Полное дерево (complete tree) содержит максимально возможное число узлов на
каждом уровне, кроме нижнего. Все узлы на нижнем уровне сдвигаются влево.
Например, каждый уровень троичного дерева содержит в точности три дочерних
узла, за исключением листьев, и возможно, одного узла на один уровень выше
листьев. На рис. 6.9 показаны полные двоичное и троичное деревья.
Полные деревья обладают рядом важных свойств. Во-первых, это кратчайшие
деревья, которые могут содержать заданное число узлов. Например, двоичное
дерево на рис. 6.9 — одно из самых коротких двоичных деревьев с шестью
узлами. Существуют другие двоичные деревья с шестью узлами, но ни одно из
них не имеет высоту меньше 3.
Во-вторых, если полное дерево порядка D состоит из N узлов, оно будет иметь
высоту порядка O(logD(N)) и O(N) листьев. Эти факты имеют большое значение,
поскольку многие алгоритмы обходят деревья сверху вниз или в
противоположном направлении. Время выполнения алгоритма, выполняющего одно
из этих действий, будет порядка O(N).
Чрезвычайно полезное свойство полных деревьев заключается в том, что они
могут быть очень компактно записаны в массивах. Если пронумеровать узлы в
«естественном» порядке, сверху вниз и слева направо, то можно поместить
элементы дерева в массив в этом порядке. На рис. 6.10 показано, как можно
записать полное дерево в массиве.
Корень дерева находится в нулевой позиции. Дочерние узлы узла I находятся
на позициях 2 * I + 1 и 2 * I + 2. Например, на рис. 6.10, потомки узла в
позиции 1 (узла B), находятся в позициях 3 и 4 (узлы D и E).
Легко обобщить это представление на полные деревья более высокого порядка
D. Корень дерева также будет находиться в позиции 0. Потомки узла I
занимают позиции от D * I + 1 до D * I +(I - 1). Например, в троичном
дереве, потомки узла в позиции 2, будут занимать позиции 7, 8 и 9. На рис.
6.11 показано полное троичное дерево и его представление в виде массива.
@Рис. 6.9. Полные деревья
=========127
@Рис. 6.10. Запись полного двоичного дерева в массиве
При использовании этого метода записи дерева в массиве легко и просто получить доступ к потомкам узла. При этом не требуется дополнительной памяти для коллекций дочерних узлов или меток в случае представления нумерацией связей. Чтение и запись дерева в файл сводится просто к сохранению или чтению массива. Поэтому это несомненно лучшее представление дерева для программ, которые сохраняют данные в полных деревьях.
Обход дерева
Последовательное обращение ко всем узлам называется обходом (traversing)
дерева. Существует несколько последовательностей обхода узлов двоичного
дерева. Три простейших из них — прямой (preorder), симметричный (inorder),
и обратный (postorder)обход, описываются простыми рекурсивными алгоритмами.
Для каждого заданного узла алгоритмы выполняют следующие действия:
Прямой обход:
1. Обращение к узлу.
2. Рекурсивный прямой обход левого поддерева.
3. Рекурсивный прямой обход правого поддерева.
Симметричный обход:
1. Рекурсивный симметричный обход левого поддерева.
2. Обращение к узлу.
3. Рекурсивный симметричный обход левого поддерева.
Обратный обход:
1. Рекурсивный обратный обход левого поддерева.
2. Рекурсивный обратный обход правого поддерева.
3. Обращение к узлу.
@Рис. 6.11. Запись полного троичного дерева в массиве
=======128
Все три порядка обхода являются примерами обхода в глубину (depth-first
traversal). Обход начинается с прохода вглубь дерева до тех пор, пока
алгоритм не достигнет листьев. При возврате из рекурсивного вызова
подпрограммы, алгоритм перемещается по дереву в обратном направлении,
просматривая пути, которые он пропустил при движении вниз.
Обход в глубину удобно использовать в алгоритмах, которые должны вначале
обойти листья. Например, метод ветвей и границ, описанный в 8 главе, как
можно быстрее пытается достичь листьев. Он использует результаты,
полученные на уровне листьев для уменьшения времени поиска в оставшейся
части дерева.
Четвертый метод перебора узлов дерева — это обход в ширину (breadth-first
traversal). Этот метод обращается ко всем узлам на заданном уровне дерева,
перед тем, как перейти к более глубоким уровням. Алгоритмы, которые
проводят полный поиск по дереву, часто используют обход в ширину. Алгоритм
поиска кратчайшего маршрута с установкой меток, описанный в 12 главе,
представляет собой обход в ширину, дерева кратчайшего пути в сети.
На рис. 6.12 показано небольшое дерево и порядок, в котором перебираются
узлы во время прямого, симметричного и обратного обхода, а также обхода в
ширину.
@Рис. 6.12. Обходы дерева
======129
Для деревьев больше, чем 2 порядка, все еще имеет смысл определять прямой,
обратный обход, и обход в ширину. Симметричный обход определяется
неоднозначно, так как обращение к каждому узлу может происходить после
обращения к одному, двум, или трем его потомкам. Например, в троичном
дереве, обращение к узлу может происходить после обращения к его первому
потомку или после обращения ко второму потомку.
Детали реализации обхода зависят от того, как записано дерево. Для обхода
дерева на основе коллекций дочерних узлов, программа должна использовать
несколько другой алгоритм, чем для обхода дерева, записанного при помощи
нумерации связей.
Особенно просто обходить полные деревья, записанные в массиве. Алгоритм
обхода в ширину, который требует дополнительных усилий в других
представлениях деревьев, для представлений на основе массива тривиален, так
как узлы записаны в таком же порядке.
Следующий код демонстрирует алгоритмы обхода полного двоичного дерева:
Dim NodeLabel() As String " Запись меток узлов.
Dim NumNodes As Integer
" Инициализация дерева.
:
Private Sub Preorder(node As Integer)
Print NodeLabel (node) " Узел.
" Первый потомок.
If node * 2 + 1 FOX.
Таким же образом можно закодировать строки из 6 заглавных букв в виде числа
в формате long и строки из 10 букв — как число в формате double. Две
следующие процедуры конвертируют строки в числа в формате double и обратно:
Const STRING_BASE = 27
Const ASC_A = 65 ‘ ASCII код для символа "A".
‘ Преобразование строки с число в формате double.
‘
‘ full_len — полная длина, которую должна иметь строка.
‘ Нужна, если строка слишком короткая (например "AX" —
‘ это строка из трех символов).
Function StringToDbl (txt As String, full_len As Integer) As Double
Dim strlen As Integer
Dim i As Integer
Dim value As Double
Dim ch As String * 1
strlen = Len(txt)
If strlen > full_len Then strlen = full_len
value = 0#
For i = 1 To strlen ch = Mid$(txt, i, 1) value = value * STRING_BASE + Asc(ch) - ASC_A + 1
Next i
For i = strlen + 1 To full_len value = value * STRING_BASE
Next i
End Function
‘ Обратное декодирование строки из формата double.
Function DblToString (ByVal value As Double) As String
Dim strlen As Integer
Dim i As Integer
Dim txt As String
Dim Power As Integer
Dim ch As Integer
Dim new_value As Double
txt = ""
Do While value > 0 new_value = Int(value / STRING_BASE) ch = value - new_value * STRING_BASE
If ch 0 Then txt = Chr$(ch + ASC_A - 1) + txt value = new_value
Loop
DblToString = txt
End Function
===========228
В табл. 9.1 приведено время выполнения программой Encode сортировки 2000 строк различной длины на компьютере с процессором Pentium и тактовой частотой 90 МГц. Заметим, что результаты похожи для каждого типа кодирования. Сортировка 2000 чисел в формате double занимает примерно одинаковое время независимо от того, представляют ли они строки из 3 или 10 символов.
========229
@Таблица 9.1. Время сортировки 2000 строк с использованием различных кодировок в секундах
Можно также кодировать строки, состоящие не только из заглавных букв.
Строку из заглавных букв и цифр можно закодировать по основанию 37 вместо
27. Код буквы A будет равен 1, B — 2, … , Z — 26, код 0 будет 27, … , и 9 —
36. Строка AH7 будет кодироваться как 372 * 1 + 37 * 8 + 35 = 1700.
Конечно, при использовании большего основания, длина строки, которую можно
закодировать числом типа integer, long или double будет соответственно
короче. При основании равном 37, можно закодировать строку из 2 символов в
числе формата integer, из 5 символов в числе формата long, и 10 символов в
числе формата double.
Примеры программ
Чтобы облегчить сравнение различных алгоритмов сортировки, программа Sort
демонстрирует большинство алгоритмов, описанных в этой главе. Сортировка
позволяет задать число сортируемых элементов, их максимальное значение, и
порядок расположения элементов - прямой, обратный или расположение в
случайном порядке. Программа создает список случайно расположенных чисел в
формате long и сортирует его, используя выбранный алгоритм. Вначале
сортируйте короткие списки, пока не определите, насколько быстро ваш
компьютер может выполнять операции сортировки. Это особенно важно для
медленных алгоритмов сортировки вставкой, сортировки вставкой с
использованием связного списка, сортировки выбором, и пузырьковой
сортировки.
Некоторые алгоритмы перемещают большие блоки памяти. Например, алгоритм
сортировки вставкой перемещает элементы списка для того, чтобы можно было
вставить новый элемент в середину списка. Для перемещения элементов
программе, написанной на Visual Basic, приходится использовать цикл For.
Следующий код показывает, как сортировка вставкой перемещает элементы с
List(j) до List(max_sorted) для того, чтобы освободить место под новый
элемент в позиции List(j):
For k = max_sorted To j Step -1
List(k + 1) = List(k)
Next k
List(j) = next_num
==========230
Интерфейс прикладного программирования системы Windows включает две
функции, которые позволяют намного быстрее выполнять перемещение блоков
памяти. Программы, скомпилированные 16-битной версией компилятора Visual
Basic 4, могут использовать функцию hmemcopy. Программы, скомпилированные
32-битными компиляторами Visual Basic 4 и 5, могут использовать функцию
RtlMoveMemory. Обе функции принимают в качестве параметров конечный и
исходный адреса и число байт, которое должно быть скопировано. Следующий
код показывает, как объявлять эти функции в модуле .BAS:
#if Win16 Then
Declare Sub MemCopy Lib "Kernel" Alias _
"hmemcpy" (dest As Any, src As Any, _
ByVal numbytes As Long)
#Else
Declare Sub MemCopy Lib "Kernel32" Alias _
"RtlMoveMemory" (dest As Any, src As Any, _
ByVal numbytes As Long)
#EndIf
Следующий фрагмент кода показывает, как сортировка вставкой может использовать эти функции для копирования блоков памяти. Этот код выполняет те же действия, что и цикл For, приведенный выше, но делает это намного быстрее:
If max_sorted >= j Then _
MemCopy List(j + 1), List(j), _
Len(next_num) * (max_sorted - j + 1)
List(j) = next_num
Программа FastSort аналогична программе Sort, но она использует функцию
MemCopy для ускорения работы некоторых алгоритмов. В программе FastSort
алгоритмы, использующие функцию MemCopy, выделены синим цветом.
Сортировка выбором
Сортировка выбором (selectionsort) — простой алгоритм со сложность порядка
O(N2). Идея состоит в поиске наименьшего элемента в списке, который затем
меняется местами с элементом на вершине списка. Затем находится наименьший
элемент из оставшихся, и меняется местами со вторым элементом. Процесс
продолжается до тех пор, пока все элементы не займут свое конечное
положение.
Public Sub Selectionsort(List() As Long, min As Long, max As Long)
Dim i As Long
Dim j As Long
Dim best_value As Long
Dim best_j As Long
For i = min To max - 1
‘ Найти наименьший элемент из оставшихся. best_value = List(i) best_j = i
For j = i + 1 To max
If List(j) < best_value Then best_value = List(j) best_j = j
End If
Next j
‘ Поместить элемент на место.
List(best_j) = List(i)
List(i) = best_value
Next i
End Sub
========231
При поиске I-го наименьшего элемента, алгоритму приходится перебрать N-I
элементов, которые еще не заняли свое конечное положение. Время выполнения
алгоритма пропорционально N + (N - 1) + (N - 2) + … + 1, или порядка O(N2).
Сортировка выбором неплохо работает со списками, элементы в которых
расположены случайно или в прямом порядке, но несколько хуже, если список
изначально отсортирован в обратном порядке. Для поиска наименьшего элемента
в списке сортировка выбором выполняет следующий код:
If list(j) < best_value Then best_value = list(j) best_j = j
End If
Если первоначально список отсортирован в обратном порядке, условие list(j)
< best_value выполняется большую часть времени. Например, при первом
проходе оно будет истинно для всех элементов, поскольку каждый элемент
меньше предыдущего. Алгоритм будет многократно выполнять строки с
оператором If, что приведет к некоторому замедлению работы алгоритма.
Это не самый быстрый алгоритм из числа описанных в главе, но он чрезвычайно
прост. Это не только облегчает его разработку и отладку, но и делает
сортировку выбором достаточно быстрой для небольших задач. Многие другие
алгоритмы настолько сложны, что они сортируют очень маленькие списки
медленнее.
Рандомизация
В некоторых программах требуется выполнение операции, обратной сортировке.
Получив список элементов, программа должна расположить их в случайном
порядке. Рандомизацию (unsorting) списка несложно выполнить, используя
алгоритм, похожий на сортировку выбором.
Для каждого положения в списке, алгоритм случайным образом выбирает
элемент, который должен его занять из тех, которые еще не были помещены на
свое место. Затем этот элемент меняется местами с элементом, который,
находится на этой позиции.
Public Sub Unsort(List() As Long, min As Long, max As Long)
Dim i As Long
Dim Pos As Long
Dim tmp As Long
For i - min To max - 1 pos = Int((max - i + 1) * Rnd + i) tmp = List(pos)
List(pos) = List(i)
List(i) = tmp
Next i
End Sub
==============232
Т.к. алгоритм заполняет каждую позицию только один раз, его сложность
порядка O(N).
Несложно показать, что вероятность того, что элемент окажется на какой-либо
позиции, равна 1/N. Поскольку элемент может оказаться в любом положении с
равной вероятностью, этот алгоритм действительно приводит к случайному
размещению элементов.
Результат зависит от того, насколько хорошим является генератор случайных
чисел. Функция Rnd в Visual Basic дает приемлемый результат для большинства
случаев. Следует убедиться, что программа использует оператор Randomize для
инициализации функции Rnd, иначе при каждом запуске программы функция Rnd
будет выдавать одну и ту же последовательность «случайных» значений.
Заметим, что для алгоритма не важен первоначальный порядок расположения
элементов. Если вам необходимо неоднократно рандомизировать список
элементов, нет необходимости его предварительно сортировать.
Программа Unsort показывает использование этого алгоритма для рандомизации
отсортированного списка. Введите число элементов, которые вы хотите
рандомизировать, и нажмите кнопку Go (Начать). Программа показывает
исходный отсортированный список чисел и результат рандомизации.
Сортировка вставкой
Сортировка вставкой (insertionsort) — еще один алгоритм со сложностью порядка O(N2). Идея состоит в том, чтобы создать новый сортированный список, просматривая поочередно все элементы в исходном списке. При этом, выбирая очередной элемент, алгоритм просматривает растущий отсортированный список, находит требуемое положение элемента в нем, и помещает элемент на свое место в новый список.
Public Sub Insertionsort(List() As Long, min As Long, max As Long)
Dim i As Long
Dim j As Long
Dim k As Long
Dim max_sorted As Long
Dim next_num As Long
max_sorted = min -1
For i = min To max
‘ Это вставляемое число.
Next_num = List(i)
‘ Поиск его позиции в списке.
For j = min To max_sorted
If List(j) >= next_num Then Exit For
Next j
‘ Переместить большие элементы вниз, чтобы
‘ освободить место для нового числа.
For k = max_sorted To j Step -1
List(k + 1) = List(k)
Next k
‘ Поместить новый элемент.
List(j) = next_num
‘ Увеличить счетчик отсортированных элементов. max_sorted = max_sorted + 1
Next i
End Sub
=======233
Может оказаться, что для каждого из элементов в исходном списке, алгоритму
придется проверять все уже отсортированные элементы. Это происходит,
например, если в исходном списке элементы были уже отсортированы. В этом
случае, алгоритм помещает каждый новый элемент в конец растущего
отсортированного списка.
Полное число шагов, которые потребуется выполнить, составляет 1 + 2 + 3 + …
+ (N - 1), то есть O(N2). Это не слишком эффективно, если сравнить с
теоретическим пределом O(N * log(N)) для алгоритмов на основе операций
сравнения. Фактически, этот алгоритм не слишком быстр даже в сравнении с
другими алгоритмами порядка O(N2), такими как сортировка выбором.
Достаточно много времени алгоритм сортировки вставкой тратит на перемещение
элементов для того, чтобы вставить новый элемент в середину
отсортированного списка. Использование для этого функции API MemCopy
увеличивает скорость работы алгоритма почти вдвое.
Достаточно много времени тратится и на поиск правильного положения для
нового элемента. В 10 главе описано несколько алгоритмов поиска в
отсортированных списках. Применение алгоритма интерполяционного поиска
намного ускоряет выполнение алгоритма сортировки вставкой. Интерполяционный
поиск подробно описывается в 10 главе, поэтому мы не будем сейчас на нем
останавливаться.
Программа FastSort использует оба этих метода для улучшения
производительности сортировки вставкой. С использованием функции MemCopy и
интерполяционного поиска, эта версия алгоритма более чем в 15 раз быстрее,
чем исходная.
Вставка в связных списках
Можно использовать вариант сортировки вставкой для упорядочения элементов не в массиве, а в связном списке. Этот алгоритм ищет требуемое положение элемента в растущем связном списке, и затем помещает туда новый элемент, используя операции работы со связными списками.
=========234
Public Sub LinkInsertionSort(ListTop As ListCell)
Dim new_top As New ListCell
Dim old_top As ListCell
Dim cell As ListCell
Dim after_me As ListCell
Dim nxt As ListCell
Set old_top = ListTop.NextCell
Do While Not (old_top Is Nothing)
Set cell = old_top
Set old_top = old_top.NextCell
‘ Найти, куда необходимо поместить элемент.
Set after_me = new_top
Do
Set nxt = after_me.NextCell
If nxt Is Nothing Then Exit Do
If nxt.Value >= cell.Value Then Exit Do
Set after_me = nxt
Loop
‘ Вставить элемент после позиции after_me.
Set after_me.NextCll = cell
Set cell.NextCell = nx
Loop
Set ListTop.NextCell = new_top.NextCell
End Sub
Т.к. этот алгоритм перебирает все элементы, может потребоваться сравнение
каждого элемента со всеми элементами в отсортированном списке. В этом
наихудшем случае вычислительная сложность алгоритма порядка O(N2).
Наилучший случай для этого алгоритма достигается, когда исходный список
первоначально отсортирован в обратном порядке. При этом каждый последующий
элемент меньше, чем предыдущий, поэтому алгоритм помещает его в начало
отсортированного списка. При этом требуется выполнить только одну операцию
сравнения элементов, и в наилучшем случае время выполнения алгоритма будет
порядка O(N).
В усредненном случае, алгоритму придется провести поиск примерно по
половине отсортированного списка для того, чтобы найти местоположение
элемента. При этом алгоритм выполняется примерно за 1 + 1 + 2 + 2 + … +
N/2, или порядка O(N2) шагов.
Улучшенная процедура сортировки вставкой, использующая интерполяционный
поиск и функцию MemCopy, работает намного быстрее, чем версия со связным
списком, поэтому последнюю процедуру лучше использовать, если программа уже
хранит элементы в связном списке.
Преимущество использования связных списков для вставки в том, что при этом
перемещаются только указатели, а не сами записи данных. Передача указателей
может быть быстрее, чем копирование записей целиком, если элементы
представляют собой большие структуры данных.
=======235
Пузырьковая сортировка
Пузырьковая сортировка (bubblesort) — это алгоритм, предназначенный для
сортировки списков, которые уже находятся в почти упорядоченном состоянии.
Если в начале процедуры список полностью отсортирован, алгоритм выполняется
очень быстро за время порядка O(N). Если часть элементов находятся не на
своих местах, алгоритм выполняется медленнее. Если первоначально элементы
расположены в случайном порядке, алгоритм выполняется за время порядка
O(N2). Поэтому перед применением пузырьковой сортировки важно убедиться,
что элементы в основном расположены по порядку.
При пузырьковой сортировке список просматривается до тех пор, пока не
найдутся два соседних элемента, расположенных не по порядку. Тогда они
меняются местами, и процедура продолжается дальше. Алгоритм повторяет этот
процесс до тех пор, пока все элементы не займут свои места.
На рис. 9.2 показано, как алгоритм вначале обнаруживает, что элементы 6 и 3
расположены не по порядку, и поэтому меняет их местами. Во время следующего
прохода, меняются местами элементы 5 и 3, в следующем — 4 и 3. После еще
одного прохода алгоритм обнаруживает, что все элементы расположены по
порядку, и завершает работу.
Можно проследить за перемещениями элемента, который первоначально был
расположен ниже, чем после сортировки, например элемента 3 на рис. 9.2. Во
время каждого прохода элемент перемещается на одну позицию ближе к своему
конечному положению. Он движется к вершине списка подобно пузырьку газа,
который всплывает к поверхности в стакане воды. Этот эффект и дал название
алгоритму пузырьковой сортировки.
Можно внести в алгоритм несколько улучшений. Во-первых, если элемент
расположен в списке выше, чем должно быть, вы увидите картину, отличную от
той, которая приведена на рис. 9.2. На рис. 9.3 показано, что алгоритм
вначале обнаруживает, что элементы 6 и 3 расположены в неправильном
порядке, и меняет их местами. Затем алгоритм продолжает просматривать
массив и замечает, что теперь неправильно расположены элементы 6 и 4, и
также меняет их местами. Затем меняются местами элементы 6 и 5, и элемент 6
занимает свое место.
@Рис. 9.2. «Всплывание» элемента
========236
@Рис. 9.3. «Погружение» элемента
При просмотре массива сверху вниз, элементы, которые перемещаются вверх,
сдвигаются всего на одну позицию. Те же элементы, которые перемещаются
вниз, сдвигаются на несколько позиций за один проход. Этот факт можно
использовать для ускорения работы алгоритма пузырьковой сортировки. Если
чередовать просмотр массива сверху вниз и снизу вверх, то перемещение
элементов в прямом и обратном направлениях будет одинаково быстрым.
Во время проходов сверху вниз, наибольший элемент списка перемещается на
место, а во время проходов снизу вверх — наименьший. Если M элементов
списка расположены не на своих местах, алгоритму потребуется не более M
проходов для того, чтобы расположить элементы по порядку. Если в списке N
элементов, алгоритму потребуется N шагов для каждого прохода. Таким
образом, полное время выполнения для этого алгоритма будет порядка O(M *
N).
Если первоначально список организован случайным образом, большая часть
элементов будет находиться не на своих местах. В примере, приведенном на
рис. 9.3, элемент 6 трижды меняется местами с соседними элементами. Вместо
выполнения трех отдельных перестановок, можно сохранить значение 6 во
временной переменной до тех пор, пока не будет найдено конечное положение
элемента. Это может сэкономить большое число шагов алгоритма, если элементы
перемещаются на большие расстояния внутри массива.
Последнее улучшение — ограничение проходов массива. После просмотра
массива, последние переставленные элементы обозначают часть массива,
которая содержит неупорядоченные элементы. При проходе сверху вниз,
например, наибольший элемент перемещается в конечное положение. Поскольку
нет больших элементов, которые нужно было бы поместить за ним, то можно
начать очередной проход снизу вверх с этой точки и на ней же заканчивать
следующие проходы сверху вниз.
========237
Таким же образом, после прохода снизу вверх, можно сдвинуть позицию, с
которой начнется очередной проход сверху вниз, и будут заканчиваться
последующие проходы снизу вверх.
Реализация алгоритма пузырьковой сортировки на языке Visual Basic
использует переменные min и max для обозначения первого и последнего
элементов списка, которые находятся не на своих местах. По мере того, как
алгоритма повторяет проходы по списку, эти переменные обновляются, указывая
положение последней перестановки.
Public Sub Bubblesort(List() As Long, ByVal min As Long, ByVal max As Long)
Dim last_swap As Long
Dim i As Long
Dim j As Long
Dim tmp As Long
‘ Повторять до завершения.
Do While min < max
‘ «Всплывание». last_swap = min - 1
‘ То есть For i = min + 1 To max. i = min + 1
Do While i List(i) Then
‘ Найти, куда его поместить. tmp = List(i - 1) j = i
Do
List(j - 1) = List(j) j = j + 1
If j > max Then Exit Do
Loop While List(j) < tmp
List(j - 1) = tmp last_swap = j - 1 i = j + 1
Else i = i + 1
End If
Loop
‘ Обновить переменную max. max = last_swap - 1
‘ «Погружение». last_swap = max + 1
‘ То есть For i = max -1 To min Step -1 i = max - 1
Do While i >= min
‘ Найти «пузырек».
If List(i + 1) < List(i) Then
‘ Найти, куда его поместить. tmp = List(i + 1) j = i
Do
List(j + 1) = List(j) j = j - 1
If j < min Then Exit Do
Loop While List(j) > tmp
List(j + 1) = tmp last_swap = j + 1 i = j - 1
Else i = i - 1
End If
Loop
‘ Обновить переменную min.
Min = last_swap + 1
Loop
End Sub
==========238
Для того чтобы протестировать алгоритм пузырьковой сортировки при помощи
программы Sort, поставьте галочку в поле Sorted (Отсортированные) в области
Initial Ordering (Первоначальный порядок). Введите число элементов в поле
#Unsorted (Число несортированных). После нажатия на кнопку Go (Начать),
программа создает и сортирует список, а затем переставляет случайно
выбранные пары элементов. Например, если вы введете число 10 в поле
#Unsorted, программа переставит 5 пар чисел, то есть 10 элементов окажутся
не на своих местах.
Для второго варианта первоначального алгоритма, программа сохраняет элемент
во временной переменной при перемещении на несколько шагов. Этот происходит
еще быстрее, если использовать функцию API MemCopy. Алгоритм пузырьковой
сортировки в программе FastSort, используя функцию MemCopy, сортирует
элементы в 50 или 75 раз быстрее, чем первоначальная версия, реализованная
в программе Sort.
В табл. 9.2 приведено время выполнения пузырьковой сортировки 2000
элементов на компьютере с процессором Pentium с тактовой частотой 90 МГц в
зависимости от степени первоначальной упорядоченности списка. Из таблицы
видно, что алгоритм пузырьковой сортировки обеспечивает хорошую
производительность, только если список с самого начала почти отсортирован.
Алгоритм быстрой сортировки, который описывается далее в этой главе,
способен отсортировать тот же список из 2000 элементов примерно за 0,12
сек, независимо от первоначального порядка расположения элементов в списке.
Пузырьковая сортировка может превзойти этот результат, только если примерно
97 процентов списка было упорядочено до начала сортировки.
=====239
@Таблица 9.2. Время пузырьковой сортировки 2.000 элементов
Несмотря на то, что пузырьковая сортировка медленнее, чем многие другие алгоритмы, у нее есть свои применения. Пузырьковая сортировка часто дает наилучшие результаты, если список изначально уже почти упорядочен. Если программа управляет списком, который сортируется при создании, а затем к нему добавляются новые элементы, пузырьковая сортировка может быть лучшим выбором.
Быстрая сортировка
Быстрая сортировка (quicksort) — рекурсивный алгоритм, который использует
подход «разделяй и властвуй». Если сортируемый список больше, чем
минимальный заданный размер, процедура быстрой сортировки разбивает его на
два подсписка, а затем рекурсивно вызывает себя для сортировки двух
подсписков.
Первая версия алгоритма быстрой сортировки, обсуждаемая здесь, достаточно
проста. Если алгоритм вызывается для подсписка, содержащего не более одного
элемента, то подсписок уже отсортирован, и подпрограмма завершает работу.
Иначе, процедура выбирает какой-либо элемент из списка и использует его для
разбиения списка на два подсписка. Она помещает элементы, которые меньше,
чем выбранный элементы в первый подсписок, а остальные — во второй, и затем
рекурсивно вызывает себя для сортировки двух подсписков.
Public Sub QuickSort(List() As Long, ByVal min as Integer, _
ByVal max As Integer)
Dim med_value As Long
Dim hi As Integer
Dim lo As Integer
‘ Если осталось менее 1 элемента, подсписок отсортирован.
If min >= max Then Exit Sub
‘ Выбрать значение для деления списка. med_value = list(min) lo = min hi = max
Do
Просмотр от hi до значения < med_value.
Do While list(hi) >= med_value hi = hi - 1
If hi = hi Then Exit Do
Loop
If lo >= hi Then lo = hi list(hi) = med_value
Exit Do
End If
‘ Поменять местами значения lo и hi. list(hi) = list(lo)
Loop
‘ Рекурсивная сортировка двух подлистов.
QuickSort list(), min, lo - 1
QuickSort list(), lo + 1, max
End Sub
=========240
Есть несколько важных моментов в этой версии алгоритма, которые стоит
упомянуть. Во-первых, значение med_value для деления списка не входит ни в
один подсписок. Это означает, что в двух подсписках содержится на одни
элемент меньше, чем в исходном списке. Т.к. число рассматриваемых элементов
уменьшается, то в конечном итоге алгоритм завершит работу.
Эта версия алгоритма использует в качестве разделителя первый элемент в
списке. В идеале, это значение должно было бы находиться где-то в середине
списка, так чтобы два подсписка были примерно равного размера. Тем не
менее, если элементы первоначально почти отсортированы, то первый элемент —
наименьший в списке. При этом алгоритм не поместит ни одного элемента в
первый подсписок, и все элементы во второй. Последовательность действий
алгоритма будет примерно такой, как показано на рис. 9.4.
В этом случае каждый вызов подпрограммы требует порядка O(N) шагов для
перемещения всех элементов во второй подсписок. Т.к. алгоритм рекурсивно
вызывает себя N - 1 раз, время его выполнения будет порядка O(N2), что не
лучше, чем у ранее рассмотренных алгоритмов. Ситуацию еще более ухудшает
то, что уровень вложенности рекурсии алгоритма N - 1. Для больших списков
огромная глубина рекурсии приведет к переполнению стека и сбою в работе
программы.
=========242
@Рис. 9.4. Быстрая сортировка упорядоченного списка
Существует много стратегий выбора разделительного элемента. Можно
использовать элемент из середины списка. Это может оказаться неплохим
выбором, тем не менее, может оказаться и так, что это окажется наименьший
или наибольший элемент списка. При этом один подсписок будет намного
больше, чем другой, что приведет к снижению производительности до порядка
O(N2) и глубокому уровню рекурсии.
Другая стратегия может заключаться в том, чтобы просмотреть весь список,
вычислить среднее арифметическое всех значений, и использовать его в
качестве разделительного значения. Этот подход будет давать неплохие
результаты, но потребует дополнительных усилий. Дополнительный проход со
сложностью порядка O(N) не изменит теоретическое время выполнения
алгоритма, но снизит общую производительность.
Третья стратегия — выбрать средний из элементов в начале, конце и середине
списка. Преимущество этого подхода в быстроте, потому что потребуется
выбрать всего три элемента. При этом гарантируется, что этот элемент не
является наибольшим или наименьшим в списке, и вероятно окажется где-то в
середине списка.
И, наконец, последняя стратегия, которая используется в программе Sort,
заключается в случайном выборе элемента из списка. Возможно, это будет
неплохим выбором. Даже если это не так, возможно на следующем шаге
алгоритм, возможно, сделает лучший выбор. Вероятность постоянного выпадения
наихудшего случая очень мала.
Интересно, что этот метод превращает ситуацию «небольшая вероятность того,
что всегда будет плохая производительность» в ситуацию «всегда небольшая
вероятность плохой производительности». Это довольно запутанное утверждение
объясняется в следующих абзацах.
При использовании других методов выбора точки раздела, существует небольшая
вероятность того, что при определенной организации списка время сортировки
будет порядка O(N2), Хотя маловероятно, что подобная организация списка в
начале сортировки встретится на самом деле, тем не менее, время выполнения
при этом будет определенно порядка O(N2), неважно почему. Это то, что можно
назвать «небольшой вероятностью того, что всегда будет плохая
производительность».
===========242
При случайном выборе точки раздела первоначальное расположение элементов не
влияет на производительность алгоритма. Существует небольшая вероятность
неудачного выбора элемента, но вероятность того, что это будет происходить
постоянно, чрезвычайно мала. Это можно обозначить как «всегда небольшая
вероятность плохой производительности». Независимо от первоначальной
организации списка, очень маловероятно, что производительность алгоритма
будет порядка O(N2).
Тем не менее, все еще остается ситуация, которая может вызвать проблемы при
использовании любого из этих методов. Если в списке очень мало различных
значений в списке, алгоритм заносит множество одинаковых значений в
подсписок при каждом вызове. Например, если каждый элемент в списке имеет
значение 1, последовательность выполнения будет такой, как показано на рис.
9.5. Это приводит к большому уровню вложенности рекурсии и дает
производительность порядка O(N2).
Похожее поведение происходит также при наличии большого числа повторяющихся
значений. Если список состоит из 10.000 элементов со значениями от 1 до 10,
алгоритм довольно быстро разделит список на подсписки, каждый из которых
содержит только одно значение.
Наиболее простой выход — игнорировать эту проблему. Если вы знаете, что
данные не имеют такого распределения, то проблемы нет. Если данные имеют
небольшой диапазон значений, то вам стоит рассмотреть другой алгоритм
сортировки. Описываемые далее в этой главе алгоритмы сортировки подсчетом и
блочной сортировки очень быстро сортируют списки, данных в которых
находятся в узком диапазоне.
Можно внести еще одно небольшое улучшение в алгоритм быстрой сортировки.
Подобно многих другим более сложным алгоритмам, описанным далее в этой
главе, быстрая сортировка — не самый лучший выбор для сортировки небольших
списков. Благодаря своей простоте, сортировка выбором быстрее при
сортировке примерно десятка записей.
@Рис. 9.5. Быстрая сортировка списка из единиц
==========243
@Таблица 9.3. Время быстрой сортировки 20.000 элементов
Можно улучшить производительность быстрой сортировки, если прекратить
рекурсию до того, как подсписки уменьшатся до нуля, и использовать для
завершения работы сортировку выбором. В табл. 9.3 приведено время, которое
занимает выполнение быстрой сортировки 20.000 элементов на компьютере с
процессором Pentium с тактовой частотой 90 МГц, если останавливать
сортировку при достижении подсписками определенного размера. В этом тесте
оптимальное значение этого параметра было равно 15.
Следующий код демонстрирует доработанный алгоритм:
Public Sub QuickSort*List() As Long, ByVal min As Long, ByVal max As Long)
Dim med_value As Long
Dim hi As Long
Dim lo As Long
Dim i As Long
‘ Если в списке больше, чем CutOff элементов,
‘ завершить его сортировку процедурой SelectionSort.
If max - min < cutOff Then
SelectionSort List(), min, max
Exit Sub
End If
‘ Выбрать разделяющее значение. i = Int((max - min + 1) * Rnd + min) med_value = List(i)
‘ Переместить его вперед.
List(i) = List(min)
lo = min hi = max
Do
‘ Просмотр сверху вниз от hi до значения < med_value.
Do While List(hi) >= med_value hi = hi - 1
If hi = hi Then Exit Do
Loop
If lo >= hi Then lo = hi
List(hi) = med_value
Exit Do
End If
‘ Поменять местами значения lo и hi.
List(hi) = List(lo)
Loop
‘ Сортировать два подсписка.
QuickSort List(), min, lo - 1
QuickSort List(), lo + 1, max
End Sub
=======244
Многие программисты выбирают алгоритм быстрой сортировки, т.к. он дает хорошую производительность в большинстве обстоятельств.
Сортировка слиянием
Как и быстрая сортировка, сортировка слиянием (mergesort) — это рекурсивный
алгоритм. Он также разделяет список на два подсписка, и рекурсивно
сортирует подсписки.
Сортировка слиянием делит список пополам, формируя два подсписка
одинакового размера. Затем подсписки рекурсивно сортируются, и
отсортированные подсписки сливаются, образуя полностью отсортированный
список.
Хотя этап слияния легко понять, это наиболее интересная часть алгоритма.
Подсписки сливаются во временный массив, и результат копируется в
первоначальный список. Создание временного массива может быть недостатком,
особенно если размер элементов велик. Если размер временного размера очень
большой, он может приводить к обращению к файлу подкачки и значительно
снижать производительность. Работа с временным массивом также приводит к
тому, что большая часть времени уходит на копирование элементов между
массивами.
Так же, как и в случае с быстрой сортировкой, можно ускорить выполнение
сортировки слиянием, остановив рекурсию, когда подсписки достигают
определенного минимального размера. Затем можно использовать сортировку
выбором для завершения работы.
=========245
Public Sub Mergesort(List() As Long, Scratch() As Long, _
ByVal min As Long, ByVal max As Long)
Dim middle As Long
Dim i1 As Long
Dim i2 As Long
Dim i3 As Long
‘ Если в списке больше, чем CutOff элементов,
‘ завершить его сортировку процедурой SelectionSort.
If max - min < CutOff Then
Selectionsort List(), min, max
Exit Sub
End If
‘ Рекурсивная сортировка подсписков. middle = max 2 + min 2
Mergesort List(), Scratch(), min, middle
Mergesort List(), Scratch(), middle + 1, max
‘ Слить отсортированные списки. i1 = min ‘ Индекс списка 1. i2 = middle + 1 ‘ Индекс списка 2. i3 = min ‘ Индекс объединенного списка.
Do While i1 NumItems Then
Search = 0 " Элемент не найден.
Else
Search = i " Элемент найден.
End If
End Function
Так как этот алгоритм проверяет элементы последовательно, то он находит
элементы в начале списка быстрее, чем элементы, расположенные в конце.
Наихудший случай для этого алгоритма возникает, если элемент находится в
конце списка или вообще не присутствует в нем. В этих случаях, алгоритм
проверяет все элементы в списке, поэтому время его выполнения сложность в
наихудшем случае порядка O(N).
@Рис. 10.1. Программа Search
========266
Если элемент находится в списке, то в среднем алгоритм проверяет N/2
элементов до того, как обнаружит искомый. Таким образом, в усредненном
случае время выполнения алгоритма также порядка O(N).
Хотя алгоритмы, которые выполняются за время порядка O(N), не являются
очень быстрыми, этот алгоритм достаточно прост, чтобы давать на практике
неплохие результаты. Для небольших списков этот алгоритм имеет приемлемую
производительность.
Поиск в упорядоченных списках
Если список упорядочен, то можно слегка модифицировать алгоритм полного
перебора, чтобы немного повысить его производительность. В этом случае,
если во время выполнения поиска алгоритм находит элемент со значением,
большим, чем значение искомого элемента, то он завершает свою работу. При
этом искомый элемент не находится в списке, так как иначе он бы встретился
раньше.
Например, предположим, что мы ищем значение 12 и дошли до значения 17. При
этом мы уже прошли тот участок списка, в котором мог бы находится элемент
со значением 12, значит, элемент 12 в списке отсутствует. Следующий код
демонстрирует доработанную версию алгоритма поиска полным перебором:
Public Function LinearSearch(target As Long) As Long
Dim i As Long
NumSearches = 0
For i = 1 To NumItems
NumSearches = NumSearches + 1
If List(i) >= target Then Exit For
Next i
If i > NumItems Then
LinearSearch = 0 " Элемент не найден.
ElseIf List(i) target Then
LinearSearch = 0 " Элемент не найден.
Else
LinearSearch = i " Элемент найден.
End If
End Function
Эта модификация уменьшает время выполнения алгоритма, если элемент
отсутствует в списке. Предыдущей версии поиска требовалось проверить весь
список до конца, если искомого элемента в нем не было. Новая версия
остановится, как только обнаружит элемент больший, чем искомый.
Если искомый элемент расположен случайно между наибольшим и наименьшим
элементами в списке, то в среднем алгоритму понадобится порядка O(N) шагов,
чтобы определить, что искомый элемент отсутствует в списке. Время
выполнения при этом имеет тот же порядок, но на практике его
производительность будет немного выше. Программа Search использует эту
версию алгоритма.
======267
Поиск в связных списках
Поиск методом полного перебора — это единственный способ поиска в связных
списках. Так как доступ к элементам возможен только при помощи указателей
NextCell на следующий элемент, то необходимо проверить по очереди все
элементы с начала списка, чтобы найти искомый.
Так же, как и в случае поиска полным перебором в массиве, если список
упорядочен, то можно прекратить поиск, если найдется элемент со значением,
большим, чем значение искомого элемента.
Public Function LListSearch(target As Long) As SearchCell
Dim cell As SearchCell
NumSearches = 0
Set cell = ListTop.NextCell
Do While Not (cell Is Nothing)
NumSearches = NumSearches + 1
If cell.Value >= target Then Exit Do
Set cell = cell.NextCell
Loop
If Not (cell Is Nothing) Then
If cell.Value = target Then
Set LListSearch = cell " Элемент найден.
End If
End If
End Function
Программа Search использует этот алгоритм для поиска элементов в связном
списке. Этот алгоритм выполняется немного медленнее, чем алгоритм полного
перебора в массиве из-за дополнительных накладных расходов, которые связаны
с управлением указателями на объекты. Заметьте, что программа Search строит
связные списки, только если список содержит не более 10.000 элементов.
Чтобы алгоритм выполнялся немного быстрее, в него можно внести еще одно
изменение. Если хранить указатель на конец списка, то можно добавить в
конец списка ячейку, которая будет содержать искомый элемент. Этот элемент
называется сигнальной меткой (sentinel), и служит для тех же целей, что и
сигнальные метки, описанные во 2 главе. Это позволяет обрабатывать особый
случай конца списка так же, как и все остальные.
В этом случае, добавление метки в конец списка гарантирует, что в конце
концов искомый элемент будет найден. При этом программа не может выйти за
конец списка, и нет необходимости проверять условие Not (cell Is Nothing) в
каждом цикле While.
Public Function SentinelSearch(target As Long) As SearchCell
Dim cell As SearchCell
Dim sentinel As New SearchCell
NumSearches = 0
" Установить сигнальную метку. sentinel.Value = target
Set ListBottom.NextCell = sentinel
" Найти искомый элемент.
Set cell = ListTop.NextCell
Do While cell.Value < target
NumSearches = NumSearches + 1
Set cell = cell.NextCell
Loop
" Определить найден ли искомый элемент.
If Not ((cell Is sentinel) Or _
(cell.Value target)) _
Then
Set SentinelSearch = cell " Элемент найден.
End If
" Удалить сигнальную метку.
Set ListBottom.NextCell = Nothing
End Function
Хотя может показаться, что это изменение незначительно, проверка Not (cell
Is Nothing) выполняется в цикле, который вызывается очень часто. Для
больших списков этот цикл вызывается множество раз, и выигрыш времени
суммируется. В Visual Basic, этот версия алгоритма поиска в связных списках
выполняется на 20 процентов быстрее, чем предыдущая версия. В программе
Search приведены обе версии этого алгоритма, и вы можете сравнить их.
Некоторые алгоритмы используют потоки для ускорения поиска в связных
списках. Например, при помощи указателей в ячейках списка можно
организовать список в виде двоичного дерева. Поиск элемента с
использованием этого дерева займет время порядка O(log(N)), если дерево
сбалансировано. Такие структуры данных уже не являются просто списками,
поэтому мы не обсуждаем их в этой главе. Чтобы больше узнать о деревьях,
обратитесь к 6 и 7 главам
Двоичный поиск
Как уже упоминалось в предыдущих разделах, поиск полным перебором
выполняется очень быстро для небольших списков, но для больших списков
намного быстрее выполняется двоичный поиск. Алгоритм двоичного поиска
(binary search) сравнивает элемент в середине списка с искомым. Если
искомый элемент меньше, чем найденный, то алгоритм продолжает поиск в
первой половине списка, если больше — в правой половине. На рис. 10.2 этот
процесс изображен графически.
Хотя по своей природе этот алгоритм является рекурсивным, его достаточно
просто записать и без применения рекурсии. Так как этот алгоритм прост для
понимания в любом варианте (с рекурсией или без), то мы приводим здесь его
нерекурсивную версию, которая содержит меньше вызовов функций.
Основная заключенная в этом алгоритме идея проста, но детали ее реализации
достаточно сложны. Программе приходится аккуратно отслеживать часть
массива, которая может содержать искомый элемент, иначе она может его
пропустить.
Алгоритм использует две переменные, min и max, в которых находятся
минимальный и максимальный индексы ячеек массива, которые могут содержать
искомый элемент. Во время выполнения алгоритма, индекс искомой ячейки
всегда будет лежать между min и max. Другими словами, min = NumEntries Then
LocateItem = HASH_NOT_FOUND pos = -1
Exit Function
End If
pos = (pos + 1) Mod NumEntries probes = probes + 1
Loop
End Function
Программа Linear демонстрирует открытую адресацию с линейной проверкой.
Заполнив поле Table Size (Размер таблицы) и нажав на кнопку Create table
(Создать таблицу), можно создавать хеш-таблицы различных размеров. Затем
можно ввести значение элемента и нажать на кнопку Add (Добавить) или Find
(Найти), чтобы вставить или найти элемент в таблице.
Чтобы добавить в таблицу сразу несколько случайных значений, введите число
элементов, которые вы хотите добавить и максимальное значение, которое они
могут иметь в области Random Items (Случайные элементы), и затем нажмите на
кнопку Create Items (Создать элементы).
После завершения программой какой-либо операции она выводит статус операции
(успешное или безуспешное завершение) и длину тестовой последовательности.
Она также выводит среднюю длину успешной и безуспешной тестовой
последовательностей. Программа вычисляет среднюю длину тестовой
последовательности, выполняя поиск всех значений от 1 до максимального
значения в таблице.
В табл. 11.1 приведена средняя длина успешных и безуспешных тестовых
последовательностей, полученных в программе Linear для таблицы со 100
ячейками, элементы в которых находятся в диапазоне от 1 до 999. Из таблицы
видно, что производительность алгоритма падает по мере заполнения таблицы.
Является ли производительность приемлемой, зависит от того, как
используется таблица. Если программа тратит большую часть времени на поиск
значений, которые есть в таблице, то производительность может быть
неплохой, даже если таблица практически заполнена. Если же программа часто
ищет значения, которых нет в таблице, то производительность может быть
очень низкой, если таблица переполнена.
Как правило, хеширование обеспечивает приемлемую производительность, не
расходуя при этом слишком много памяти, если заполнено от 50 до 75
процентов таблицы. Если таблица заполнена больше, чем на 75 процентов, то
производительность падает. Если таблица заполнена меньше, чем на 50
процентов, то она занимает больше памяти, чем это необходимо. Это делает
открытую адресацию хорошим примером пространственно-временного компромисса.
Увеличивая хеш-таблицу, можно уменьшить время, необходимое для вставки или
поиска элементов.
=======297
@Таблица 11.1. Длина успешной и безуспешной тестовых последовательностей
Первичная кластеризация
Линейная проверка имеет одно неприятное свойство, которое называется
первичной кластеризацией (primary clustering). После добавления большого
числа элементов в таблицу, возникает конфликт между новыми элементами и уже
имеющимися кластерами, при этом для вставки нового элемента нужно обойти
кластер, чтобы найти пустую ячейку.
Чтобы увидеть, как образуются кластеры, предположим, что вначале имеется
пустая хеш-таблица, которая может содержать N элементов. Если выбрать
случайное число и вставить его в таблицу, то вероятность того, что элемент
займет любую заданную позицию P в таблице, равна 1/N.
При вставке второго случайно выбранного элемента, он может отобразиться на
ту же позицию с вероятностью 1/N. Из-за конфликта в этом случае он
помещается в позицию P + 1. Также существует вероятность 1/N, что элемент и
должен располагаться в позиции P + 1, и вероятность 1/N, что он должен
находиться в позиции P - 1. Во всех этих трех случаях новый элемент
располагается рядом с предыдущим. Таким образом, в целом существует
вероятность 3/N того, что 2 элемента окажутся расположенными вблизи друг от
друга, образуя небольшой кластер.
По мере роста кластера вероятность того, что следующие элементы будут
располагаться вблизи кластера, возрастает. Если в кластере находится два
элемента, то вероятность того, что очередной элемент присоединится к
кластеру, равна 4/N, если в кластере четыре элемента, то эта вероятность
равна 6/N, и так далее.
Что еще хуже, если кластер начинает расти, то его рост продолжается до тех
пор, пока он не столкнется с соседним кластером. Два кластера сливаются,
образуя кластер еще большего размера, который растет еще быстрее, сливается
с другими кластерами и образует еще большие кластеры.
======298
В идеальном случае хеш-таблица должна быть наполовину пуста, и элементы в
ней должны чередоваться с пустыми ячейками. Тогда с вероятностью 50
процентов алгоритм сразу же найдет пустую ячейку для нового добавляемого
элемента. Также существует 50-процентная вероятность того, что он найдет
пустую ячейку после проверки всего лишь двух позиций в таблице. Средняя
длина тестовой последовательности равна 0,5 * 1 + 0,5 * 2 = 1,5.
В наихудшем случае все элементы в таблице будут сгруппированы в один
гигантский кластер. При этом все еще есть 50-процентная вероятность того,
что алгоритм сразу найдет пустую ячейку, в которую можно поместить новый
элемент. Тем не менее, если алгоритм не найдет пустую ячейку на первом
шаге, то поиск свободной ячейки потребует гораздо больше времени. Если
элемент должен находиться на первой позиции кластера, то алгоритму придется
проверить все элементы в кластере, чтобы найти свободную ячейку. В среднем
для вставки элемента при таком распределении потребуется гораздо больше
времени, чем когда элементы равномерно распределены по таблице.
На практике, степень кластеризации будет находиться между этими двумя
крайними случаями. Вы можете использовать программу Linear для исследования
эффекта кластеризации. Запустите программу и создайте хеш-таблицу со 100
ячейками, а затем добавьте 50 случайных элементов со значениями до 999. Вы
обнаружите, что образовалось несколько кластеров. В одном из тестов 38 из
50 элементов стали частью кластеров. Если добавить еще 25 элементов к
таблице, то большинство элементов будут входить в кластеры. В другом тесте
70 из 75 элементов были сгруппированы в кластеры.
Упорядоченная линейная проверка
При выполнении поиска в упорядоченном списке методом полного перебора,
можно остановить поиск, если найдется элемент со значением большим, чем
искомое. Так как при этом возможное положение искомого элемента уже позади,
значит искомый элемент отсутствует в списке.
Можно использовать похожую идею при поиске в хеш-таблице. Предположим, что
можно организовать элементы в хеш-таблице таким образом, что значения в
каждой тестовой последовательности находятся в порядке возрастания. Тогда
при выполнении тестовой последовательности во время поиска элемента можно
прекратить поиск, если встретится элемент со значением, большим искомого. В
этом случае позиция, в которой должен был бы находиться искомый элемент,
уже осталась позади, и значит элемента нет в таблице.
Public Function LocateItem(Value As Long, pos As Integer, _ probes As Integer) As Integer
Dim new_value As Long
probes = 1 pos = (Value Mod m_NumEntries)
Do new_value = m_HashTable(pos)
" Элемента в таблице нет.
If new_value = UNUSED Or probes > NumEntries Then
LocateItem = HASH_NOT_FOUND pos = -1
Exit Function
End If
" Элемент найден или его нет в таблице.
If new_value >= Value Then Exit Do
pos = (pos + 1) Mod NumEntries probes = probes + 1
Loop
If Value = new_value Then
LocateItem = HASH_FOUND
Else
LocateItem = HASH_NOT_FOUND
End If
End Function
Для того, чтобы этот метод работал, необходимо организовать элементы в хеш-
таблице так, чтобы при выполнении тестовой последовательности они
встречались в возрастающем порядке. Существует достаточно простой метод
вставки элементов, который гарантирует такое расположение элементов.
Когда в таблицу вставляется новый элемент, для него выполняется тестовая
последовательность. Если найдется свободная ячейка, то элемент вставляется
в эту позицию и процедура завершена. Если встречается элемент, значение
которого больше значения нового элемента, то они меняются местами и
продолжается выполнение тестовой последовательности для большего элемента.
При этом может встретиться элемент с еще большим значением. Тогда элементы
снова меняются местами, и выполняется поиск нового местоположения для этого
элемента. Этот процесс продолжается до тех пор, пока, в конце концов, не
найдется свободная ячейка, при этом возможно несколько элементов меняются
местами.
========299-300
Public Function InsertItem(ByVal Value As Long, pos As Integer,_ probes
As Integer) As Integer
Dim new_value As Long
Dim status As Integer
" Проверить, заполнена ли таблица.
If m_NumUnused < 1 Then
" Поиск элемента. status = LocateItem(Value, pos, probes)
If status = HASH_FOUND Then
InsertItem = HASH_FOUND
Else
InsertItem = HASH_TABLE_FULL pos = -1
End If
Exit Function
End If
probes = 1 pos = (Value Mod m_NumEntries)
Do new_value = m_HashTable(pos)
" Если значение найдено, поиск завершен.
If new_value = Value Then
InsertItem = HASH_FOUND
Exit Function
End If
" Если ячейка свободна, элемент должен находиться в ней.
If new_value = UNUSED Then m_HashTable(pos) = Value
HashForm.TableControl(pos).Caption = Format$(Value)
InsertItem = HASH_INSERTED m_NumUnused = m_NumUnused - 1
Exit Function
End If
" Если значение в ячейке таблицы больше значения
" элемента, поменять их местами и продолжить.
If new_value > Value Then m_HashTable(pos) = Value
Value = new_value
End If
pos = (pos + 1) Mod NumEntries probes = probes + 1
Loop
End Function
Программа Ordered демонстрирует открытую адресацию с упорядоченной линейной
проверкой. Она идентична программе Linear, но использует упорядоченную хеш-
таблицу.
В табл. 11.2 приведена средняя длина успешной и безуспешной тестовых
последовательностей при использовании линейной и упорядоченной линейной
проверок. Средняя длина успешной проверки для обоих методов почти
одинакова, но в случае неуспеха упорядоченная линейная проверка выполняется
намного быстрее. Разница в особенности заметна, если хеш-таблица заполнена
более, чем на 70 процентов.
=========301
@Таблица 11.2. Длина поиска при использовании линейной и упорядоченной линейной проверки
В обоих методах для вставки нового элемента требуется примерно одинаковое
число шагов. Чтобы вставить элемент K в таблицу, каждый из методов начинает
с позиции (K Mod NumEntries) и перемещается по таблице до тех пор, пока не
найдет свободную ячейку. Во время упорядоченного хеширования может
потребоваться поменять вставляемый элемент на другие в его тестовой
последовательности. Если элементы представляют собой записи большого
размера, то на это может потребоваться больше времени, особенно если записи
находятся на диске или каком-либо другом медленном запоминающем устройстве.
Упорядоченная линейная проверка определенно является лучшим выбором, если
вы знаете, что программе придется совершать большое число безуспешных
операций поиска. Если программа будет часто выполнять поиск элементов,
которых нет в таблице, или элементы таблицы имеют большой размер и
перемещать их достаточно сложно, то можно получить лучшую
производительность при использовании неупорядоченной линейной проверки.
Квадратичная проверка
Один из способов уменьшить первичную кластеризацию состоит в том, чтобы использовать хеш-функцию следующего вида:
Hash(K, P) = (K + P2) Mod N где P = 0, 1, 2, ...
Предположим, что при вставке элемента в хеш-таблицу он отображается в
кластер, образованный другими элементами. Если элемент отображается в
позицию возле начала кластера, то возникнет еще несколько конфликтов
прежде, чем найдется свободная ячейка для элемента. По мере роста параметра
P в тестовой функции, значение этой функции быстро меняется. Это означает,
что позиция, в которую попадет элемент в конечном итоге, возможно, окажется
далеко от кластера.
=======302
На рис. 11.8 показана хеш-таблица, содержащая большой кластер элементов. На
нем также показаны тестовые последовательности, которые возникают при
попытке вставить два различных элемента в позиции, занимаемые кластером.
Обе эти тестовые последовательности заканчиваются в точке, которая не
прилегает к кластеру, поэтому после вставки этих элементов размер кластера
не увеличивается.
Следующий код демонстрирует поиск элемента с использованием квадратичной
проверки (quadratic probing):
Public Function LocateItem(Value As Long, pos As Integer, probes As
Integer) As Integer
Dim new_value As Long
probes = 1 pos = (Value Mod m_NumEntries)
Do new_value = m_HashTable(pos)
" Элемент найден.
If new_value = Value Then
LocateItem = HASH_FOUND
Exit Function
End If
" Элемента нет в таблице.
If new_value = UNUSED Or probes > NumEntries Then
LocateItem = HASH_NOT_FOUND pos = -1
Exit Function
End If
pos = (Value + probes * probes) Mod NumEntries probes = probes + 1
Loop
End Function
Программа Quad демонстрирует открытую адресацию с использованием
квадратичной проверки. Она аналогична программе Linear, но использует
квадратичную, а не линейную проверку.
В табл. 11.3 приведена средняя длина тестовых последовательностей,
полученных в программах Linear и Quad для хеш-таблицы со 100 ячейками,
значения элементов в которой находятся в диапазоне от 1 до 999.
Квадратичная проверка обычно дает лучшие результаты.
@Рис. 11.8. Квадратичная проверка
======303
@Таблица 11.3. Длина поиска при использовании линейной и квадратичной проверки
Квадратичная проверка также имеет некоторые недостатки. Из-за способа
формирования тестовой последовательности, нельзя гарантировать, что она
обойдет все ячейки в таблице, что означает, что иногда в таблицу нельзя
будет вставить элемент, даже если она не заполнена до конца.
Например, рассмотрим небольшую хеш-таблицу, состоящую всего из шести ячеек.
Тестовая последовательность для числа 3 будет следующей:
3
3 + 12 = 4 = 4 (Mod 6)
3 + 22 = 7 = 1 (Mod 6)
3 + 32 = 12 = 0 (Mod 6)
3 + 42 = 19 = 1 (Mod 6)
3 + 52 = 28 = 4 (Mod 6)
3 + 62 = 39 = 3 (Mod 6)
3 + 72 = 52 = 4 (Mod 6)
3 + 82 = 67 = 1 (Mod 6)
3 + 92 = 84 = 0 (Mod 6)
3 + 102 = 103 = 1 (Mod 6)
и так далее.
Эта тестовая последовательность обращается к позициям 1 и 4 дважды перед
тем, как обратиться к позиции 3, и никогда не попадает в позиции 2 и 5.
Чтобы пронаблюдать этот эффект, создайте в программе Quad хеш-таблицу с
шестью ячейками, а затем вставьте элементы 1, 3, 4, 6 и 9. Программа
определит, что таблица заполнена целиком, хотя две ячейки и остались
неиспользованными. Тестовая последовательность для элемента 9 не обращается
к элементам 2 и 5, поэтому программа не может вставить в таблицу новый
элемент.
=======304
Можно показать, что квадратичная тестовая последовательность будет
обращаться, по меньшей мере, к N/2 ячеек таблицы, если размер таблицы N —
простое число. Хотя при этом гарантируется некоторый уровень
производительности, все равно могут возникнуть проблемы, если таблица почти
заполнена. Так как производительность для почти заполненной таблицы в любом
случае сильно падает, то возможно лучше будет просто увеличить размер хеш-
таблицы, а не беспокоиться о том, сможет ли тестовая последовательность
найти свободную ячейку.
Не столь очевидная проблема, которая возникает при применении квадратичной
проверки, заключается в том, что хотя она устраняет первичную
кластеризацию, во время нее может возникать похожая проблема, которая
называется вторичной кластеризацией (secondary clustering). Если два
элемента отображаются в одну ячейку, для них будет выполняться одна и так
же тестовая последовательность. Если множество элементов отображаются на
одну из ячеек таблицы, они образуют вторичный кластер, который распределен
по хеш-таблице. Если появляется новый элемент с тем же самым начальным
значением, для него приходится выполнять длительную тестовую
последовательность, прежде чем он обойдет элементы во вторичном кластере.
На рис. 11.9 показана хеш-таблица, которая может содержать 10 ячеек. В
таблице находятся элементы 2, 12, 22 и 32, которые все изначально
отображаются в позицию 2. Если попытаться вставить в таблицу элемент 42, то
нужно будет выполнить длительную тестовую последовательность, которая
обойдет все эти элементы, прежде чем найдет свободную ячейку.
Псевдослучайная проверка
Степень кластеризации растет, если в кластер добавляются элементы, которые
отображаются на уже занятые кластером ячейки. Вторичная кластеризация
возникает, когда для элементов, которые первоначально должны занимать одну
и ту же ячейку, выполняется одна и та же тестовая последовательность, и
образуется вторичный кластер, распределенный по хеш-таблице. Можно
устранить оба эти эффекта, если сделать так, чтобы для разных элементов
выполнялись различные тестовые последовательности, даже если элементы
первоначально и должны были занимать одну и ту же ячейку.
Один из способов сделать это заключается в использовании в тестовой
последовательности генератора псевдослучайных чисел. Для вычисления
тестовой последовательности для элемента, его значение используется для
инициализации генератора случайных чисел. Затем для построения тестовой
последовательности используются последовательные случайные числа,
получаемые на выходе генератора. Это называется псевдослучайной проверкой
(pseudo-random probing).
Когда позднее требуется найти элемент в хеш-таблице, генератор случайных
чисел снова инициализируется значением элемента, при этом на выходе
генератора мы получим ту же самую последовательность чисел, которая
использовалась для вставки элемента в таблицу. Используя эти числа, можно
воссоздать исходную тестовую последовательность и найти элемент.
@Рис. 11.9. Вторичная кластеризация
==========305
Если используется качественный генератор случайных чисел, то разные
значения элементов будут давать различные случайные числа и соответственно
разные тестовые последовательности. Даже если два значения изначально
отображаются на одну и ту же ячейку, то следующие позиции в тестовой
последовательности будут уже различными. В этом случае в хеш-таблице не
будет возникать первичная или вторичная кластеризация.
Можно проинициализировать генератор случайных чисел Visual Basic, используя
начальное число, при помощи двух строчек кода:
Rnd -1
Randomize seed_value
Оператор Rnd дает одну и ту же последовательность чисел после инициализации одним и тем же начальным числом. Следующий кода показывает, как можно выполнять поиск элемента с использованием псевдослучайной проверки:
Public Function LocateItem(Value As Long, pos As Integer, _ probes As Integer) As Integer
Dim new_value As Long
" Проинициализировать генератор случайных чисел.
Rnd -1
Randomize Value
probes = 1 pos = Int(Rnd * m_NumEntries)
Do new_value = m_HashTable(pos)
" Элемент найден.
If new_value = Value Then
LocateItem = HASH_FOUND
Exit Function
End If
" Элемента нет в таблице.
If new_value = UNUSED Or probes > NumEntries Then
LocateItem = HASH_NOT_FOUND pos = -1
Exit Function
End If
pos = Int(Rnd * m_NumEntries) probes = probes + 1
Loop
End Function
=======306
Программа Rand демонстрирует открытую адресацию с псевдослучайной
проверкой. Она аналогична программам Linear и Quad, но использует
псевдослучайную, а не линейную или квадратичную проверку.
В табл. 11.4 приведена примерная средняя длина тестовой последовательности,
полученной в программах Quad или Rand для хеш-таблицы со 100 ячейками и
элементами, значения которых находятся в диапазоне от 1 до 999. Обычно
псевдослучайная проверка дает наилучшие результаты, хотя разница между
псевдослучайной и квадратичной проверками не так велика, как между линейной
и квадратичной.
Псевдослучайная проверка также имеет свои недостатки. Так как тестовая
последовательность выбирается псевдослучайно, нельзя точно предсказать,
насколько быстро алгоритм обойдет все элементы в таблице. Если таблица
меньше, чем число возможных псевдослучайных значений, то существует
вероятность того, что тестовая последовательность обратится к одному
значению несколько раз до того, как она выберет другие значения в таблице.
Возможно также, что тестовая последовательность будет пропускать какую-либо
ячейку в таблице и не сможет вставить новый элемент, даже если таблица не
заполнена до конца.
Так же, как и в случае квадратичной проверки, эти эффекты могут вызвать
затруднения, только если таблица почти заполнена. В этом случае увеличение
таблицы дает гораздо больший прирост производительности, чем поиск
неиспользуемых ячеек таблицы.
@Рис. 11.4. Длина поиска при использовании квадратичной и псевдослучайной проверки
=======307
Удаление элементов
Удаление элементов из хеш-таблицы, в которой используется открытая
адресация, выполняется не так просто, как удаление их из таблицы,
использующей связные списки или блоки. Просто удалить элемент из таблицы
нельзя, так как он может находиться в тестовой последовательности другого
элемента.
Предположим, что элемент A находится в тестовой последовательности элемента
B. Если удалить из таблицы элемент A, найти элемент B будет невозможно. Во
время поиска элемента B встретится пустая ячейка, которая осталась после
удаления элемента A, поэтому будет сделан неправильный вывод о том, что
элемент B отсутствует в таблице.
Вместо удаления элемента из хеш-таблицы можно просто пометить его как
удаленный. Можно использовать эту ячейку позднее, если она встретится во
время выполнения вставки нового элемента в таблицу. Если помеченный элемент
встречается во время поиска другого элемента, он просто игнорируется и
тестовая последовательность продолжится.
После того, как большое число элементов будет помечено как удаленные, в хеш-
таблице может оказаться множество неиспользуемых ячеек, и при поиске
элементов достаточно много времени будет уходить на пропуск удаленных
элементов. В конце концов, может потребоваться рехеширование таблицы для
освобождения неиспользуемой памяти.
Рехеширование
Чтобы освободить удаленные элементы из хеш-таблицы, можно выполнить ее рехеширование (rehashing) на месте. Чтобы этот алгоритм мог работать, нужно иметь какой-то способ для определения, было ли выполнено рехеширование элемента. Простейший способ сделать это — определить элементы в виде структур данных, содержащих поле Rehashed.
Type ItemType
Value As Long
Rehashed As Boolean
End Type
Вначале присвоим полю Rehashed значение false. Затем выполним проход по
таблице в поиске ячеек, которые не помечены как удаленные, и для которых
еще не было выполнено рехеширование.
Если такой элемент встретится, то выполняется его удаление из таблицы и
повторное хеширование, при этом выполняется обычная тестовая
последовательность для элемента. Если встречается свободная или помеченная
как удаленная ячейка, элемент размещается в ней, помечается как
рехешированный, и продолжается проверка остальных элементов, для которых
еще не было выполнено рехеширование.
Если при выполнении рехеширования найдется элемент, который уже был помечен
как рехешированный, то тестовая последовательность продолжается. Если затем
встретится элемент, для которого еще не было выполнено рехеширование, то
элементы меняются местами, текущая ячейка помечается как рехешированная и
процесс начинается снова.
======308
Изменение размера хеш-таблиц
Если хеш-таблица становится почти заполненной, производительность
значительно падает. В этом случае может понадобиться увеличение размера
таблицы, чтобы в ней было больше места для элементов. И наоборот, если в
таблице слишком мало ячеек, может потребоваться уменьшить ее, чтобы
освободить занимаемую память. Используя методы, похожие на те, которые
использовались при рехешировании таблицы на месте, можно увеличивать и
уменьшать размер хеш-таблицы.
Чтобы увеличить хеш-таблицу, вначале размер массива, в котором она
находится, увеличивается при помощи оператора Dim Preserve. Затем
выполняется рехеширование таблицы, при этом элементы могут занимать ячейки
в созданной свободной области в конце таблицы. После завершения
рехеширования таблица будет готова к использованию.
Чтобы уменьшить размер таблицы, вначале определим, сколько элементов должно
содержаться в массиве таблицы после уменьшения. Затем выполняем
рехеширование таблицы, причем элементы помещаются только в уменьшенную
часть таблицы. После завершения рехеширования всех элементов, размер
массива уменьшается при помощи оператора ReDim Preserve.
Следующий код демонстрирует рехеширование таблицы с использованием линейной
проверки. Код для рехеширования таблицы с использованием квадратичной или
псевдослучайной проверки выглядит почти так же:
Public Sub Rehash()
Dim i As Integer
Dim pos As Integer
Dim probes As Integer
Dim Value As Long
Dim new_value As Long
" Пометить все элементы как нерехешированные.
For i = 0 To NumEntries - 1 m_HashTable(i).Rehashed = False
Next i
" Поиск нерехешированных элементов.
For i = 0 To NumEntries - 1
If Not m_HashTable(i).Rehashed Then
Value = m_HashTable(i).Value m_HashTable(i).Value = UNUSED
If Value DELETED And Value UNUSED Then
" Выполнить тестовую последовательность
" для этого элемента, пока не найдется свободная,
" удаленная или нерехешированная ячейка. probes = 0
Do pos = (Value + probes) Mod NumEntries new_value = m_HashTable(pos).Value
" Если ячейка свободна или помечена как
" удаленная, поместить элемент в нее.
If new_value = UNUSED Or _ new_value = DELETED _
Then m_HashTable(pos).Value = Value m_HashTable(pos).Rehashed = True
Exit Do
End If
" Если ячейка не помечена как рехешированная,
" поменять их местами и продолжить.
If Not m_HashTable(pos).Rehashed Then m_HashTable(pos).Value = Value m_HashTable(pos).Rehashed = True
Value = new_value probes = 0
Else probes = probes + 1
End If
Loop
End If
End If
Next i
End Sub
Программа Rehash использует открытую адресацию с линейной проверкой. Она аналогична программе Linear, но позволяет также помечать объекты как удаленные и выполнять рехеширование таблицы.
Резюме
Различные типы хеш-таблиц, описанные в этой главе, имеют свои преимущества
и недостатки.
Для хеш-таблиц, которые используют связные списки или блоки можно легко
изменять размер таблицы и удалять из нее элементы. Использование блоков
также позволяет легко работать с таблицами на диске, позволяя считать за
одно обращение к диску сразу множество элементов данных. Тем не менее, оба
эти метода являются более медленными, чем открытая адресация.
Линейная проверка проста и позволяет достаточно быстро вставлять и удалять
элементы из таблицы. Применение упорядоченной линейной проверки позволяет
быстрее, чем в случае неупорядоченной линейной проверки, установить, что
элемент отсутствует в таблице. С другой стороны, вставку элементов в
таблицу при этом выполнить сложнее.
Квадратичная проверка позволяет избежать кластеризации, которая характерна
для линейной проверки, и поэтому обеспечивает более высокую
производительность. Псевдослучайная проверка обеспечивает еще более высокую
производительность, так как при этом удается избавиться как от первичной,
так и от вторичной кластеризации.
В табл. 11.5 приведены преимущества и недостатки различных методов
хеширования.
======310
@Таблица 11.5. Преимущества и недостатки различных методов хеширования
Выбор наилучшего метода хеширования для данного приложения зависит от данных задачи и способов их использования. При применении разных схем достигаются различные компромиссы между занимаемой памятью, скоростью и простотой изменений. Табл. 11.5 может помочь вам выбрать наилучший алгоритм для вашего приложения.
=======311
Глава 12. Сетевые алгоритмы
В 6 и 7 главах обсуждались алгоритмы работы с деревьями. Данная глава посвящена более общей теме сетей. Сети играют важную роль во многих приложениях. Их можно использовать для моделирования таких объектов, как сеть улиц, телефонная или электрическая сеть, водопровод, канализация, водосток, сеть авиаперевозок или железных дорог. Менее очевидна возможность использования сетей для решения таких задач, как разбиение на районы, составление расписания методом критического пути, планирование коллективной работы или распределения работы.
Определения
Как и в определении деревьев, сетью (network) или графом (graph) называется
набор узлов (nodes), соединенных ребрами (edges) или связями (links). Для
графа, в отличие от дерева, не определено понятие родительского или
дочернего узла.
С ребрами сети может быть связано соответствующее направление, тогда в этом
случае сеть называется ориентированной сетью (directed network). Для каждой
связи можно также определить ее цену (cost). Для сети дорог, например, цена
может быть равна времени, которое займет проезд по отрезку дороги,
представленному ребром сети. В телефонной сети цена может быть равна
коэффициенту электрических потерь в кабеле, представленном связью. На рис.
12.1 показана небольшая ориентированная сеть, в которой числа рядом с
ребрами соответствуют цене ребра.
Путем (path) между узлами A и B называется последовательность ребер,
которая связывает два этих узла между собой. Если между любыми двумя узлами
сети есть не больше одного ребра, то путь можно однозначно описать,
перечислив входящие в него узлы. Так как такое описание проще представить
наглядно, то пути по возможности описываются таким образом. На рис. 12.1
путь, проходящий через узлы B, E, F, G,E и D, соединяет узлы B и D.
Циклом (cycle) называется путь который связывает узел с ним самим. Путь E,
F, G, E на рис. 12.1 является циклом. Путь называется простым (simple),
если он не содержит циклов. Путь B, E, F, G, E, D не является простым, так
как он содержит цикл E, F, G, E.
Если существует какой-либо путь между двумя узлами, то должен существовать
и простой путь между ними. Этот путь можно найти, если удалить все циклы из
исходного пути. Например, если заменить цикл E, F, G, E в пути B, E, F, G,
E, D на узел E, то получится простой путь B, E, D, связывающий узлы B и D.
=======313
@Рис. 12.1. Ориентированная сеть с ценой ребер
Сеть называется связной (connected), если между любыми двумя узлами существует хотя бы один путь. В ориентированной сети не всегда очевидно, является ли сеть связной. На рис. 12.2 сеть слева является связной. Сеть справа не является связной, так как не существует пути из узла E в узел C.
Представления сети
В 6 главе было описано несколько представлений деревьев. Большинство из них применимо также и для работы с сетями. Например, представления полными узлами, списком потомков (списком соседей для сетей) или нумерацией связей также могут использоваться для хранения сетей. За описанием этих представлений обратитесь к 6 главе.
@Рис. 12.2. Связная (слева) и несвязная (справа) сети
======314
Для различных приложений могут лучше подходить разные представления сети.
Представление полными узлами обеспечивает хорошие результаты, если каждый
узел в сети связан с небольшим числом ребер. Представление списком соседних
узлов обеспечивает большую гибкость, чем представление полными узлами, а
представление нумерацией связей, хотя его сложнее модифицировать,
обеспечивает более высокую производительность.
Кроме этого, некоторые варианты представления ребер могут упростить работу
с определенными типами сетей. Эти представления используют один класс для
узлов и другой — для представления связей. Применение класса для связей
облегчает работу со свойствами связей, такими, как цена связи.
Например, ориентированная сеть с ценой связей может использовать следующее
определения для класса узла:
Public Id As Integer " Номер узла.
Public Links As Collection " Связи, ведущие к соседним узлам.
Можно использовать следующее определение класса связей:
Public ToNode As NetworkNode " Узел на другом конце связи.
Public Cost As Integer " Цена связи.
Используя эти определения, программа может найти связь с наименьшей ценой, используя следующий код:
Dim link As NetworkLink
Dim best_link As NetworkLink
Dim best_cost As Integer
best_cost = 32767
For Each link In node.Links
If link.cost < best_cost Then
Set best_link = link best_cost = link.cost
End If
Next link
Классы node и link часто расширяются для удобства работы с конкретными
алгоритмами. Например, к классу node часто добавляется флаг Marked. Если
программа обращается к узлу, то она устанавливает значение поля Marked
равным true, чтобы знать, что узел уже был проверен.
Программа, управляющая неориентированной сетью, может использовать немного
другое представление. Класс node остается тем же, что и раньше, но класс
link включает ссылку на оба узла на концах связи.
Public Node1 As NetwokNode " Один из узлов на конце связи.
Public Node2 As NetwokNode " Другой узел.
Public Cost As Integer " Цена связи.
Для неориентированной сети, предыдущее представление использовало бы два
объекта для представления каждой связи — по одному для каждого из
направлений связи. В новой версии каждая связь представлена одним объектом.
Это представление достаточно наглядно, поэтому оно используется далее в
этой главе.
=======315
Используя это представление, программа NetEdit позволяет оперировать
неориентированными сетями с ценой связей. Меню File (Файл) позволяет
загружать и сохранять сети в файлах. Команды в меню Edit (Правка) позволяют
вам вставлять и удалять узлы и связи. На рис. 12.3 показано окно программы
NetEdit.
Директория OldSrcCh12 содержит программы, которые используют представление
нумерацией связей. Эти программы немного сложнее понять, но они обычно
работают быстрее. Они не описаны в тексте, но использованные в них методы
похожи на те, которые применялись в программах, написанных для 4 версии
Visual Basic. Например, обе программы SrcCh12Paths и OldSrcCh12Paths
находят кратчайший маршрут, используя описанный ниже алгоритм установки
меток. Основное отличие между ними заключается в том, что первая программа
использует коллекции и классы, а вторая — псевдоуказатели и представление
нумерацией связей.
Оперирование узлами и связями
Корень дерева — это единственный узел, не имеющий родителя. Можно найти
любой узел в сети, начав от корня и следуя по указателям на дочерние узлы.
Таким образом, узел представляет основание дерева. Если ввести переменную,
которая будет содержать указатель на корневой узел, то впоследствии можно
будет получить доступ ко всем узлам в дереве.
Сети не всегда содержат узел, который занимает такое особое положение. В
несвязной сети может не существовать способа обойти все узлы по связям,
начав с одного узла.
Поэтому программы, работающие с сетями, обычно содержат полный список всех
узлов в сети. Программа также может хранить полный список всех связей. При
помощи этих списков можно легко выполнить какие-либо действия над всеми
узлами или связями в сети. Например, если программа хранит указатели на
узлы и связи в коллекциях Nodes и Links, она может вывести сеть на экран
при помощи следующего метода:
@Рис. 12.3. Программа NetEdit
=======316
Dim node As NetworkNode
dim link As NetworkLink
For Each link in links
" Нарисовать связь.
:
Next link
For Each node in nodes
" Нарисовать узел.
:
Next node
Программа NetEdit использует коллекции Nodes и Links для вывода сетей на экран.
Обходы сети
Обход сети выполняется аналогично обходу дерева. Можно обходить сеть,
используя либо обход в глубину, либо обход в ширину. Обход в ширину обычно
похож на прямой обход дерева, хотя для сетей можно определить также
обратный и даже симметричный обход.
Алгоритм для выполнения прямого обхода двоичного дерева, описанный в 6
главе, формулируется так:
Обратиться к узлу.
Выполнить рекурсивный прямой обход левого поддерева.
Выполнить рекурсивный прямой обход правого поддерева.
В дереве между связанными между собой узлами существует отношение родитель-
потомок. Так как алгоритм начинается с корневого узла и всегда выполняется
сверху вниз, он не обращается дважды ни к одному узлу.
В сети узлы не обязательно связаны в направлении сверху вниз. Если
попытаться применить к сети алгоритм прямого обхода, может возникнуть
бесконечный цикл.
Чтобы избежать этого, алгоритм должен помечать узел после обращения к нему,
при этом при поиске в соседних узлах, обращение происходит только к узлам,
которые еще не были помечены. После того, как алгоритм завершит работу, все
узлы в сети будут помечены (если сеть является связной). Алгоритм прямого
обхода сети формулируется так:
Пометить узел.
Обратиться к узлу.
3. Выполнить рекурсивный обход не помеченных соседних узлов.
========317
В Visual Basic можно добавить флаг Marked к классу NetworkNode.
Public Id As Long
Public Marked As Boolean
Public Links As Collection
Класс NetworkNode может включать открытую процедуру для обхода сети, начиная с этого узла. Процедура узла PreorderPrint обращается ко всем непомеченным узлам, которые доступны из данного узла. Если сеть является связной, то при таком обходе произойдет обращение ко всем узлам сети.
Public Sub PreorderPrint()
Dim link As NoworkLink
Dim node As NetworkNode
" Пометить узел.
Marked = True
" Обратиться к непомеченным узлам.
For Each link In Links
" Найти соседний узел.
If link.Node1 Is Me Then
Set node = link.Node2
Else
Set node = link.Node1
End If
" Определить, требуется ли обращение к соседнему узлу.
If Not node.Marked Then node.PreorderPrint
Next link
End Sub
Так как эта процедура не обращается ни к одному узлу дважды, то коллекция
обходимых связей не содержит циклов и образует дерево.
Если сеть является связной, то дерево будет обходить все узлы сети. Так как
это дерево охватывает все узлы сети, то оно называется остовным деревом
(spanning tree). На рис. 12.4 показана небольшая сеть с остовным деревом с
корнем в узле A, которое изображено жирными линиями.
Можно использовать похожий подход с пометкой узлов для преобразования
обхода дерева в ширину в сетевой алгоритм. Алгоритм обхода дерева
начинается с помещения корневого узла в очередь. Затем первый узел
удаляется из очереди, происходит обращение к узлу, и затем в конце очереди
помещаются его дочерние узлы. Затем этот процесс повторяется до тех пор,
пока очередь не опустеет.
======318
@Рис. 12.4. Остовное дерево
В алгоритме обхода сети нужно вначале убедиться, что узел не проверялся
раньше или он уже не находится в очереди. Для этого мы помечаем каждый
узел, который помещается в очередь. Сетевая версия этого алгоритма выглядит
так:
1. Пометить первый узел (который будет корнем остовного дерева) и добавить его в конец очереди.
2. Повторять следующие шаги до тех пор, пока очередь не опустеет: a) Удалить из очереди первый узел и обратиться к нему. b) Для каждого из непомеченных соседних узлов, пометить его и добавить в конец очереди.
Следующая процедура печатает список узлов сети в порядке обхода в ширину:
Public Sub BreadthFirstPrint(root As NetworkNode)
Dim queue As New Collection
Dim node As NetworkNode
Dim neighbor As NetworkNode
Dim link As NetworkLink
" Поместить корень в очередь. root.Marked = True queue.Add root
" Многократно помещать верхний элемент в очередь
" пока очередь не опустеет.
Do While queue.Count > 0
" Выбрать следующий узел из очереди.
Set node = queue.Item(1) queue.Remove 1
" Обратиться к узлу.
Print node.Id
" Добавить в очередь все непомеченные соседние узлы.
For Each link In node.Links
" Найти соседний узел.
If link.Node1 Is Me Then
Set neighbor = link.Node2
Else
Set neighbor = link.Node1
End If
" Проверить, нужно ли обращение к соседнему узлу.
If Not neighbor.Marked Then queue.Add neighbor
Next link
Loop
End Sub
Наименьшие остовные деревья
Если задана сеть с ценой связей, то наименьшим остовным деревом (minimal
spanning tree) называется остовное дерево, в котором суммарная цена всех
связей в дереве будет наименьшей. Наименьшее остовное дерево можно
использовать, чтобы связать все узлы в сети путем с наименьшей ценой.
Например, предположим, что требуется разработать телефонную сеть, которая
должна соединить шесть городов. Можно проложить магистральный кабель между
всеми парами городов, но это будет неоправданно дорого. Меньшую стоимость
будет иметь решение, при котором города будут соединены связями, которые
содержатся в наименьшем остовном дереве. На рис. 12.5 показаны шесть
городов, каждые два из которых соединены магистральным кабелем. Жирными
линиями нарисовано наименьшее остовное дерево.
Заметьте, что сеть может иметь несколько наименьших остовных деревьев. На
рис. 12.6 показаны два изображения сети с двумя различными наименьшими
остовными деревьями, которые нарисованы жирными линиями. Полная цена обоих
деревьев равна 32.
@Рис. 12.5. Магистральные телефонные кабели, связывающие шесть городов
========320
@Рис. 12.6. Два различных наименьших остовных дерева для одной сети
Существует простой алгоритм поиска наименьшего остовного дерева для сети.
Вначале поместим в остовное дерево любой узел. Затем найдем связь с
наименьшей ценой, которая соединяет узел в дереве с узлом, который еще не
помещен в дерево. Добавим эту связь и соответствующий узел в дерево. Затем
эта процедура повторяется до тех пор, пока все узлы не окажутся в дереве.
Этот алгоритм похож на эвристику восхождения на холм, описанную в 8 главе.
На каждом шаге оба алгоритма изменяют решение, пытаясь его максимально
улучшить. Алгоритм остовного дерева на каждом шаге выбирает связь с
наименьшей ценой, которая добавляет новый узел в дерево. В отличие от
эвристики восхождения на холм, которая не всегда находит наилучшее решение,
этот алгоритм гарантированно находит наименьшее остовное дерево.
Подобные алгоритмы, которые находят глобальный оптимум, при помощи серии
локально оптимальных приближений называются поглощающими алгоритмами(greedy
algorithms). Можно представлять себе поглощающие алгоритмы как алгоритмы
типа восхождения на холм, не являющиеся при этом эвристиками — они
гарантированно находят наилучшее возможное решение.
Алгоритм наименьшего остовного дерева использует коллекцию для хранения
списка связей, которые могут быть добавлены к остовному дереву. Вначале
алгоритм помещает в этот список связи корневого узла. Затем проводится
поиск связи с наименьшей ценой в этом списке. Чтобы максимально ускорить
поиск, программа может использовать приоритетную очередь типа описанной в 9
главе. Или наоборот, чтобы упростить реализацию, программа может
использовать для хранения списка возможных связей коллекцию.
Если узел на другом конце связи еще не находится в остовном дереве, то
программа добавляет его и соответствующую связь в дерево. Затем она
добавляет связи, выходящие из нового узла, в список возможных узлов.
Алгоритм использует флаг Used в классе link, чтобы определить, попадала ли
эта связь ранее в список возможных связей. Если да, то она не заносится в
этот список снова.
Может оказаться, что список возможных связей опустеет до того, как все узлы
будут добавлены в остовное дерево. В этом случае сеть является несвязной, и
не существует путь, который связывает корневой узел со всеми остальными
узлами сети.
=========321
Private Sub FindSpanningTree(root As SpanNode)
Dim candidates As New Collection
Dim to_node As SpanNode
Dim link As SpanLink
Dim i As Integer
Dim best_i As Integer
Dim best_cost As Integer
Dim best_to_node As SpanNode
If root Is Nothing Then Exit Sub
" Сбросить флаг Marked для всех узлов и флаги
" Used и InSpanningTree для всех связей.
ResetSpanningTree
" Начать с корня остовного дерева. root.Marked = True
Set best_to_node = root
Do
" Добавить связи последнего узла в список
" возможных связей.
For Each link In best_to_node.Links
If Not link.Used Then candidates.Add link link.Used = True
End If
Next link
" Найти самую короткую связь в списке возможных
" связей, которая ведет к узлу, которого еще нет
" в дереве. best_i = 0 best_cost = INFINITY i = 1
Do While i 0
" Найти ближайший к корню узел-кандидат. best_dist = INFINITY
For i = 1 To candidates.Count new_dist = candidates(i).Dist
If new_dist < best_dist Then best_i = i best_dist = new_dist
End If
Next i
" Добавить узел к дерева кратчайшего маршрута.
Set node = candidates(best_i) candidates.Remove best_i node.NodeStatus = WAS_IN_LIST
" Проверить соседние узлы.
For Each link In node.Links
If node Is link.Node1 Then
Set to_node = link.Node2
Else
Set to_node = link.Node1
End If
If to_node.NodeStatus = NOT_IN_LIST Then
" Узел раньше не был в списке возможных
" узлов. Добавить его в список. candidates.Add to_node to_node.NodeStatus = NOW_IN_LIST to_node.Dist = best_dist + link.Cost
Set to_node.InLink = link
ElseIf to_node.NodeStatus = NOW_IN_LIST Then
" Узел находится в списке возможных узлов.
" Обновить значения его полей Dist и inlink,
" если это необходимо. new_dist = best_dist + link.Cost
If new_dist < to_node.Dist Then to_node.Dist = new_dist
Set to_node.InLink = link
End If
End If
Next link
Loop
GotPathTree = True
" Пометить входящие узлы, чтобы их было проще вывести на экран.
For Each node In Nodes
If Not (node.InLink Is Nothing) Then _ node.InLink.InPathTree = True
Next node
" Перерисовать сеть.
DrawNetwork
End Sub
Важно, чтобы алгоритм обновлял поля InLink и Dist только для узлов, в
которых поле NodeStatus равно NOW_IN_LIST. Для большинства сетей нельзя
получить более короткий путь, добавляя узлы, которые не находятся в списке
возможных узлов. Тем не менее, если сеть содержит цикл, полная длина
которого отрицательна, алгоритм может обнаружить, что можно уменьшить
расстояние до некоторых узлов, которые уже находятся в дереве кратчайшего
маршрута, при этом две ветви дерева кратчайшего маршрута окажутся
связанными друг с другом, так что оно перестанет быть деревом.
На рис. 12.10 показана сеть с циклом отрицательной цены и «дерево»
кратчайшего маршрута, которое получилось бы, если бы алгоритм обновлял цену
узлов, которые уже находятся в дереве.
=======329
@Рис. 12.10. Неправильное «дерево» кратчайшего маршрута для сети с циклом отрицательной цены
Программа PathS использует этот алгоритм установки меток для вычисления кратчайшего маршрута. Она аналогична программам NetEdit и Span. Если вы не вставляете или не удаляете узел или связь, то можно выбрать узел при помощи мыши и программа при этом найдет и выведет на экран дерево кратчайшего маршрута с корнем в этом узле. На рис. 12.11 показано окно программы PathS с деревом кратчайшего маршрута с корнем в узле 3.
@Рис. 12.11. Дерево кратчайшего маршрута с корнем в узле 3
=======330
Варианты метода установки меток
Узкое место этого алгоритма заключается в поиске узла с наименьшим
значением поля Dist в списке возможных узлов. Некоторые варианты этого
алгоритма используют другие структуры данных для хранения списка возможных
узлов. Например, можно было бы использовать упорядоченный связный список.
При использовании этого метода потребуется только один шаг для того, чтобы
найти следующий узел, который будет добавлен к дереву кратчайшего маршрута.
Этот список будет всегда упорядоченным, поэтому узел на вершине списка
всегда будет искомым узлом.
Это облегчит поиск нужного узла в списке, но усложнит добавление узла в
него. Вместо того чтобы просто помещать узел в начало списка, его придется
поместить в нужную позицию.
Иногда также требуется перемещать узлы в списке. Если в результате
добавления узла в дерево кратчайшего маршрута уменьшилось кратчайшее
расстояние до другого узла, который уже был в списке, то нужно переместить
этот элемент ближе к вершине списка.
Предыдущий алгоритм и этот его новый вариант представляют собой два крайних
случая управления списком возможных узлов. Первый алгоритм совсем не
упорядочивает список и тратит достаточно много времени на поиск узлов в
сети. Второй тратит много времени на поддержание упорядоченности списка, но
может очень быстро выбирать из него узлы. Другие варианты используют
промежуточные стратегии.
Например, можно использовать для хранения списка возможных узлов
приоритетную очередь на основе пирамид, тогда можно будет просто выбрать
следующий узел с вершины пирамиды. Вставка нового узла в пирамиду и ее
переупорядочение будет выполняться быстрее, чем аналогичные операции для
упорядоченного связного списка. Другие стратегии используют сложные схемы
организации блоков для того, чтобы упростить поиск возможных узлов.
Некоторые из этих вариантов достаточно сложны. Из-за этой их сложности эти
алгоритмы для небольших сетей часто выполняются медленнее, чем более
простые алгоритмы. Тем не менее, для очень больших сетей или сетей, в
которых каждый узел имеет очень большое число связей, выигрыш от применения
этих алгоритмов может стоить дополнительного усложнения.
Коррекция меток
Как и алгоритм установки меток, этот алгоритм начинает с обнуления значения
поля Dist корневого узла и помещает корневой узел в список возможных узлов.
При этом значения полей Dist остальных узлов устанавливаются равными
бесконечности. Затем для вставки в дерево кратчайшего маршрута выбирается
первый узел в списке возможных узлов.
После этого алгоритм проверяет узлы, соседние с выбранным, выясняя, будет
ли расстояние от корня до выбранного узла плюс цена связи меньше, чем
текущее значение поля Dist соседнего узла. Если это так, то поля Dist и
InLink соседнего узла обновляются так, чтобы кратчайший маршрут к соседнему
узлу проходил через выбранный узел. Если соседний узел при этом не
находился в списке возможных узлов, то алгоритм также добавляет его к
списку. Заметьте, что алгоритм не проверяет, попадал ли этот узел в список
раньше. Если путь от корня до соседнего узла становится короче, узел всегда
добавляется в список возможных узлов.
Алгоритм продолжает удалять узлы из списка возможных узлов, проверяя
соседние с ними узлы и добавляя соседние узлы в список до тех пор, пока
список не опустеет.
Если внимательно сравнить алгоритмы установки меток и коррекции меток, то
видно, что они похожи. Единственное отличие заключается в том, как каждый
из них выбирает элементы из списка возможных узлов для вставки в дерево
кратчайшего маршрута.
=====331
Алгоритм установки меток всегда выбирает связь, которая гарантированно
находится в дереве кратчайшего маршрута. При этом после того, как узел
удаляется из списка возможных узлов, он навсегда помещается в дерево и
больше не попадает в список возможных узлов.
Алгоритм корректировки всегда выбирает первый узел из списка возможных
узлов, который не всегда может быть наилучшим выбором. Значения полей Dist
и InLink этого узла могут быть не наилучшими из возможных. В этом случае
алгоритм, в конце концов, найдет в списке узел, через который проходит
более короткий путь к выбранному узлу. Тогда алгоритм обновляет поля Dist и
InLink и снова помещает обновленный узел в список возможных узлов.
Алгоритм может использовать новый путь для создания других путей, которые
он мог пропустить раньше. Помещая обновленный узел снова в список
обновленных узлов, алгоритм гарантирует, что этот узел будет проверен снова
и будут найдены все такие пути.
Private Sub FindPathTree(root As PathCNode)
Dim candidates As New Collection
Dim node_dist As Integer
Dim new_dist As Integer
Dim node As PathCNode
Dim to_node As PathCNode
Dim link As PathCLink
If root Is Nothing Then Exit Sub
" Сбросить поля Marked и NodeStatus для всех узлов,
" и флаги Used и InPathTree для всех связей.
ResetPathTree
" Начать с корня дерева кратчайшего маршрута. root.Dist = 0
Set root.InLink = Nothing root.NodeStatus = NOW_IN_LIST candidates.Add root
Do While candidates.Count > 0
" Добавить узел в дерево кратчайшего маршрута.
Set node = candidates(1) candidates.Remove 1 node_dist = node.Dist node.NodeStatus = NOT_IN_LIST
" Проверить соседние узлы.
For Each link In node.Links
If node Is link.Node1 Then
Set to_node = link.Node2
Else
Set to_node = link.Node1
End If
" Проверить, существует ли более короткий
" путь через этот узел. new_dist = node_dist + link.Cost
If to_node.Dist > new_dist Then
" Путь лучше. Обновить значения Dist и InLink.
Set to_node.InLink = link to_node.Dist = new_dist
" Добавить узел в список возможных узлов,
" если его там еще нет.
If to_node.NodeStatus = NOT_IN_LIST Then candidates.Add to_node to_node.NodeStatus = NOW_IN_LIST
End If
End If
Next link
Loop
" Пометить входящие связи, чтобы их было проще вывести.
For Each node In Nodes
If Not (node.InLink Is Nothing) Then _ node.InLink.InPathTree = True
Next node
" Перерисовать сеть.
DrawNetwork
End Sub
В отличие от алгоритма установки меток, этот алгоритм не может работать с
сетями, которые содержат циклы с отрицательной ценой. Если встречается
такой цикл, то алгоритм бесконечно перемещается по связям внутри него. При
каждом обходе цикла расстояние до входящих в него узлов уменьшается, при
этом алгоритм снова помещает узлы в список возможных узлов, и снова может
проверять их в дальнейшем. При следующей проверке этих узлов, расстояние до
них также уменьшится, и так далее. Этот процесс будет продолжаться до тех
пор, пока расстояние до этих узлов не достигнет нижнего граничного значения
-32.768, если длина пути задана целым числом. Если известно, что в сети
имеются циклы с отрицательной ценой, то проще всего просто использовать для
работы с ней метод установки, а не коррекции меток.
Программа PathC использует этот алгоритм коррекции меток для вычисления
кратчайшего маршрута. Она аналогична программе PathS, но использует метод
коррекции, а не установки меток.
=======333
Варианты метода коррекции меток
Алгоритм коррекции меток позволяет очень быстро выбрать узел из списка
возможных узлов. Он также может вставить узел в список всего за один или
два шага. Недостаток этого алгоритма заключается в том, что когда он
выбирает узел из списка возможных узлов, он может сделать не слишком
хороший выбор. Если алгоритм выбирает узел до того, как его поля Dist и
InLink получат свои конечный значения, он должен позднее скорректировать
значения этих полей и снова поместить узел в список возможных узлов. Чем
чаще алгоритм помещает узлы назад в список возможных узлов, тем больше
времени это занимает.
Варианты этого алгоритма пытаются повысить качество выбора узлов без
большого усложнения алгоритма. Один из методов, который неплохо работает на
практике, состоит в том, чтобы добавлять узлы одновременно в начало и конец
списка возможных узлов. Если узел раньше не попадал в список возможных
узлов, алгоритм, как обычно, добавляет его в конец списка. Если узел уже
был раньше в списке возможных узлов, но сейчас его там нет, алгоритм
вставляет его в начало списка. При этом повторное обращение к узлу
выполняется практически сразу, возможно при следующем же обращении к
списку.
Идея, заключенная в таком подходе, состоит в том, чтобы если алгоритм
совершает ошибку, она исправлялась как можно быстрее. Если ошибка не будет
исправлена в течение достаточно долгого времени, алгоритм может
использовать неправильную информацию для построения длинных ложных путей,
которые затем придется исправлять. Благодаря быстрому исправлению ошибок,
алгоритм может уменьшить число неверных путей, которые придется
перестроить. В наилучшем случае, если все соседние узлы все еще находятся в
списке возможных узлов, повторная проверка этого узла до проверки соседей
предотвратит построение неверных путей.
Другие задачи поиска кратчайшего маршрута
Описанные выше алгоритмы поиска кратчайшего маршрута вычисляли все
кратчайшие пути из корневого узла до всех остальных узлов в сети.
Существует множество других типов задачи нахождения кратчайшего маршрута. В
этом разделе обсуждаются три из них: двухточечный кратчайший маршрут (point-
to-point shortest path), кратчайший маршрут для всех пар(all pairs shortest
path) и кратчайший маршрут со штрафами за повороты.
Двухточечный кратчайший маршрут
В некоторых приложениях может понадобиться найти кратчайший маршрут между
двумя точками, при этом остальные пути в полном дереве кратчайшего маршрута
не важны. Простой способ решить эту задачу — вычислить полное дерево
кратчайшего маршрута при помощи метода установки или коррекции меток, а
затем выбрать из дерева кратчайший путь между двумя точками.
Другой способ заключается в использовании метода установки меток, который
останавливался бы, когда будет найден путь к конечному узлу. Алгоритм
установки меток добавляет к дереву кратчайшего маршрута только те пути,
которые обязательно должны в нем находиться, следовательно, в тот момент,
когда алгоритм добавит конечный узел в дерево, будет найден искомый
кратчайший маршрут. В алгоритме, который обсуждался раньше, это происходит,
когда алгоритм удаляет конечный узел из списка возможных узлов.
=======334
Единственное изменение требуется внести в часть алгоритма установки меток, которая выполняется сразу же после того, как алгоритм находит в списке возможных узлов узел с наименьшим значением Dist. Перед удалением узла из списка возможных узлов, алгоритм должен проверить, не является ли этот узел искомым. Если это так, то дерево кратчайшего маршрута уже содержит кратчайший маршрут между начальным и конечным узлами, и алгоритм может закончить работу.
" Найти ближайший к корню узел в списке возможных узлов.
:
" Проверить, является ли этот узел искомым.
If node = destination Then Exit Do
" Добавить этот узел в дерево кратчайшего маршрута.
:
На практике, если две точки в сети расположены далеко друг от друга, то
этот алгоритм обычно будет выполняться дольше, чем займет вычисление
полного дерева кратчайшего маршрута. Алгоритм выполняется медленнее из-за
того, что в каждом цикле выполнения алгоритма проверяется, достигнут ли
искомый узел. С другой стороны, если узлы расположены рядом, то выполнение
этого алгоритма может потребовать намного меньше времени, чем построение
полного дерева кратчайшего маршрута.
Для некоторых сетей, таких как сеть улиц, можно оценить, насколько близко
расположены две точки, и затем решить, какую версию алгоритма выбрать. Если
сеть содержит все улицы южной Калифорнии, и две точки расположены на
расстоянии 10 миль, следует использовать версию, которая останавливается
после того, как найдет конечный узел. Если же точки удалены друг от друга
на 100 миль, возможно, меньше времени займет вычисление полного дерева
кратчайшего маршрута.
Вычисление кратчайшего маршрута для всех пар
В некоторых приложениях может потребоваться быстро найти кратчайший маршрут
между всеми парами узлов в сети. Если нужно вычислить большую часть из N2
возможных путей, может быть быстрее вычислить все возможные пути вместо
того, чтобы находить только те, которые нужны.
Можно записать кратчайшие маршруты, используя два двумерных массива, Dist и
InLinks. В ячейке Dist(I, J) находится кратчайший маршрут из узла I в узел
J, а в ячейке InLinks(I, J) — связь, которая ведет к узлу J в кратчайшем
пути из узла I в узел J. Эти значения аналогичны значениям Dist и InLink в
классе узла в предыдущем алгоритме.
Один из способов найти все кратчайшие маршруты заключается в том, чтобы
построить деревья кратчайшего маршрута с корнем в каждом из узлов сети при
помощи одного из предыдущих алгоритмов, и затем сохранить результаты в
массивах Dists и InLinks.
========335
Другой метод вычисления всех кратчайших маршрутов последовательно строит
пути, используя все больше и больше узлов. Вначале алгоритм находит все
кратчайшие маршруты, которые используют только первый узел и узлы на концах
пути. Другими словами, для узлов J и K алгоритм находит кратчайший маршрут
между этими узлами, который использует только узел с номером 1 и узлы J и
K, если такой путь существует
Затем алгоритм находит все кратчайшие маршруты, которые используют только
два первых узла. Затем он строит пути, используя первые три узла, первые
четыре узла, и так далее до тех пор, пока не будут построены все кратчайшие
маршруты, используя все узлы. В этот момент, поскольку кратчайшие маршруты
могут использовать любой узел, алгоритм найдет все кратчайшие маршруты в
сети.
Заметьте, что кратчайший маршрут между узлами J и K, использующий только
первые I узлов, включает узел I, только если Dist(J, K) > Dist(J, I) +
Dist(I, K). Иначе кратчайшим маршрутом будет предыдущий кратчайший маршрут,
который использовал только первые I - 1 узлов. Это означает, что когда
алгоритм рассматривает узел I, требуется только проверить выполнение
условия Dist(J, K) > Dist(J, I) + Dist(I, K). Если это условие выполняется,
алгоритм обновляет кратчайший маршрут из узла J в узел K. Иначе старый
кратчайший маршрут между этими двумя узлами остался бы таковым.
Штрафы за повороты
В некоторых сетях, в особенности сетях улиц, бывает полезно добавить штраф и запреты на повороты (turn penalties) В сети улиц автомобиль должен замедлить движение перед тем, как выполнить поворот. Поворот налево может занимать больше времени, чем поворот направо или движение прямо. Некоторые повороты могут быть запрещены или невозможны из-за наличия разделительной полосы. Эти аспекты можно учесть, вводя в сеть штрафы за повороты.
Небольшое число штрафов за повороты
Часто важны только некоторые штрафы за повороты. Может понадобиться
предотвратить выполнение запрещенных или невозможных поворотов и присвоить
штрафы за повороты лишь на нескольких ключевых перекрестках, не определяя
штрафы для всех перекрестков в сети. В этом случае можно разбить каждый
узел, для которого заданы штрафы, на несколько узлов, которые будут неявно
учитывать штрафы.
Предположим, что требуется добавить один штраф за поворот на перекрестке
налево и другой штраф за поворот направо. На рис. 12.12 показан
перекресток, на котором требуется применить эти штрафы. Число рядом с
каждой связью соответствует ее цене. Требуется применить штрафы за вход в
узел A по связи L1, и затем выход из него по связям L2 или L3.
Для применения штрафов к узлу A, разобьем этот узел на два узла, по одному
для каждой из покидающих его связей. В данном примере, из узла A выходят
две связи, поэтому узел A разбивается на два узла A1 и A2, и связи,
выходящие из узла A, заменяются соответствующими связями, выходящими из
полученных узлов. Можно представить, что каждый из двух образовавшихся
узлов соответствует входу в узел A и повороту в сторону соответствующей
связи.
======336
@Рис. 12.12. Перекресток
Затем связь L1, входящая в узел A, заменяется на две связи, входящие в
каждый из двух узлов A1 и A2. Цена этих связей равна цене исходной связи L1
плюс штрафу за поворот в соответствующем направлении. На рис. 12.13 показан
перекресток, на котором введены штрафы за поворот. На этом рисунке штраф за
поворот налево из узла A равен 5, а за поворот направо —2.
Помещая информацию о штрафах непосредственно в конфигурацию сети, мы
избегаем необходимости модифицировать алгоритмы поиска кратчайшего
маршрута. Эти алгоритмы будут находить правильные кратчайшие маршруты с
учетом штрафов за повороты.
При этом придется все же слегка изменить программы, чтобы учесть разбиение
узлов на несколько частей. Предположим, что требуется найти кратчайший
маршрут между узлами I и J, но узел I оказался разбит на несколько узлов.
Полагая, что можно покинуть узел I по любой связи, можно создать ложный
узел и использовать его в качестве корня дерева кратчайшего маршрута.
Соединим этот узел связями с нулевой ценой с каждым из узлов, получившихся
после разбиения узла I. Тогда, если построить дерево кратчайшего маршрута с
корнем в ложном узле, то при этом будут найдены все кратчайшие маршруты,
содержащие любой из этих узлов. На рис. 12.14 показан перекресток с рис.
12.13, связанный с ложным корневым узлом.
@Рис. 12.13. Перекресток со штрафами за повороты
=======337
@Рис. 12.14. Перекресток, связанный с ложным корнем
Обрабатывать случай поиска пути к узлу, который был разбит на несколько
узлов, проще. Если требуется найти кратчайший маршрут между узлами I и J, и
узел J был разбит на несколько узлов, то вначале, как обычно, нужно найти
дерево кратчайшего маршрута с корнем в узле I. Затем проверяются все узлы,
на которые был разбит узел J и находится ближайший из них к корню дерева.
Путь к этому узлу и есть кратчайший маршрут к исходному узлу J.
Большое число штрафов за повороты
Предыдущий метод будет не слишком эффективным, если вы хотите ввести штрафы
за повороты для большинства узлов в сети. Лучше будет создать совершенно
новую сеть, которая будет включать информацию о штрафах.
. Для каждой связи между узлами A и B в исходной сети в новой сети создается узел AB;
. Если в исходной сети соответствующие связи были соединены, то полученные узлы также соединяются между собой. Например, предположим, что в исходной сети одна связь соединяла узлы A и B, а другая — узлы B и C.
Тогда в новой сети нужно создать связь, соединяющую узел AB с узлом BC;
. Цена новой связи складывается из цены второй связи в исходной сети и штрафа за поворот. В этом примере цена связи между узлом AB и узлом BC будет равна цене связи, соединяющей узлы B и C в исходной сети плюс штрафу за поворот при движении из узла A в узел B и затем в узел C.
На рис. 12.15 изображена небольшая сеть и соответствующая новая сеть,
представляющая штрафы за повороты. Штраф за поворот налево равен 3, за
поворот направо — 2, а за «поворот» прямо — нулю. Например, так как поворот
из узла B в узел E — это левый поворот в исходной сети, штраф для связи
между узлами BE и EF в новой сети равен 3. Цена связи, соединяющей узлы E и
F в исходной сети, равна 3, поэтому полная цена новой связи равна 3 + 3 =
6.
=======338
@Рис. 12.15. Сеть и соответствующая ей сеть со штрафами за повороты
Предположим теперь, что требуется найти для исходной сети дерево
кратчайшего маршрута с корнем в узле D. Чтобы сделать это, создадим в новой
сети ложный корневой узел, затем построим связи, соединяющие этот узел со
всеми связями, которые покидают узел D в исходной сети. Присвоим этим
связям ту же цену, которую имеют соответствующие связи в исходной сети. На
рис. 12.16 показана новая сеть с рис. 12.15 с ложным корневым узлом,
соответствующим узлу D. Дерево кратчайшего маршрута в этой сети нарисовано
жирной линией.
Чтобы найти кратчайший маршрут из узла D в узел C, необходимо проверить все
узлы в новой сети, которые соответствуют связям, заканчивающимся в узле C.
В этом примере это узлы BC и FC. Ближайший к ложному корню узел
соответствует кратчайшему маршруту к узлу C в исходной сети. Узлы в
кратчайшем маршруте в новой сети соответствуют связям в кратчайшем маршруте
в исходной сети.
@Рис. 12.16. Дерево кратчайшего маршрута в сети со штрафами за повороты
========339
На рис. 12.16 кратчайший маршрут начинается с ложного корня, идет в узел
DE, затем узлы EF и FC и имеет полную цену 16. Этот путь соответствует пути
D, E, F, C в исходной сети. Прибавив один штраф за левый поворот E, F, C,
получим, что цена этого пути в исходной сети также равна 16.
Заметьте, что вы не нашли бы этот путь, если бы построили дерево
кратчайшего маршрута в исходной сети. Без учета штрафов за повороты,
кратчайшим маршрутом из узла D в узел C был бы путь D, E, B, C с полной
ценой 12. С учетом штрафов цена этого пути равна 17.
Применения метода поиска кратчайшего маршрута
Вычисления кратчайшего маршрута используются во многих приложениях.
Очевидным примером является поиск кратчайшего маршрута между двумя точками
в уличной сети. Многие другие приложения используют метод поиска
кратчайшего маршрута менее очевидными способами. Следующие разделы
описывают некоторые из этих приложений.
Разбиение на районы
Предположим, что имеется карта города, на которую нанесены все пожарные
депо. Может потребоваться определить для каждой точки города ближайшее к
ней депо. На первый взгляд это кажется трудной задачей. Можно попытаться
рассчитать дерево кратчайшего маршрута с корнем в каждом узле сети, чтобы
найти, какое депо расположено ближе всего к каждому из узлов. Или можно
построить дерево кратчайшего маршрута с корнем в каждом из пожарных депо и
записать расстояние от каждого из узлов до каждого из депо. Но существует
намного более быстрый метод.
Создадим ложный корневой узел и соединим его с каждым из пожарных депо
связями с нулевой ценой. Затем найдем дерево кратчайшего маршрута с корнем
в этом ложном узле. Для каждой точки в сети кратчайший маршрут из ложного
корневого узла к этой точке пройдет через ближайшее к этой точке пожарное
депо. Чтобы найти ближайшее к точке пожарное депо, нужно просто
проследовать по кратчайшему маршруту от этой точки к корню, пока на пути не
встретится одно из депо. Построив всего одно дерево кратчайшего маршрута,
можно найти ближайшие пожарные депо для каждой точки в сети.
Программа District использует этот алгоритм для разбиения сети на районы.
Так же, как и программа PathC и другие программы, описанные в этой главе,
она позволяет загружать, редактировать и сохранять на диске ориентированные
сети с ценой связей. Если вы не добавляете и не удаляете узлы или связи, вы
можете выбрать депо для разделения на районы. Добавьте узлы к списку
пожарных депо щелчком левой кнопки мыши, затем щелкните правой кнопкой в
любом месте формы, и программа разобьет сеть на районы.
На рис. 12.17 показано окно программы, на котором изображена сеть с тремя
депо. Депо в узлах 3, 18 и 20 обведены жирными кружочками. Разбивающие сеть
на районы деревья кратчайшего маршрута изображены жирными линиями.
=====340
@Рис. 12.17. Программа District
Составление плана работ с использованием метода критического пути
Во многих задачах, в том числе в больших программных проектах, определенные
действия должны быть выполнены раньше других. Например, при строительстве
дома до установки фундамента нужно вырыть котлован, фундамент должен
застыть до того, как начнется возведение стен, каркас дома должен быть
собран прежде, чем можно будет выполнять проводку электричества,
водопровода и кровельные работы и так далее.
Некоторые из этих задач могут выполняться одновременно, другие должны
выполняться последовательно. Например, можно одновременно проводить
электричество и прокладывать водопровод.
Критическим путем (critical path) называется одна из самых длинных
последовательностей задач, которая должна быть выполнена для завершения
проекта. Важность задач, лежащих на критическом пути, определяется тем, что
сдвиг сроков выполнения этих задач приведет к изменению времени завершения
проекта в целом. Если заложить фундамент на неделю позже, то и здание будет
завершено на неделю позже. Для определения заданий, которые находятся на
критическом пути, можно использовать модифицированный алгоритм поиска
кратчайшего маршрута.
Вначале создадим сеть, которая представляет временные соотношения между
задачами проекта. Пусть каждой задаче соответствует узел. Нарисуем связь
между задачей I и задачей J, если задача I должна быть выполнена до начала
задачи J, и присвоим этой связи цену, равную времени выполнения задачи I.
После этого создадим два ложных узла, один из которых будет соответствовать
началу проекта, а другой — его завершению. Соединим начальный узел связями
с нулевой ценой со всеми узлами в проекте, в которые не входит ни одна
другая связь. Эти узлы соответствуют задачам, выполнение которых можно
начинать немедленно, не ожидая завершения других задач.
Затем создадим ложные связи нулевой длины, соединяющие все узлы, из которых
не выходит не одной связи, с конечным узлом. Эти узлы представляют задачи,
которые не тормозят выполнение других задач. После того, как все эти задачи
будут выполнены, проект будет завершен.
Найдя самый длинный маршрут между начальным и конечным узлами сети, мы
получим критический путь проекта. Входящие в него задачи будут критичными
для выполнения проекта.
========341
@Таблица 12.1. Этапы сборки дождевальной установки
Рассмотрим, например, упрощенный проект сборки дождевальной установки,
состоящий из пяти задач. В табл. 12.1 приведены задачи и временные
соотношения между ними. Сеть для этого проекта показана на рис. 12.18.
В этом простом примере легко увидеть, что самый длинный маршрут в сети
выполняет следующую последовательность задач: выкопать канавы, смонтировать
трубы, закопать их. Это критические задачи, и если в выполнении какой-либо
из них наступит задержка, выполнение проекта также задержится.
Длина этого критического пути равна ожидаемому времени завершения проекта.
В данном случае, если все задачи будут выполнены вовремя, выполнение
проекта займет пять дней. При этом предполагается также, что если это
возможно, несколько задач будут выполняться одновременно. Например, один
человек может копать канавы, пока другой будет закупать трубы.
В более значительном проекте, таком как строительство небоскреба или съемка
фильма, могут содержаться тысячи задач, и критические пути при этом могут
быть совсем не очевидны.
Планирование коллективной работы
Предположим, что требуется набрать несколько сотрудников для ответов на телефонные звонки, при этом каждый из них будет занят не весь день. При этом нужно, чтобы суммарная зарплата была наименьшей, и нанятый коллектив сотрудников отвечал на звонки с 9 утра до 5 вечера. В табл. 12.2 приведены рабочие часы сотрудников, и их почасовая оплата.
@Рис. 12.18. Сеть задач сборки дождевальной установки
======342
@Таблица 12.2. Рабочие часы сотрудников и их почасовая оплата
Для построения соответствующей сети, создадим один узел для каждого
рабочего часа. Соединим эти узлы связями, каждая из которых соответствует
рабочим часам какого-либо сотрудника. Если сотрудник может работать с 9 до
11, нарисуем связь между узлом 9:00 и узлом 11:00, и присвоим этой связи
цену, равную зарплате, получаемой данным сотрудником за соответствующее
время. Если сотрудник получает 6,5 долларов в час, и отрезок времени
составляет два часа, то цена связи равна 13 долларам. На рис. 12.19
показана сеть, соответствующая данным из табл. 12.2.
Кратчайший маршрут из первого узла в последний позволяет набрать коллектив
сотрудников с наименьшей суммарной зарплатой. Каждая связь в пути
соответствует работе сотрудника в определенный промежуток времени. В данном
случае кратчайший маршрут из узла 9:00 в узел 5:00 проходит через узлы
11:00, 12:00 и 3:00. Этому соответствует следующий график работы: сотрудник
A работает с 9:00 до 11:00, сотрудник D работает с 11:00 до 12:00, затем
сотрудник A снова работает с 12:00 до 3:00 и сотрудник E работает с 3:00 до
5:00. Полная зарплата всех сотрудников при таком графике составляет 52,15
доллара.
@Рис. 12.19. Сеть графика работы коллектива
======343
Максимальный поток
Во многих сетях связи имеют кроме цены, еще и пропускную способность
(capacity). Через каждый узел сети может проходить поток (flow), который не
превышает ее пропускной способности. Например, по улицам может проехать
только определенной число машин. Сеть с заданными пропускными способностями
ее связей называется нагруженной сетью (capacitated network). Если задана
нагруженная сеть, задача о максимальном потоке заключается в определении
наибольшего возможного потока через сеть из заданного источника (source) в
заданный сток (sink).
На рис. 12.20 показана небольшая нагруженная сеть. Числа рядом со связями в
этой сети — это не цена связи, а ее пропускная способность. В этом примере
максимальный поток, равный 4, получается, если две единицы потока
направляются по пути A, B, E,F и еще две — по пути A, C, D, F.
Описанный здесь алгоритм начинается с того, что поток во всех связях равен
нулю и затем алгоритм постепенно увеличивает поток, пытаясь улучшить
найденное решение. Алгоритм завершает работу, если нельзя улучшить
имеющееся решение.
Для поиска путей способов увеличения полного потока, алгоритм проверяет
остаточную пропускную способность (residual capacity) связей. Остаточная
пропускная способность связи между узлами I и J равна максимальному
дополнительному потоку, который можно направить из узла I в узел J,
используя связь между I и J и связь между J и I. Этот суммарный поток может
включать дополнительный поток по связи I-J, если в этой связи есть резерв
пропускной способности, или исключать часть потока из связи J-I, если по
этой связи идет поток.
Например, предположим, что в сети, соединяющей узлы A и C на рис. 12.20,
существует поток, равный 2. Так как пропускная способность этой связи равна
3, то к этой связи можно добавить единицу потока, поэтому остаточная
пропускная способность этой связи равна 1. Хотя сеть, показанная на рис.
12.20 не имеет связи C-A, для этой связи существует остаточная пропускная
способность. В данном примере, так как по связи A-C идет поток, равный 2,
то можно удалить до двух единиц этого потока. При этом суммарный поток из
узла C в узел A увеличился бы на 2, поэтому остаточная пропускная
способность связи C-A равна 2.
@Рис. 12.20. Нагруженная сеть
========344
@Рис. 12.21. Потоки в сети
Сеть, состоящая из всех связей с положительной остаточной пропускной
способностью, называется остаточной сетью (residual network). На рис. 12.21
показана сеть с рис. 12.20, каждой связи в которой присвоен поток. Для
каждой связи, первое число равно потоку через связь, а второе — ее
пропускной способности. Надпись «1/2», например, означает, что поток через
связь равен 1, и ее пропускная способность равна 2. Связи, поток через
которые больше нуля, нарисованы жирными линиями.
На рис. 12.22 показана остаточная сеть, соответствующая потокам на рис.
12.21. Нарисованы только связи, которые действительно могут иметь
остаточную пропускную способность. Например, между узлами A и D не
нарисовано ни одной связи. Исходная сеть не содержит связи A-D или D-A,
поэтому эти связи всегда будут иметь нулевую остаточную пропускную
способность.
Одно из свойств остаточных сетей состоит в том, что любой путь,
использующий связи с остаточной пропускной способностью больше нуля,
который связывает источник со стоком, дает способ увеличения потока в сети.
Так как этот путь дает способ увеличения или расширения потока в сети, он
называется расширяющим путем (augmenting path). На рис. 12.23 показана
остаточная сеть с рис. 12.22 с расширяющим путем, нарисованным жирной
линией.
Чтобы обновить решение, используя расширяющий путь, найдем наименьшую
остаточную пропускную способность в пути. Затем скорректируем потоки в пути
в соответствии с этим значением. Например, на рис. 12.23 наименьшая
остаточная пропускная способность сетей в расширяющем пути равна 2. Чтобы
обновить потоки в сети, к любой связи I-J на пути добавляется поток 2, а из
всех обратных им связей J-I вычитается поток 2.
@Рис. 12.22. Остаточная сеть
========345
@Рис. 12.23. Расширяющий путь через остаточную сеть
Вместо того, чтобы корректировать потоки, и затем перестраивать остаточную
сеть, проще просто скорректировать остаточную сеть. Затем после завершения
работы алгоритма можно использовать результат для вычисления потоков для
связей в исходной сети.
Чтобы скорректировать остаточную сеть в этом примере, проследуем по
расширяющему пути. Вычтем 2 из остаточной пропускной способности всех
связей I-J вдоль пути, и добавим 2 к остаточной пропускной способности
соответствующей связи J-I. На рис. 12.24 показана скорректированная
остаточная сеть для этого примера.
Если больше нельзя найти ни одного расширяющего пути, то можно использовать
остаточную сеть для вычисления потоков в исходной сети. Для каждой связи
между узлами I и J, если остаточный поток между узлами I и J меньше, чем
пропускная способность связи, то поток должен равняться пропускной
способности минус остаточный поток. В противном случае поток должен быть
равен нулю.
Например, на рис. 12.24 остаточный поток из узла A в узел C равен 1 и
пропускная способность связи A-C равна 3. Так как 1 меньше 3, то поток
через узел будет равен 3 - 1 = 2. На рис. 12.25 показаны потоки в сети,
соответствующие остаточной сети на рис. 12.24.
@Рис. 12.24. Скорректированная остаточная сеть
========346
@Рис. 12.25. Максимальные потоки
Полученный алгоритм еще не содержит метода для поиска расширяющих путей в
остаточной сети. Один из возможных методов аналогичен методу коррекции
меток для алгоритма кратчайшего маршрута. Вначале поместим узел-источник в
список возможных узлов. Затем, если список возможных узлов не пуст, будем
удалять из него по одному узлу. Проверим все соседние узлы, соединенные с
выбранным узлом по связи, остаточная пропускная способность которой больше
нуля. Если соседний узел еще не был помещен в список возможных узлов,
добавить его в список. Продолжить этот процесс до тех пор, пока список
возможных узлов не опустеет.
Этот метод имеет два отличия от метода поиска кратчайшего маршрута
коррекцией меток. Во-первых, этот метод не прослеживает связи с нулевой
остаточной пропускной способностью. Алгоритм же кратчайшего маршрута
проверяет все пути, независимо от их цены.
Во-вторых, этот алгоритм проверяет все узлы не больше одного раза. Алгоритм
поиска кратчайшего маршрута коррекцией меток, будет обновлять узлы и
помещать их снова в список возможных узлов, если он позднее найдет более
короткий путь от корня к этому узлу. При поиске расширяющего пути нет
необходимости проверять его длину, поэтому не нужно обновлять пути и
помещать узлы назад в список возможных узлов.
Следующий код демонстрирует, как можно вычислять максимальные потоки в
программе на Visual Basic. Этот код предназначен для работы с
неориентированными сетями, похожими на те, которые использовались в других
программах примеров, описанных в этой главе. После завершения работы
алгоритма он присваивает связи цену, равную потоку через нее, взятому со
знаком минус, если поток течет в обратном направлении. Другими словами,
если сеть содержит объект, представляющий связь I-J, а алгоритм определяет,
что поток должен течь в направлении связи J-I, то потоку через связь I-J
присваивается значение, равное потоку, который должен был бы течь через
связь J-I, взятому со знаком минус. Это позволяет программе определять
направление потока, используя существующую структуру узлов.
=======347
Private Sub FindMaxFlows()
Dim candidates As Collection
Dim Residual() As Integer
Dim num_nodes As Integer
Dim id1 As Integer
Dim id2 As Integer
Dim node As FlowNode
Dim to_node As FlowNode
Dim from_node As FlowNode
Dim link As FlowLink
Dim min_residual As Integer
If SourceNode Is Nothing Or SinkNode Is Nothing _
Then Exit Sub
" Задать размер массива остаточной пропускной способности. num_nodes = Nodes.Count
ReDim Residual(1 To num_nodes, 1 To num_nodes)
" Первоначально значения остаточной пропускной способности
" равны значениям пропускной способности.
For Each node In Nodes id1 = node.Id
For Each link In node.Links
If link.Node1 Is node Then
Set to_node = link.Node2
Else
Set to_node = link.Node1
End If id2 = to_node.Id
Residual(id1, id2) = link.Capacity
Next link
Next node
" Повторять до тех пор, пока больше
" не найдется расширяющих путей.
Do
" Найти расширяющий путь в остаточной сети.
" Сбросить значения NodeStatus и InLink всех узлов.
For Each node In Nodes node.NodeStatus = NOT_IN_LIST
Set node.InLink = Nothing
Next node
" Начать с пустого списка возможных узлов.
Set candidates = New Collection
" Поместить источник в список возможных узлов. candidates.Add SourceNode
SourceNode.NodeStatus = NOW_IN_LIST
" Продолжать, пока список возможных узлов не опустеет.
Do While candidates.Count > 0
Set node = candidates(1) candidates.Remove 1 node.NodeStatus = WAS_IN_LIST id1 = node.Id
" Проверить выходящие из узла связи.
For Each link In node.Links
If link.Node1 Is node Then
Set to_node = link.Node2
Else
Set to_node = link.Node1
End If id2 = to_node.Id
" Проверить, что residual > 0, и этот узел
" никогда не был в списке.
If Residual(id1, id2) > 0 And _ to_node.NodeStatus = NOT_IN_LIST _
Then
" Добавить узел в список. candidates.Add to_node to_node.NodeStatus = NOW_IN_LIST
Set to_node.InLink = link
End If
Next link
" Остановиться, если помечен узел-сток.
If Not (SinkNode.InLink Is Nothing) Then _
Exit Do
Loop
" Остановиться, если расширяющий путь не найден.
If SinkNode.InLink Is Nothing Then Exit Do
" Найти наименьшую остаточную пропускную способность
" вдоль расширяющего пути. min_residual = INFINITY
Set node = SinkNode
Do
If node Is SourceNode Then Exit Do id2 = node.Id
Set link = node.InLink
If link.Node1 Is node Then
Set from_node = link.Node2
Else
Set from_node = link.Node1
End If id1 = from_node.Id
If min_residual > Residual(id1, id2) Then _ min_residual = Residual(id1, id2)
Set node = from_node
Loop
" Обновить остаточные пропускные способности,
" используя расширяющий путь.
Set node = SinkNode
Do
If node Is SourceNode Then Exit Do id2 = node.Id
Set link = node.InLink
If link.Node1 Is node Then
Set from_node = link.Node2
Else
Set from_node = link.Node1
End If id1 = from_node.Id
Residual(id1, id2) = Residual(id1, id2) _
- min_residual
Residual(id2, id1) = Residual(id2, id1) _
+ min_residual
Set node = from_node
Loop
Loop " Повторять, пока больше не останется расширяющих путей.
" Вычислить потоки в остаточной сети.
For Each link In Links id1 = link.Node1.Id id2 = link.Node2.Id
If link.Capacity > Residual(id1, id2) Then link.Flow = link.Capacity - Residual(id1, id2)
Else
" Отрицательные значения соответствуют
" обратному направлению движения. link.Flow = Residual(id2, id1) - link.Capacity
End If
Next link
" Найти полный поток.
TotalFlow = 0
For Each link In SourceNode.Links
TotalFlow = TotalFlow + Abs(link.Flow)
Next link
End Sub
=======348-350
Программа Flow использует метод поиска расширяющего пути для нахождения максимального потока в сети. Она похожа на остальные программы в этой главе. Если вы не добавляете или не удаляете узел или связь, вы можете выбрать источник при помощи левой кнопки мыши, а затем выбрать сток при помощи правой кнопки мыши. После выбора источника и стока программа вычисляет и выводит на экран максимальный поток. На рис. 12.26 показано окно программы, на котором изображены потоки в небольшой сети.
Приложения максимального потока
Вычисления максимального потока используются во многих приложениях. Хотя для многих сетей может быть важно знать максимальный поток, этот метод часто используется для получения результатов, которые на первый взгляд имеют отдаленное отношение к пропускной способности сети.
Непересекающиеся пути
Большие сети связи должны обладать избыточностью (redundancy). Для заданной
сети, например такой, как на рис. 12.27, может потребоваться найти число
непересекающихся путей из источника к стоку. При этом, если между двумя
узлами сети есть множество непересекающихся путей, все связи в которых
различны, то соединение между этими узлами останется, даже если несколько
связей в сети будут разорваны.
Можно определить число различных путей, используя метод вычисления
максимального потока. Создадим сеть с узлами и связями, соответствующими
узлам и связям в коммуникационной сети. Присвоим каждой связи единичную
пропускную способность.
@Рис. 12.26. Программа Flow
=====351
@Рис. 12.27. Сеть коммуникаций
Затем вычислим максимальный поток в сети. Максимальный поток будет равен
числу различных путей от источника к стоку. Так как каждая связь может
нести единичный поток, то ни один из путей, использованных при вычислении
максимального потока, не может иметь общей связи.
При более строгом определении избыточности можно потребовать, чтобы
различные пути не имели ни общих связей, ни общих узлов. Немного изменив
предыдущую сеть, можно использовать вычисление максимального потока для
решения и этой задачи.
Разделим каждый узел за исключением источника и стока на два узла,
соединенных связью единичной пропускной способности. Соединим первый из
полученных узлов со всеми связями, входящими в исходный узел. Все связи,
выходящие из исходного узла, присоединим ко второму полученному после
разбиения узлу. На рис. 12.28 показана сеть с рис. 12.27, узлы на которой
разбиты таким образом. Теперь найдем максимальный поток для этой сети.
Если путь, использованный для вычисления максимального потока, проходит
через узел, то он может использовать связь, которая соединяет два
получившихся после разбиения узла. Так как эта связь имеет единичную
пропускную способность, никакие два пути, полученные при вычислении
максимального потока, не могут пройти по этой связи между узлами, поэтому в
исходной сети никакие два пути не могут использовать один и тот же узел.
@Рис. 12.28. Коммуникационная сеть после преобразования
======352
@Рис. 12.29. Сеть распределения работы
Распределение работы
Предположим, что имеется группа сотрудников, каждый из которых обладает
определенными навыками. Предположим также, что существует ряд заданий,
которые требуют привлечения сотрудника, обладающего заданным набором
навыков. Задача распределения работы (work assignment) состоит в том, чтобы
распределить работу между сотрудниками так, чтобы каждое задание выполнял
сотрудник, имеющий соответствующие навыки.
Чтобы свести эту задачу к вычислению максимального потока, создадим сеть с
двумя столбцами узлов. Каждый узел в левом столбце представляет одного
сотрудника. Каждый узел в правом столбце представляет одно задание.
Затем сравним навыки каждого сотрудника с навыками, необходимыми для
выполнения каждого из заданий. Создадим связь между каждым сотрудником и
каждым заданием, которое он способен выполнить, и присвоим всем связям
единичную пропускную способность.
Создадим узел-источник и соединим его с каждым из сотрудников связью
единичной пропускной способности. Затем создадим узел-сток и соединим с ним
каждое задание, снова при помощи связей с единичной пропускной
способностью. На рис. 12.29 показана соответствующая сеть для задачи
распределения работы с четырьмя сотрудниками и четырьмя заданиями.
Теперь найдем максимальный поток из источника в сток. Каждая единица потока
должна пройти через один узел сотрудника и один узел задания. Этот поток
представляет распределение работы для этого сотрудника.
@Рис. 12.30. Программа Work
=======353
Если сотрудники обладают соответствующими навыками для выполнения всех
заданий, то вычисления максимального потока распределят их все. Если
невозможно выполнить все задания, то в процессе вычисления максимального
потока работа будет распределена так, чтобы было выполнено максимально
возможное число заданий.
Программа Work использует этот алгоритм для распределения работы между
сотрудниками. Введите фамилии сотрудников и их навыки в текстовом поле
слева, а задания, которые требуется выполнить и требующиеся для них навыки
в текстовом поле посередине. После того, как вы нажмете на кнопку Go
(Начать), программа распределит работу между сотрудниками, используя для
этого сеть максимального потока. На рис. 12.30 показано окно программы с
полученным распределением работы.
Резюме
Некоторые сетевые алгоритмы можно применить непосредственно к сетеподобным
объектам. Например, можно использовать алгоритм поиска кратчайшего маршрута
для нахождения наилучшего пути в уличной сети. Для определения наименьшей
стоимости построения сети связи или соединения городов железными дорогами
можно использовать минимальное остовное дерево.
Многие другие сетевые алгоритм находят менее очевидные применения.
Например, можно использовать алгоритмы поиска кратчайшего маршрута для
разбиения на районы, составления плана работ методом кратчайшего пути, или
графика коллективной работы. Алгоритмы вычисления максимального потока
можно использовать для распределения работы. Эти менее очевидные применения
сетевых алгоритмов обычно оказываются более интересными и перспективными.
======354
Глава 13. Объектно-ориентированные методы
Использование функций и подпрограмм позволяет программисту разбить код
большой программы на части. Массивы и определенные пользователем типы
данных позволяют сгруппировать элементы данных так, чтобы упросить работу с
ними.
Классы, которые впервые появились в 4-й версии Visual Basic, позволяют
программисту по-новому сгруппировать данные и логику работы программы.
Класс позволяет объединить в одном объекте данные и методы работы с ними.
Этот новый подход к управлению сложностью программ позволяет взглянуть на
алгоритмы с другой точки зрения.
В этой главе рассматриваются вопросы объектно-ориентированного
программирования, возникающие при применении классов Visual Basic. В ней
описаны преимущества объектно-ориентированного программирования (ООП) и
показано, какую выгоду можно получить от их применения в программах на
языке Visual Basic. Затем в главе рассматривается набор полезных объектно-
ориентированных примеров, которые вы можете использовать для управления
сложностью ваших приложений.
Преимущества ООП
К традиционным преимуществам объектно-ориентированного программирования
относятся инкапсуляция или скрытие (encapsulation), полиморфизм
(polymorphism) и повторное использование (reuse). Реализация их в классах
Visual Basic несколько отличается от того, как они реализованы в других
объектно-ориентированных языках. В следующих разделах рассматриваются эти
преимущества ООП и то, как можно ими воспользоваться в программах на Visual
Basic.
Инкапсуляция
Объект, определенный при помощи класса, заключает в себе данные, которые он
содержит. Другие части программы могут использовать объект для оперирования
его данными, не зная о том, как хранятся или изменяются значения данных.
Объект предоставляет открытые (public) процедуры, функции, и процедуры
изменения свойств, которые позволяют программе косвенно манипулировать или
просматривать данные. Так как при этом данные являются абстрактными с точки
зрения программы, это также называется абстракцией данных (data
abstraction).
Инкапсуляция позволяет программе использовать объекты как «черные ящики».
Программа может использовать открытые методы объекта для проверки и
изменения значений без необходимости разбираться в том, что происходит
внутри черного ящика.
=========355
Поскольку действия внутри объектов скрыты от основной программы, реализация
объекта может меняться без изменения основной программы. Изменения в
свойствах объекта происходят только в модуле класса.
Например, предположим, что имеется класс FileDownload, который скачивает
файлы из Internet. Программа сообщает классу FileDownload положение
объекта, а объект возвращает строку с содержимым файла. В этом случае
программе не требуется знать, каким образом объект производит загрузку
файла. Он может скачивать файл, используя модемное соединение или
соединение по выделенной линии, или даже извлекать файл из кэша на
локальном диске. Программа знает только, что объект возвращает строку после
того, как ему передается ссылка на файл.
Обеспечение инкапсуляции
Для обеспечения инкапсуляции класс должен предотвращать непосредственный
доступ к своим данным. Если переменная в классе объявлена как открытая, то
другие части программы смогут напрямую изменять и считывать данные из нее.
Если позднее представление данных изменится, то любые части программы,
которые непосредственно взаимодействуют с данными, также должны будут
измениться. При этом теряется преимущество инкапсуляции.
Чтобы обеспечить доступ к данным, класс должен использовать процедуры для
работы со свойствами. Например, следующие процедуры позволяют другим частям
программы просматривать и изменять значение DegreesF объекта Temperature.
Private m_DegreesF As Single " Градусы Фаренгейта.
Public Property Get DegreesF() As Single
DegreesF = m_DegreesF
End Property
Public Property Let DegreesF(new_DegreesF As Single) m_DegreesF = new_DegreesF
End Property
Различия между этими процедурами и определением m_DegreesF как открытой переменной пока невелики. Тем не менее, использование этих процедур позволяет легко изменять класс в дальнейшем. Например, предположим, что вы решите измерять температуру в градусах Кельвина, а не Фаренгейта. При этом можно изменить класс, не затрагивая остальных частей программы, в которых используются процедуры свойства DegreesF. Можно также добавить код для проверки ошибок, чтобы убедиться, что программа не попытается передать объекту недопустимые значения.
Private m_DegreesK As Single " Градусы Кельвина.
Public Property Get DegreesF() As Single
DegreesF = (m_DegreesK - 273.15) * 1.8
End Property
Public Property Let DegreesF(ByVal new_DegreesF As Single)
Dim new_value As Single
new_value = (new_DegreesF / 1.8) + 273.15
If new_value < 0 Then
" Сообщить об ошибке - недопустимое значении.
Error.Raise 380, "Temperature", _
"Температура должна быть неотрицательной."
Else m_DegreesK = new_value
End If
End Property
======357
Программы, описанные в этом материале, безобразно нарушают принцип
инкапсуляции, используя в классах открытые переменные. Это не слишком
хороший стиль программирования, но так сделано по трем причинами.
Во-первых, непосредственное изменение значений данных выполняется быстрее,
чем вызов процедур свойств. Большинство программ уже и так несколько теряют
в производительности из-за использования ссылок на объекты вместо
применения более сложного метода псевдоуказателей. Применения процедур
свойств еще сильнее замедлит их работу.
Во-вторых, многие программы демонстрируют методы работы со структурами
данных. Например, сетевые алгоритмы, описанные в 12 главе, непосредственно
используют данные объекта. Указатели, которые связывают узлы в сети друг с
другом, составляют неотъемлемую часть алгоритмов. Было бы бессмысленно
менять способ хранения этих указателей.
И, наконец, благодаря использованию открытых значений данных, код
становится проще. Это позволяет вам сконцентрироваться на алгоритмах, и
этому не мешают лишние процедуры работы со свойствами.
Полиморфизм
Второе преимущество объектно-ориентированного программирования — это
полиморфизм (polymorphism), что означает «имеющий множество форм». В Visual
Basic это означает, что один объект может иметь различный формы в
зависимости от ситуации. Например, следующий код представляет собой
подпрограмму, которая может принимать в качестве параметра любой объект.
Объект obj может быть формой, элементом управления, или объектом
определенного вами класса.
Private Sub ShowName(obj As Object)
MsgBox TypeName(obj)
End Sub
Полиморфизм позволяет создавать процедуры, которые могут работать буквально со всеми типами объектов. Но за эту гибкость приходится платить. Если определить обобщенный (generic) объект, как в этом примере, то Visual Basic не сможет определить, какие типы действий сможет выполнять объект, до запуска программы.
========357
Если Visual Basic заранее знает, с объектом какого типа он будет иметь
дело, он может выполнить предварительные действия для того, чтобы более
эффективно использовать объект. Если используется обобщенный (generic)
объект, то программа не может выполнить подготовки, и в результате этого
потеряет в производительности.
Программа Generic демонстрирует разницу в производительности между
объявлением объектов как принадлежащих к определенному типу или как
обобщенных объектов. Тест выполняется одинаково, за исключением того, что в
одном из случаев объект определяется, как имеющий тип Object, а не тип
SpecificClass. При этом установка значения данных объекта с использованием
обобщенного объекта выполняется в 200 раз медленнее.
Private Sub TestSpecific()
Const REPS = 1000000 " Выполнить миллион повторений.
Dim obj As SpecificClass
Dim i As Long
Dim start_time As Single
Dim stop_time As Single
Set obj = New SpecificClass start_time = Timer
For i = 1 To REPS obj.Value = I
Next i stop_time = Timer
SpecificLabel.Caption = _
Format$(1000 * (stop_time - start_time) / REPS, "0.0000")
End Sub
Зарезервированное слово Implements
В 5-й версии Visual Basic зарезервированное слово Implements (Реализует)
позволяет программе использовать полиморфизм без использования обобщенных
объектов. Например, программа может определить интерфейс Vehicle (Средство
передвижения), Если классы Car (Автомобиль) и Truck (Грузовик) оба
реализуют интерфейс Vehicle, то программа может использовать для выполнения
функций интерфейса Vehicle объекты любого из двух классов.
Создадим вначале класс интерфейса, в котором определим открытые переменные,
которые он будет поддерживать. В нем также должны быть определены прототипы
открытых процедур для всех методов, которые он будет поддерживать.
Например, следующий код демонстрирует, как класс Vehicle может определить
переменную Speed (Скорость) и метод Drive (Вести машину):
Public Speed Long
Public Sub Drive()
End Sub
=======358
Теперь создадим класс, который реализует интерфейс. После оператора Option
Explicit в секции Declares добавляется оператор Implements определяющий имя
класса интерфейса. Этот класс должен также определять все необходимые для
работы локальные переменные.
Класс Car реализует интерфейс Vehicle. Следующий код демонстрирует, как в
нем определяется интерфейс и закрытая (private) переменная m_Speed:
Option Explicit
Implements Vehicle
Private m_Speed As Long
Когда к классу добавляется оператор Implements, Visual Basic считывает
интерфейс, определенный указанным классом, а затем создает соответствующие
заглушки в коде класса. В этом примере Visual Basic добавит новую секцию
Vehicle в исходный код класса Car, и определит процедуры let и get свойства
Vehicle_Speed для представления переменной Speed, определенной в интерфейсе
Vehicle. В процедуре let Visual Basic использует переменную RHS, которая
является сокращением от Right Hand Side (С правой стороны), в которой
задается новое значение переменной.
Также определяется процедура Vehicle_Drive. Чтобы реализовать функции этих
процедур, нужно написать код для них. Следующий код демонстрирует, как
класс Car может определять процедуры Speed и Drive.
Private Property Let Vehicle_Speed(ByVal RHS As Long) m_Speed = RHS
End Property
Private Property Get Vehicle_Speed() As Long
Vehicle_Speed = m_Speed
End Property
Private Sub Get Vehicle_Drive()
" Выполнить какие-то действия.
:
End Property
После того, как интерфейс определен и реализован в одном или нескольких
классах, программа может полиморфно использовать элементы в этих классах.
Например, допустим, что программа определила классы Car и Track, которые
оба реализуют интерфейс Vehicle. Следующий код демонстрирует, как программа
может проинициализировать значения переменной Speed для объекта Car и
объекта Truck.
Dim obj As Vehicle
Set obj = New Car obj.Speed = 55
Set obj = New Truck obj .Speed =45
==========359
Ссылка obj может указывать либо на объект Car, либо на объект Truck. Так
как в обоих этих объектах реализован интерфейс Vehicle, то программа может
оперировать свойством obj.Speed независимо от того, указывает ли ссылка obj
на Car или Truck.
Так как ссылка obj указывает на объект, который реализует интерфейс
Vehicle, то Visual Basic знает, что этот объект имеет процедуры, работающие
со свойством Speed. Это означает, что он может выполнять вызовы процедур
свойства Speed более эффективно, чем это было бы в случае, если бы obj была
ссылкой на обобщенный объект.
Программа Implem является доработанной версией программы описанной выше
программы Generic. Она сравнивает скорость установки значений с
использованием обобщенных объектов, определенных объектов и объектов,
которые реализуют интерфейс. В одном из тестов на компьютере с процессором
Pentium с тактовой частотой 166 МГц, программе потребовалось 0,0007 секунды
для установки значений при использовании определенного типа объекта. Для
установки значений при использовании объекта, реализующего интерфейс,
потребовалось 0,0028 секунды (в 4 раза больше). Для установки значений при
использовании обобщенного объекта потребовалось 0,0508 секунды (в 72 раза
больше). Использование интерфейса является не таким быстрым, как
использование ссылки на определенный объект, но намного быстрее, чем
использование обобщенных объектов.
Наследование и повторное использование
Процедуры и функции поддерживают повторное использование (reuse). Вместо
того, чтобы каждый раз писать код заново, можно поместить его в
подпрограмму, тогда вместо блока кода можно просто подставить вызов
подпрограммы.
Аналогично, определение процедуры в классе делает ее доступной во всей
программе. Программа может использовать эту процедуру, используя объект,
который является экземпляром класса.
В среде программистов, использующих объектно-ориентированный подход, под
повторным использованием обычно подразумевается нечто большее, а именно
наследование (inheritance). В объектно-ориентированных языках, таких как
C++ или Delphi, один класс может порождать (derive) другой. При этом второй
класс наследует (inherits) всю функциональность первого класса. После этого
можно добавлять, изменять или убирать какие-либо функции из класса-
наследника. Это также является формой повторного использования кода,
поскольку при этом программисту не нужно заново реализовать функции
родительского класса, для того, чтобы использовать их в классе-наследнике.
Хотя Visual Basic и не поддерживает наследование непосредственно, можно
добиться примерно тех же результатов, используя ограничение (containment)
или делегирование (delegation). При делегировании объект из одного класса
содержит экземпляр класса из другого объекта, и затем передает часть своих
обязанностей заключенному в нем объекту.
Например, предположим, что имеется класс Employee, который представляет
данные о сотрудниках, такие как фамилия, идентификационный номер в системе
социального страхования и зарплата. Предположим, что нам теперь нужен класс
Manager, который делает то же самое, что и класс Employee, но имеет еще
одно свойство secretary (секретарь).
Для использования делегирования, класс Manager должен включать в себя
закрытый объект типа Employee с именем m_Employee. Вместо прямого
вычисления значений, процедуры работы со свойствами фамилии, номера
социального страхования и зарплаты передают соответствующие вызовы объекту
m_Employee. Следующий код демонстрирует, как класс Manager может
оперировать процедурами свойства name (фамилия):
==========360
Private m_Employee As New Employee
Property Get Name() As String
Name = m_Employee.Name
End Property
Property Let Name (New_Name As String) m_Employee.Name = New_Name
End Property
Класс Manager также может изменять результат, возвращаемый делегированной функцией, или выдавать результат сама. Например, в следующем коде показано, как класс Employee возвращает строку текста с данными о сотруднике.
Public Function TextValues() As String
Dim txt As String
txt = m_Name & vbCrLf txt = txt & " " & m_SSN & vbCrLf txt = txt & " " & Format$(m_Salary, "Currency") & vbCrLf
TextValues = txt
End Function
Класс Manager использует функцию TextValues объекта Employee, но добавляет перед возвратом информацию о секретаре в строку результата.
Public Function TextValues() As String
Dim txt As String txt = m_Employee.TextValues txt = txt & " " & m_Secretary & vbCrLf
TextValues = txt
End Function
Программа Inherit демонстрирует классы Employee и Manager. Интерфейс программы не представляет интереса, но ее код включает простые определения классов Employee и Manager.
Парадигмы ООП
В первой главе мы дали определение алгоритма как «последовательности инструкций для выполнения какого-либо задания». Несомненно, класс может использовать алгоритмы в своих процедурах и функциях. Например, можно использовать класс для упаковки в него алгоритма. Некоторые из программ, описанных в предыдущих главах, используют классы для инкапсуляции сложных алгоритмов.
=========361
Классы также позволяют использовать новый стиль программирования, при
котором несколько объектов могут работать совместно для выполнения задачи.
В этом случае может быть бессмысленным задание последовательности
инструкций для выполнения задачи. Более адекватным может быть задание
модели поведения объектов, чем сведение задачи к последовательности шагов.
Для того чтобы отличать такое поведение от традиционных алгоритмов, мы
назовем их «парадигмами».
Следующие раздела описывают некоторые полезные объектно-ориентированные
парадигмы. Многие из них ведут начало из других объектно-ориентированных
языков, таких как C++ или Smalltalk, хотя они могут также использоваться в
Visual Basic.
Управляющие объекты
Управляющие объекты (command) также называются объектами действия (action
objects), функций (function objects) или функторами (functors). Управляющий
объект представляет какое-либо действие. Программа может использовать метод
Execute (Выполнить) для выполнения объектом этого действия. Программе не
нужно знать ничего об этом действии, она знает только, что объект имеет
метод Execute.
Управляющие объекты могут иметь множество интересных применений. Программа
может использовать управляющий объект для реализации:
. Настраиваемых элементов интерфейса;
. Макрокоманд;
. Ведения и восстановления записей;
. Функций «отмена» и «повтор».
Чтобы создать настраиваемый интерфейс, форма может содержать управляющий
массив кнопок. Во время выполнения программы форма может загрузить надписи
на кнопках и создать соответствующий набор управляющих объектов. Когда
пользователь нажимает на кнопку, обработчику событий кнопки нужно всего
лишь вызвать метод Execute соответствующего управляющего объекта. Детали
происходящего находятся внутри класса управляющего объекта, а не в
обработчике событий.
Программа Command1 использует управляющие объекты для создания
настраиваемого интерфейса для нескольких не связанных между собой функций.
При нажатии на кнопку программа вызывает метод Execute соответствующего
управляющего объекта.
Программа может использовать управляющие объекты для создания определенных
пользователем макрокоманд. Пользователь задает последовательность действий,
которые программа запоминает в коллекции в виде управляющих объектов. Когда
затем пользователь вызывает макрокоманду, программа вызывает методы Execute
объектов, которые находятся в коллекции.
Управляющие объекты могут обеспечивать ведение и восстановление записей.
Управляющий объект может при каждом своем вызове записывать информацию о
себе в лог-файл. Если программа аварийно завершит работы, она может затем
использовать записанную информацию для восстановления управляющих объектов
и выполнения их для повторения последовательности команд, которая
выполнялась до сбоя программы.
И, наконец, программа может использовать набор управляющих объектов для
реализации функций отмены (undo) и повтора (redo).
=========362
Программа использует переменную LastCmd для отслеживания последнего
управляющего объекта в коллекции. Если вы выбираете команду Undo (Отменить)
в меню Draw (Рисовать), то программа уменьшает значение переменной LastCmd
на единицу. Когда программа потом выводит рисунок, она вызывает только
объекты, стоящие до объекта с номером LastCmd.
Если вы выбираете команду Redo (Повторить) в меню Draw, то программа
увеличивает значение переменной LastCmd на единицу. Когда программа выводит
рисунок, она выводит на один объект больше, чем раньше, поэтому
отображается восстановленный рисунок.
При добавлении новой фигуры программа удаляет любые команды из коллекции,
которые лежат после позиции LastCmd,. затем добавляет новую команду
рисования в конце и запрещает команду Redo, так как нет команд, которые
можно было бы отменить. На рис. 13.1 показано окно программы Command2 после
добавления новой фигуры.
Контролирующий объект
Контролирующий объект (visitor object) проверяет все элементы в составном
объекте (aggregate object). Процедура, реализованная в составном классе,
обходит все объекты, передавая каждый из них контролирующему объекту в
качестве параметра.
Например, предположим, что составной объект хранит элементы в связном
списке. Следующий код показывает, как его метод Visit обходит список,
передавая каждый объект в качестве параметра методу Visit контролирующего
объекта ListVisitor:
Public Sub Visit(obj As ListVisitor)
Dim cell As ListCell
Set cell = TopCell
Do While Not (cell Is Nothing) obj.Visit cell
Set cell = cell.NextCell
Loop
End Sub
@Рис. 13.1. Программа Command2
=========363
Следующий код демонстрирует, как класс ListVisitor может выводить на экран значения элементов в окне Immediate (Срочно).
Public Sub Visit(cell As ListCell)
Debug.Print cell.Value
End Sub
Используя парадигму контролирующего объекта, составной класс определяет
порядок, в котором обходятся элементы. Составной класс может определять
несколько методов для обхода содержащих его элементов. Например, класс
дерева может обеспечивать методы VisitPreorder (Прямой обход),
VisitPostorder (Обратный обход), VisitInorder (Симметричный обход) и
VisitBreadthFirst (Обход в глубину) для обхода элементов в различном
порядке.
Итератор
Итератор обеспечивает другой метод обхода элементов в составном объекте.
Объект-итератор обращается к составному объекту для обхода его элементов, и
в этом случае итератор определяет порядок, в котором проверяются элементы.
С составным классом могут быть сопоставлены несколько классов итераторов
для того, чтобы выполнять различные обходы элементов составного класса.
Чтобы выполнить обход элементов, итератор должен представлять порядок, в
котором элементы записаны, чтобы определить порядок их обхода. Если
составной класс представляет собой связный список, то объект-итератор
должен знать, что элементы находятся в связном списке, и должен уметь
перемещаться по списку. Так как итератору известны детали внутреннего
устройства списка, это нарушает скрытие данных составного объекта.
Вместо того чтобы каждый класс, которому нужно проверять элементы
составного класса, реализовал обход самостоятельно, можно сопоставить
составному классу класс итератора. Класс итератора должен содержать простые
процедуры MoveFirst (Переместиться в начало), MoveNext (Переместиться на
следующий элемент), EndOfList (Переместиться в конец списка) и CurrentItem
(Текущий элемент) для обеспечения косвенного доступа к списку. Новые классы
могут включать в себя экземпляр класса итератора и использовать его методы
для обхода элементов составного класса. На рис. 13.2 схематически показано,
как новый объект использует объект-итератор для связи со списком.
Программа IterTree, описанная ниже, использует итераторы для обхода полного
двоичного дерева. Класс Traverser (Обходчик) содержит ссылку на объект-
итератор. Они использует обеспечиваемые итератором процедуры MoveFirst,
MoveNext, CurrentCaption и EndOfTree для получения списка узлов в дереве.
@Рис. 13.2. Использование итератора для косвенной связи со списком
=========364
Итераторы нарушают скрытие соответствующих им составных объектов, в отличие
от новых классов, которые содержат итераторы. Для того, чтобы избавиться от
потенциальной путаницы, можно рассматривать итератор как надстройку над
составным объектом.
Контролирующие объекты и итераторы обеспечивают выполнение похожих функций,
используя различные подходы. Так как парадигма контролирующего объекта
оставляет детали составного объекта скрытыми внутри него, она обеспечивает
лучшую инкапсуляцию. Итераторы могут быть полезны, если порядок обхода
может часто изменяться или он должен переопределяться во время выполнения
программы. Например, составной объект может использовать методы
порождающего класса (который описан позднее) для создания объекта-итератора
в процессе выполнения программы. Содержащий итератор класс не должен знать,
как создается итератор, он всего лишь использует методы итератора для
доступа к элементам составного объекта.
Дружественный класс
Многие классы тесно работают с другими. Например, класс итератора тесно
взаимодействует с составным классом. Для выполнения работы, итератор должен
нарушать скрытие составного класса. При этом, хотя эти связанные классы
иногда должны нарушать скрытие данных друг друга, другие классы должны не
иметь такой возможности.
Дружественный класс (friend class) — это класс, имеющий специальное
разрешение нарушать скрытие данных для другого класса. Например, класс
итератора является дружественным классом для соответствующего составного
класса. Ему, в отличие от других классов, разрешено нарушать скрытие данных
для составного класса.
В 5-й версии Visual Basic появилось зарезервированное слово Friend для
разрешения ограниченного доступа к переменным и процедурам, определенным
внутри модуля. Элементы, определенные при помощи зарезервированного слова
Friend, доступны внутри проекта, но не в других проектах. Например,
предположим, что вы создали классы LinkedList (Связный список) и
ListIterator (Итератор списка) в проекте ActiveX сервера. Программа может
создать сервер связного списка для управления связными списками.
Порождающий метод класса LinkedList может создавать объекты типа
ListIterator для использования в программе.
Класс LinkedList может обеспечивать в программе средства для работы со
связными списками. Этот класс объявляет свои свойства и методы открытыми,
чтобы их можно было использовать в основной программе. Класс ListIterator
позволяет программе выполнять итерации над объектами, которыми управляет
класс LinkeList. Процедуры, используемые классом ListIterator для
оперирования объектами LinkedList, объявляются как дружественные в модуле
LinkedList. Если классы LinkedList и ListIterator создаются в одном и том
же проекте, то класс ListIterator может использовать эти дружественные
процедуры. Поскольку основная программа находится в другом проекте, она
этого сделать не может.
Этот очень эффективный, но довольно громоздкий метод. Она требует создания
двух проектов, и установки одного сервера ActiveX. Он также не работает в
более ранних версиях Visual Basic.
Наиболее простой альтернативой было бы соглашение о том, что только
дружественные классы могут нарушать скрытие данных друг друга. Если все
разработчики будут придерживаться этого правила, то проектом все еще можно
будет управлять. Тем не менее, искушение обратиться напрямую к данным
класса LinkedList может быть сильным, и всегда существует вероятность, что
кто-нибудь нарушит скрытие данных из-за лени или по неосторожности.
Другая возможность заключается в том, чтобы дружественный объект передавал
себя другому классу в качестве параметра. Передавая себя в качестве
параметра, дружественный класс тем самым показывает, что он является
таковым. Программа Fstacks использует этот метод для реализации стеков.
=======365
При использовании этого метода все еще можно нарушить скрытие данных объекта. Программа может создать объект дружественного класса и использовать его в качестве параметра, чтобы обмануть процедуры другого объекта. Тем не менее, это достаточно громоздкий процесс, и маловероятно, что разработчик сделает так случайно.
Интерфейс
В этой парадигме один из объектов выступает в качестве интерфейса
(interface) между двумя другими. Один объект может использовать свойства и
методы первого объекта для взаимодействия со вторым. Интерфейс иногда также
называется адаптером (adapter), упаковщиком (wrapper), или мостом (bridge).
На рис. 13.3 схематически изображена работа интерфейса.
Интерфейс позволяет двум объектам на его концах изменяться независимо.
Например, если свойства объекта слева на рис. 13.3 изменятся, интерфейс
должен быть изменен, а объект справа — нет.
В этой парадигме процедуры, используемые двумя объектами, поддерживаются
разработчиками, которые отвечают за эти объекты. Разработчик, который
реализует левый объект, также занимается реализацией процедур интерфейса,
которые взаимодействуют с левым объектом.
Фасад
Фасад (Facade) аналогичен интерфейсу, но он обеспечивает простой интерфейс
для сложного объекта или группы объектов. Фасад также иногда называется
упаковщиком (wrapper). На рис. 13.4. показана схема работы фасада.
Разница между фасадом и интерфейсом в основном умозрительная. Основная
задача интерфейса — обеспечение косвенного взаимодействия между объектами,
чтобы они могли развиваться независимо. Основная задача фасада — облегчение
использования каких-то сложных вещей за счет скрытия деталей.
Порождающий объект
Порождающий объект (Factory) — это объект, который создает другие объекты.
Порождающий метод — это процедура или функция, которая создает объект.
Порождающие объекты наиболее полезны, если два класса должны тесно работать
вместе. Например, составной класс может содержать порождающий метод,
который создает итераторы для него. Порождающий метод может
инициализировать итератор таким образом, чтобы он был готов к работе с
экземпляром класса, который его создал.
@Рис. 13.3 Интерфейс
========366
@Рис. 13.4. Фасад
Программа IterTree создает полное двоичное дерево, записанное в массиве.
После нажатия на одну из кнопок, задающих направление обхода, программа
создает объект Traverser (Обходчик). Она также использует один из
порождающих методов дерева для создания соответствующего итератора. Объект
Traverser использует итератор для обхода дерева и вывода списка узлов в
правильном порядке. На рис. 13.5 приведено окно программы IterTree,
показывающее обратный обход дерева.
Единственный объект
Единственный объект (singleton object) — это объект, который существует в
приложении в единственном экземпляре. Например, в Visual Basic определен
класс Printer (Принтер). Он также определяет единственный объект с тем же
названием. Этот объект представляет принтер, выбранный в системе по
умолчанию. Так как в каждый момент времени может быть выбран только один
принтер, то имеет смысл определить объект Printer как единственный объект.
Один из способов создания единственного объекта заключается в использовании
процедуры, работающей со свойствами в модуле BAS. Эта процедура возвращает
ссылку на объект, определенный внутри модуля как закрытый. Для других
частей программы эта процедура выглядит как просто еще один объект.
@Рис. 13.5. Программа IterTree, демонстрирующая обратный обход
=======367
Программа WinList использует этот подход для создания единственного объекта
класса WinListerClass. Объект класса WinListerClass представляет окна в
системе. Так как операционная система одна, то нужен только один объект
класса WinListerClass. Модуль WinList.BAS использует следующий код для
создания единственного объекта с названием WindowLister.
Private m_WindowLister As New WindowListerClass
Property Get WindowLister() As WindowListerClass
Set WindowLister = m_WindowLister
End Property
Единственный объект WindowLister доступен во всем проекте. Следующий код демонстрирует, как основная программа использует свойство WindowList этого объекта для вывода на экран списка окон.
WindowListText.Text = WindowLister.WindowList
Преобразование в последовательную форму
Многие приложения сохраняют объекты и восстанавливают их позднее. Например,
приложение может сохранять копию своих объектов в текстовом файле. При
следующем запуске программы, она считывает это файл и загружает объекты.
Объект может содержать процедуры, которые считывают и записывают его в
файл. Общий подход может заключаться в том, чтобы создать процедуры,
которые сохраняют и восстанавливают данные объекта, используя строку.
Поскольку запись данных объекта в одной строке преобразует объект в
последовательность символов, этот процесс иногда называется преобразованием
в последовательную форму (serialization).
Преобразование объекта в строку обеспечивает большую гибкость основной
программы. При этом она может сохранять и считывать объекты, используя
текстовые файлы, базу данных или область памяти. Она может переслать
представленный таким образом объект по сети или сделать его доступным на
Web-странице. Программа или элемент ActiveX на другом конце может
использовать преобразование объекта в строку для воссоздания объекта.
Программа также может дополнительно обработать строку, например,
зашифровать ее после преобразования объекта в строку и расшифровать перед
обратным преобразованием.
Один из подходов к преобразованию объекта в последовательную форму
заключается в том, чтобы объект записал все свои данные в строку заданного
формата. Например, предположим, что класс Rectangle (Прямоугольник) имеет
свойства X1, Y1, X2 и Y2. Следующий код демонстрирует, как класс может
определять процедуры свойства Serialization:
Property Get Serialization() As String
Serialization = _
Format$(X1) & ";" & Format$(Y1) & ";" & _
Format$(X2) & ";" & Format$(Y2) & ";"
End Property
Property Let Serialization(txt As String)
Dim pos1 As Integer
Dim pos2 As Integer
pos1 = InStr(txt, ";")
X1 = CSng(Left$(txt, pos1 - 1))
pos2 = InStr(pos1 + 1, txt, ";")
Y1 = CSng(Mid$(txt, pos1 + 1, pos2 – pos1 - 1))
pos1 = InStr(pos2 + 1, txt, ";")
X2 = CSng(Mid$(txt, pos2 + 1, pos1 - pos2 - 1))
pos2 = InStr(pos1 + 1, txt, ";")
Y2 = CSng(Mid$(txt, pos1 + 1, pos2 – pos1 - 1))
End Property
Этот метод довольно простой, но не очень гибкий. По мере развития
программы, изменения в структуре объектов могут заставить вас
перетранслировать все сохраненные ранее преобразованные в последовательную
форму объекты. Если они находятся в файлах или базах данных, для загрузки
старых данных и записи их в новом формате может потребоваться написание
программ-конверторов.
Более гибкий подход заключается в том, чтобы сохранять вместе со значениями
элементов данных объекта их имена. Когда объект считывает данные,
преобразованные в последовательную форму, он использует имена элементов для
определения значений, который необходимо установить. Если позднее в
определение элемента будут добавлены какие-либо элементы, или удалены из
него, то не придется преобразовывать старые данные. Если новый объект
загрузит старые данные, то он просто проигнорирует не поддерживаемые более
значения.
Определяя значения данных по умолчанию, иногда можно уменьшить размер
преобразованных в последовательную форму объектов. Процедура get свойства
Serialization сохраняет только значения, которые отличаются от значений по
умолчанию. Перед тем, как процедура let свойства начнет выполнение
преобразования в последовательную форму, она инициализирует все элементы
объекта значениями по умолчанию. Значения, не равные значениям по
умолчанию, обновляются по мере обработки данных процедурой.
Программа Shapes использует этот подход для сохранения и загрузки с диска
рисунков, содержащих эллипсы, линии, и прямоугольники. Объект ShapePicture
представляет весь рисунок целиком. Он содержит коллекцию управляющих
объектов, которые представляют различные фигуры.
Следующий код демонстрирует процедуры свойства Serialization объекта
ShapePicture. Объект ShapePicture сохраняет имя типа для каждого из типов
объектов, а затем в скобках — представление объекта в последовательной
форме.
Property Get Serialization() As String
Dim txt As String
Dim i As Integer
For i = 1 To LastCmd txt = txt & _
TypeName(CmdObjects(i)) & "(" & _
CmdObjects(i).Serialization & ")"
Next I
Serialization = txt
End Property
==========369
Процедура let свойства Serialization использует подпрограмму
GetSerialization для чтения имени объекта и списка данных в скобках.
Например, если объект ShapePicture содержит команду рисования
прямоугольника, то его представление в последовательной форме будет
включать строку “RectangleCMD”, за которой будут следовать данные,
представленные в последовательной форме.
Процедура использует подпрограмму CommandFactory для создания объекта
соответствующего типа, а затем заставляет новый объект преобразовать себя
из последовательной формы представления.
Property Let Serialization(txt As String) Dim pos As Integer Dim token_name
As String Dim token_value As String Dim and As Object
" Start a new picture.
NewPicture
" Read values until there are no more.
GetSerialization txt, pos, token_name, token_value Do While token_name
""
" Make the object and make it unserialize itself.
Set and = ConiniandFactory(token_name)
If Not (and Is Nothing) Then _
and.Serialization = token_value
GetSerialization txt, pos, token_name, tokerL-value Loop
LastCmd = CmdObjects.Count End Property
Парадигма Модель/Вид/Контроллер.
Парадигма Модель/Вид/Контроллер (МВК) (Model/View/Controller) позволяет
программе управлять сложными соотношениями между объектами, которые
сохраняют данные, объектами, которые отображают их на экране, и объектами,
которые оперируют данными. Например, приложение работы с финансами может
выводить данные о расходах в виде таблицы, секторной диаграммы, или
графика. Если пользователь изменяет значение в таблице, приложение должно
автоматически обновить изображение на экране. Может также понадобиться
записать измененные данные на диск.
Для сложных систем управление взаимодействием между объектами, которые
хранят, отображают и оперируют данными, может быть достаточно запутанным.
Парадигма Модель/Вид/Контроллер разбивает взаимодействия, так что можно
работать с ними по отдельности, при этом используются три типа объектов:
модели, виды, и контроллеры.
Модели
Модель (Model) представляет данные, обеспечивая методы, которые другие
объекты могут использовать для проверки и изменения данных. В приложении
работы с финансовыми данными, модель содержит данные о расходах. Она
обеспечивает процедуры для просмотра и изменения значений расходов и ввода
новых значений. Она также может обеспечивать функции для вычисления
суммарных величин, таких как полные издержки, расходы по подразделениям,
средние расходы за месяц, и так далее
Модель включает в себя набор видов, которые отображают данные. При
изменении данных, модель сообщает об этом видам, которые изменяют
изображение на экране соответствующим образом.
Виды
Вид (View) отображает представленные в модели данные. Так как виды обычно
выводят данные для просмотра пользователем, иногда удобнее создавать их,
используя форму, а не класс.
Когда программа создает вид, она должна добавить его к набору видов модели.
Контроллеры
Контроллер (Controller) изменяет данные в модели. Контроллер должен всегда обращаться к данным модели через ее открытые методы. Эти методы могут затем сообщать об изменении видам. Если контроллер изменял бы данные модели непосредственно, то модель не смогла бы сообщить об этом видам.
Виды/Контроллеры
Многие объекты одновременно отображают и изменяют данные. Например,
текстовое поле позволяет пользователю вводить и просматривать данные.
Форма, содержащая текстовое поле, является одновременно и видом, и
контроллером. Переключатели, поля выбора опций, полосы прокрутки, и многие
другие элементы пользовательского интерфейса позволяют одновременно
просматривать и оперировать данными.
Видами/контроллерами проще всего управлять, если попытаться максимально
разделить функции просмотра и управления. Когда объект изменяет данные, он
не должен сам обновлять изображение на экране. Он может сделать это
позднее, когда модель сообщит ему как виду о произошедшем изменении.
Эти методы достаточно громоздки для реализации стандартных объектов
пользовательского интерфейса, таких как текстовые поля. Когда пользователь
вводит значение в текстовом поле, оно немедленно обновляется, и выполнятся
его обработчик события Change. Этот обработчик событий может модель об
изменении. Модель затем сообщает виду/контроллеру (выступающему теперь как
вид) о произошедшем изменении. Если при этом объект обновит текстовое поле,
то произойдет еще одно событие Change, о котором снова будет сообщено
модели и программа войдет в бесконечный цикл.
Чтобы предотвратить эту проблему, методы, изменяющие данные в модели,
должны иметь необязательный параметр, указывающий на контроллер, который
вызвал эти изменения. Если виду/контроллеру требуется сообщить об
изменении, которое он вызывает, он должен передать значение Nothing
процедуре, вносящей изменения. Если этого не требуется, то в качестве
параметра объект должен передавать себя.
=========371
@Рис. 13.6. Программа ExpMVC
Программа ExpMVC, показанная на рис. 13.6, использует парадигму
Модель/Вид/Контроллер для вывода данных о расходах. На рисунке показаны три
вида различных типов. Вид/контроллер TableView отображает данные в таблице,
при этом можно изменять названия статей расходов и их значения в
соответствующих полях.
Вид/контроллер GraphView отображает данные при помощи гистограммы, при этом
можно изменять значения расходов, двигая столбики при помощи мыши вправо.
Вид PieView отображает секторную диаграмму. Это просто вид, поэтому его
нельзя использовать для изменения данных.
Резюме
Классы позволяют программистам на Visual Basic рассматривать старые задачи с новой точки зрения. Вместо того чтобы представлять себе длинную последовательность заданий, которая приводит к выполнению задачи, можно думать о группе объектов, которые работают, совместно выполняя задачу. Если задача правильно разбита на части, то каждый из классов по отдельности может быть очень простым, хотя все вместе они могут выполнять очень сложную функцию. Используя описанные в этой главе парадигмы, вы можете разбить классы так, чтобы каждый из них оказался максимально простым.
==============372
Требования к аппаратному обеспечению
Для запуска и изменения примеров приложений вам понадобится компьютер,
который удовлетворяет требованиям Visual Basic к аппаратному обеспечению.
Алгоритм выполняются с различной скоростью на компьютерах разных
конфигураций. Компьютер с процессором Pentium Pro и 64 Мбайт памяти будет
быстрее компьютера с 386 процессором и 4 Мбайт памяти. Вы быстро узнаете
ограничения вашего оборудования.
Выполнение программ примеров
Один из наиболее полезных способов выполнения программ примеров — запускать
их при помощи встроенных средств отладки Visual Basic. Используя точки
останова, просмотр значений переменных и другие свойства отладчика, вы
можете наблюдать алгоритмы в действии. Это может быть особенно полезно для
понимания наиболее сложных алгоритмов, таких как алгоритмы работы со
сбалансированными деревьями и сетевые алгоритмы, представленные в 7 и 12
главах соответственно.
Некоторые и программ примеров создают файлы данных или временные файлы. Эти
программы помещают такие файлы в соответствующие директории. Например,
некоторые из программ сортировки, представленные в 9 главе, создают файлы
данных в директории SrcCh9/. Все эти файлы имеют расширение “.DAT”,
поэтому вы можете найти и удалить их в случае необходимости.
Программы примеров предназначены только для демонстрационных целей, чтобы
помочь вам понять определенные концепции алгоритмов, и в них не почти не
реализована обработка ошибок или проверка данных. Если вы введете
неправильное решение, программа может аварийно завершить работу. Если вы не
знаете, какие данные допустимы, воспользуйтесь для получения инструкций
меню Help (Помощь) программы.
========374
A
addressing indirect, 49 open, 314 adjacency matrix, 86 aggregate object, 382 ancestor, 139 array irregular, 89 sparse, 92 triangular, 86 augmenting path, 363
B
B+Tree, 12 balanced profit, 222 base case, 101 best case, 27 binary hunt and search, 294 binary search, 286 branch, 139 branch-and-bound technique, 204 bubblesort, 254 bucketsort, 275
C
cells, 47 child, 139 circular referencing problem, 58 collision resolution policy, 299 command, 380 complexity theory, 17 controller, 391 countingsort, 273 critical path, 359 cycle, 331
D
data abstraction, 372 decision tree, 203 delegation, 378 descendant, 139
E
edge, 331 encapsulation, 371 exhaustive search, 204, 282 expected case, 27
F
facade, 386
factorial, 100
factory, 386
fake pointer, 32, 65
fat node, 12, 140
Fibonacci numbers, 105
firehouse problem, 239
First-In-First-Out, 72
forward star, 12, 90, 143
friend class, 384
functors, 380
G
game tree, 204 garbage collection, 43 garbage value, 43 generic, 374 graph, 138, 331 greatest common divisor, 103 greedy algorithms, 339
H
Hamiltonian path, 237
hashing, 298
heap, 266
heapsort, 265
heuristic, 204
Hilbert curves, 108
hill-climbing, 219
I
implements, 375 incremental improvements, 225 inheritance, 378 insertionsort, 251 interface, 385 interpolation search, 288 interpolative hunt and search, 295
K
knapsack problem, 212
L
label correcting, 342
label setting, 342
Last-In-First-Out list, 69
least-cost, 220
linear probing, 314
link, 331
list circular, 56 doubly linked, 58 linked, 36 threaded, 61 unordered, 36, 43
M
mergesort, 263
minimal spanning tree, 338
minimax, 206
model, 391
Model/View/Controller, 390
Monte Carlo search, 223
N
network, 331 capacitated, 361 capacity, 361 connected, 332 directed, 331 flow, 361 residual, 362 node, 139, 331 degree, 139 internal, 139 sibling, 139
O
octtree, 172 optimum global, 230 local, 230
P
page file, 30 parent, 139 partition problem, 236 path, 331 pointers, 32 point-to-point shortest path, 352 polymorphism, 371, 374 primary clustering, 317 priority queue, 268 probe sequence, 300 pruning, 212 pseudo-random probing)., 324
Q
quadratic probing, 322 quadtree, 138, 165 queue, 72 circular, 75 multi-headed, 83 priority, 80 quicksort, 258
R
random search, 223 recursion direct, 99 indirect, 25, 99 multiple, 24 tail recursion, 121 recursive procedure, 23 redundancy, 368 reference counter, 33 rehashing, 327 relatively prime, 103 residual capacity, 362 reuse, 371, 378
S
satisfiability problem, 235
secondary clustering, 324
selectionsort, 248
sentinel, 52
serialization, 388
shortest path, 342
Sierpinski curves, 112
simulated annealing, 231
singleton object, 387
sink, 361
source, 361
spanning tree, 336
stack, 69
subtree, 139
T
tail recursion removal, 121
thrashing, 31
thread, 61
traveling salesman problem, 238
traversal breadth-first, 149 depth-first, 149 inorder, 148 postorder, 148 preorder, 148
tree, 138
AVL tree, 174
B+tree, 192 binary, 140 bottom-up B-trees, 192
B-tree, 187 complete, 147 depth, 140 left rotation, 177 left-right rotation, 178 right rotation, 176 right-left rotation, 178 symmetrically threaded, 160 ternary, 140 threaded, 138 top-down B-tree, 192 traversing, 148
tries, 138
turn penalties, 354
U
unsorting, 250
V
view, 391 virtual memory, 30 visitor object, 382
W
work assignment, 369 worst case, 27
А
Абстракция данных, 372
Адресация косвенная, 49 открытая, 314
Алгоритм поглощающий, 339
Г
Гамильтонов путь, 237
Граф, 138, 331
Д
Делегирование, 378
Деревья, 138
АВЛ-деревья, 174
Б+деревья, 12, 192, 193
Б-деревья, 187 ветвь, 139 внутренний узел, 139 восьмеричные, 172 вращения, 176 двоичные, 140 дочерний узел, 139 игры, 204 квадродеревья, 165 корень, 139 лист, 139 нисходящие Б-деревья, 192 обратный обход, 148 обход, 148 обход в глубину, 149 обход в ширину, 149 поддерево, 139 полные, 147 порядок, 139 потомок, 139 предок, 139 представление нумерацией связей, 12, 143 прямой обход, 148 решений, 203 родитель, 139 с полными узлами, 12 с симметричными ссылками, 160 симметричный обход, 148 троичные, 140 узел, 139 упорядоченные, 153
Дружественный класс, 384
З
Задача коммивояжера, 238 о выполнимости, 235 о пожарных депо, 239 о разбиении, 236 поиска Гамильтонова пути, 237 распределения работы, 369 формирования портфеля, 212
Значение
"мусорное", 43
И
Инкапсуляция, 372
К
Ключи объединение, 244 сжатие, 244
Коллекция, 37
Кратчайший маршрут двухточечный, 352 дерево кратчайшего маршрута, 341 для всех пар, 352, 353 коррекция меток, 342, 348 со штрафами за повороты, 352, 354 установка меток, 342, 344
Кривые
Гильберта, 108
Серпинского, 112
М
Массив нерегулярный, 89 представление в виде прямой звезды, 90 разреженный, 92 треугольный, 86
Матрица смежности, 86
Метод ветвей и границ, 204, 212 восхождения на холм, 219 минимаксный, 206
Монте-Карло, 223 наименьшей стоимости, 220 отжига, 231 полного перебора, 204 последовательных приближений, 225 сбалансированной прибыли, 222 случайного поиска, 223 эвристический, 204
Модель/Вид/Контроллер, 390
Н
Наибольший общий делитель, 103
Наследование, 378
О
Объект вид, 391 единственный, 387 интерфейс, 385 итератор, 383 контролирующий, 382 контроллер, 391 модель, 391 порождающий, 386 преобразование в последовательную форму, 388 составной, 382 управляющий, 380 фасад, 386
Ограничение, 378
Оптимум глобальный, 230 локальный, 230
Очередь, 72 многопоточная, 83 приоритетная, 80, 268 циклическая, 75
П
Память виртуальная, 30 пробуксовка, 31 чистка, 43
Пирамида, 265
Повторное использование, 378
Поиск двоичный, 286 интерполяционный, 288 методом полного перебора, 282 следящий, 294
Полиморфизм, 374
Потоки, 61
Проблема циклических ссылок, 58
Процедура очистки памяти, 45 рекурсивная, 23
Псевдоуказатели, 32, 65
Р
Разрешение конфликтов, 299
Рекурсия восходящая, 175 косвенная, 25, 99 многократная, 24 прямая, 99 условие остановки, 101 хвостовая, 121
С
Сеть, 331 избыточность, 368 источник, 361 кратчайший маршрут, 341 критический путь, 359 нагруженная, 361 наименьшее остовное дерево, 338 ориентированная, 331 остаточная, 362 остаточная пропускная способность, 362 остовное дерево, 336 поток, 361 пропускная способность, 361 простой путь, 332 путь, 331 расширяющий путь, 363 ребро, 331 связная, 332 связь, 331 сток, 361 узел, 331 цена связи, 331 цикл, 331
Сигнальная метка, 52
Системный стек, 26
Случай наилучший, 27 наихудший, 27 ожидаемый, 27
Сортировка блочная, 275 быстрая, 258 вставкой, 251 выбором, 248 пирамидальная, 265 подсчетом, 273 пузырьковая, 254 рандомизация, 250 слиянием, 263
Список двусвязный, 58 многопоточный, 61 неупорядоченный, 36, 43 первый вошел-первый вышел, 72 первый вошел-последний вышел, 69 связный, 36 циклический, 56
Стек, 69
Странный аттрактор, 170
Счетчик ссылок, 33
Т
Теория сложности алгоритмов, 17 хаоса, 170
Тестовая последовательность вторичная кластеризация, 324 квадратичная проверка, 321 линейная проверка, 314 первичная кластеризация, 317 псевдослучайная проверка, 324
У
Указатели, 32, 36
Ф
Файл подкачки, 30
Факториал, 100
Х
Хеширование, 298 блоки, 303 открытая адресация, 314 разрешение конфликтов, 299 рехеширование, 327 связывание, 300 тестовая последовательность, 300 хеш-таблица, 298
Ч
Числа взаимно простые, 103
Фибоначчи, 105
Я
Ячейка, 47
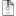 (zip - application/zip)
(zip - application/zip)